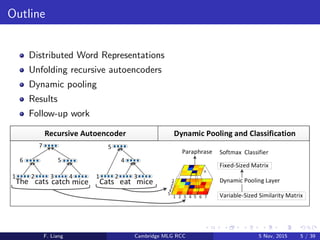
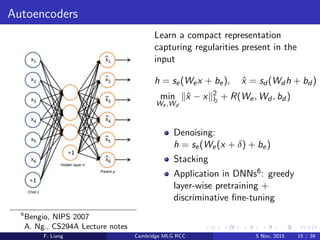
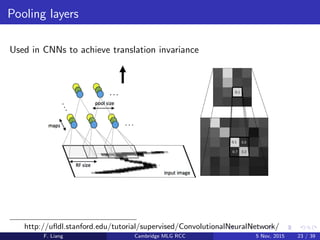
Download to read offline










![Neural-network parameterization of CPD
Number free parameters ∈ O(n + D|V|)
J (θ) = 1
T t [− log P(wt|Le(wt−n+1:t−1), θ)] + R(θ)
Bengio, JMLR 2003
F. Liang Cambridge MLG RCC 5 Nov, 2015 11 / 39](https://image.slidesharecdn.com/socher-rae-2011-151102232924-lva1-app6891/85/Detecting-paraphrases-using-recursive-autoencoders-11-320.jpg)



![Recursive autoencoders for sentence embedding
(RD)∗ → RD: recursively apply RD × RD → RD
yi = f (We[xj ; xk] + b)
f , activation function
Free parameters:
We ∈ RD×2D
, encoding matrix
b ∈ RD
, bias
Anything missing from this definition?
F. Liang Cambridge MLG RCC 5 Nov, 2015 16 / 39](https://image.slidesharecdn.com/socher-rae-2011-151102232924-lva1-app6891/85/Detecting-paraphrases-using-recursive-autoencoders-16-320.jpg)

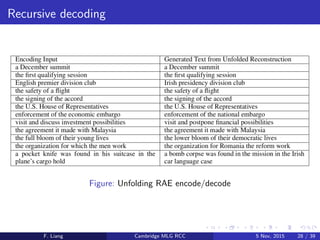
![Training recursive autoencoders
Wd “undoes” We (minimizes square reconstruction error)
To train:
argminWe ,Wd
[x1; y1] − [x1; y1] 2
2
+ R(We, Wd )
Notice anything asymmetrical? (hint: is this even an autoencoder?)
F. Liang Cambridge MLG RCC 5 Nov, 2015 18 / 39](https://image.slidesharecdn.com/socher-rae-2011-151102232924-lva1-app6891/85/Detecting-paraphrases-using-recursive-autoencoders-18-320.jpg)
![Unfolding RAEs
Reconstruction error was only measured against a single decoding step!
Instead, recursively apply Wd to decode down to terminals
argminWe ,Wd
[xi ; . . . ; xj ] − [xi ; . . . ; xj ] 2
2
+ R(We, Wd )
Children with larger subtrees weighted more
DAG =⇒ efficiently optimized via back-propogation through
structure9 and L-BFGS
9
Goller, 1995
F. Liang Cambridge MLG RCC 5 Nov, 2015 19 / 39](https://image.slidesharecdn.com/socher-rae-2011-151102232924-lva1-app6891/85/Detecting-paraphrases-using-recursive-autoencoders-19-320.jpg)

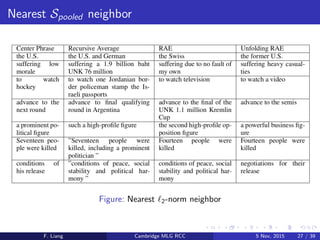
![Measuring sentence similarity
From sentence x1:N and RAE encoding y1:K , form
s = [x1, . . . , xN, y1, . . . , yK ]
For two sentences s1, s2, the similarity matrix S has entries
(S)i,j = (s1)i − (s2)j
2
2
F. Liang Cambridge MLG RCC 5 Nov, 2015 21 / 39](https://image.slidesharecdn.com/socher-rae-2011-151102232924-lva1-app6891/85/Detecting-paraphrases-using-recursive-autoencoders-21-320.jpg)









![Different “semantic norms” on the word vector space
Neural Tensor Networks17
g(e1, R, e2) = uT
R f eT
1 W
[1:k]
R e2 + VR
e1
e2
+ bR
Francesco
Guicciardini
historian male
ItalyFlorence
Francesco
Patrizi
Matteo
Rosselli
profession
gender
place of birth
nationality
location nationality
nationality
gender
17
Socher, NIPS 2013
F. Liang Cambridge MLG RCC 5 Nov, 2015 38 / 39](https://image.slidesharecdn.com/socher-rae-2011-151102232924-lva1-app6891/85/Detecting-paraphrases-using-recursive-autoencoders-38-320.jpg)


This document discusses paraphrase detection using recursive autoencoders within the realm of machine learning, highlighting the methods used to classify whether two sentences are paraphrases. It covers techniques such as distributed word representations, dynamic pooling, and the architectural details of recursive autoencoders for sentence embedding. Additionally, it presents results from experiments on paraphrase detection tasks with notable accuracy rates and outlines future directions for this research area.

















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










