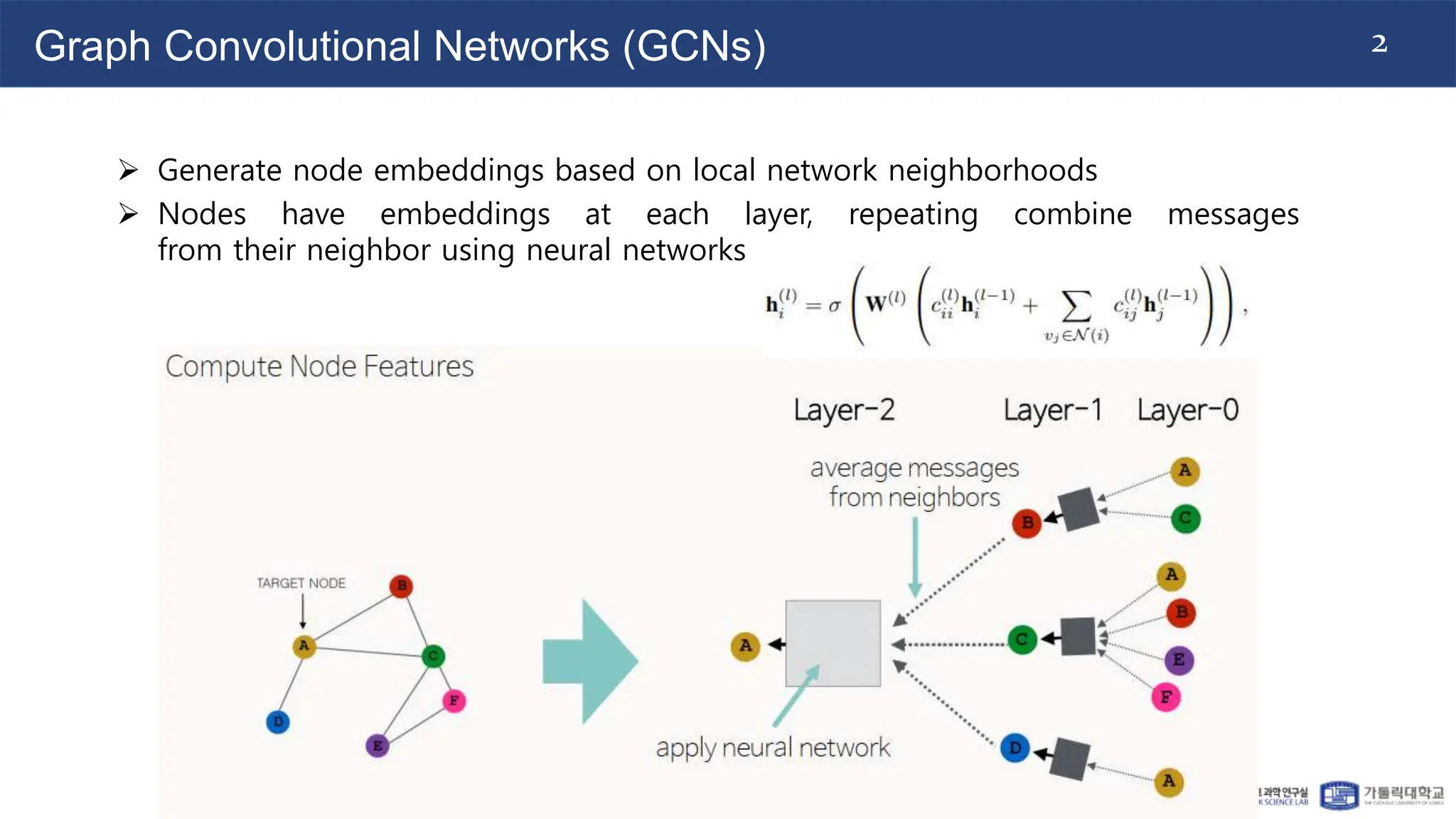
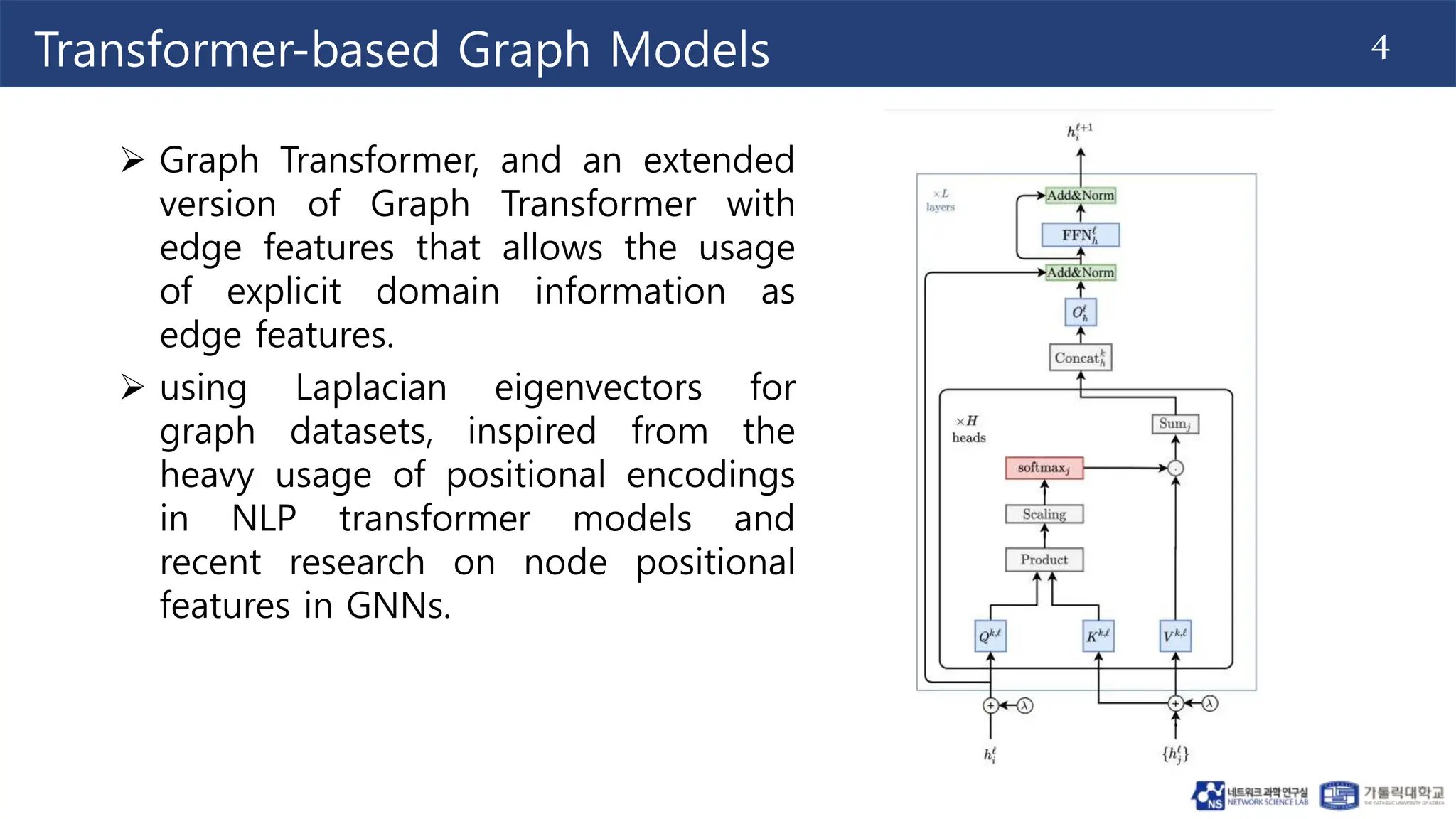
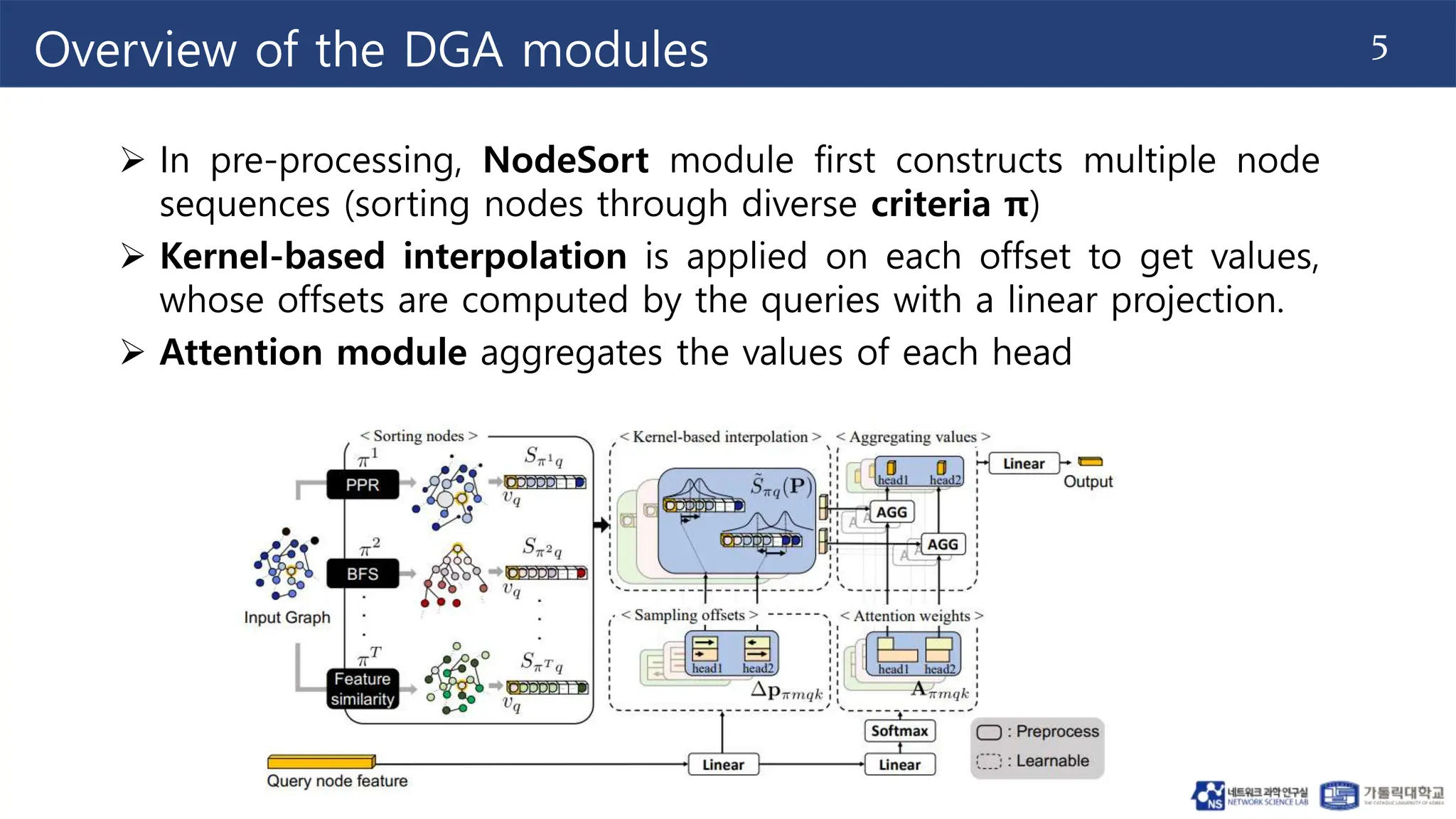
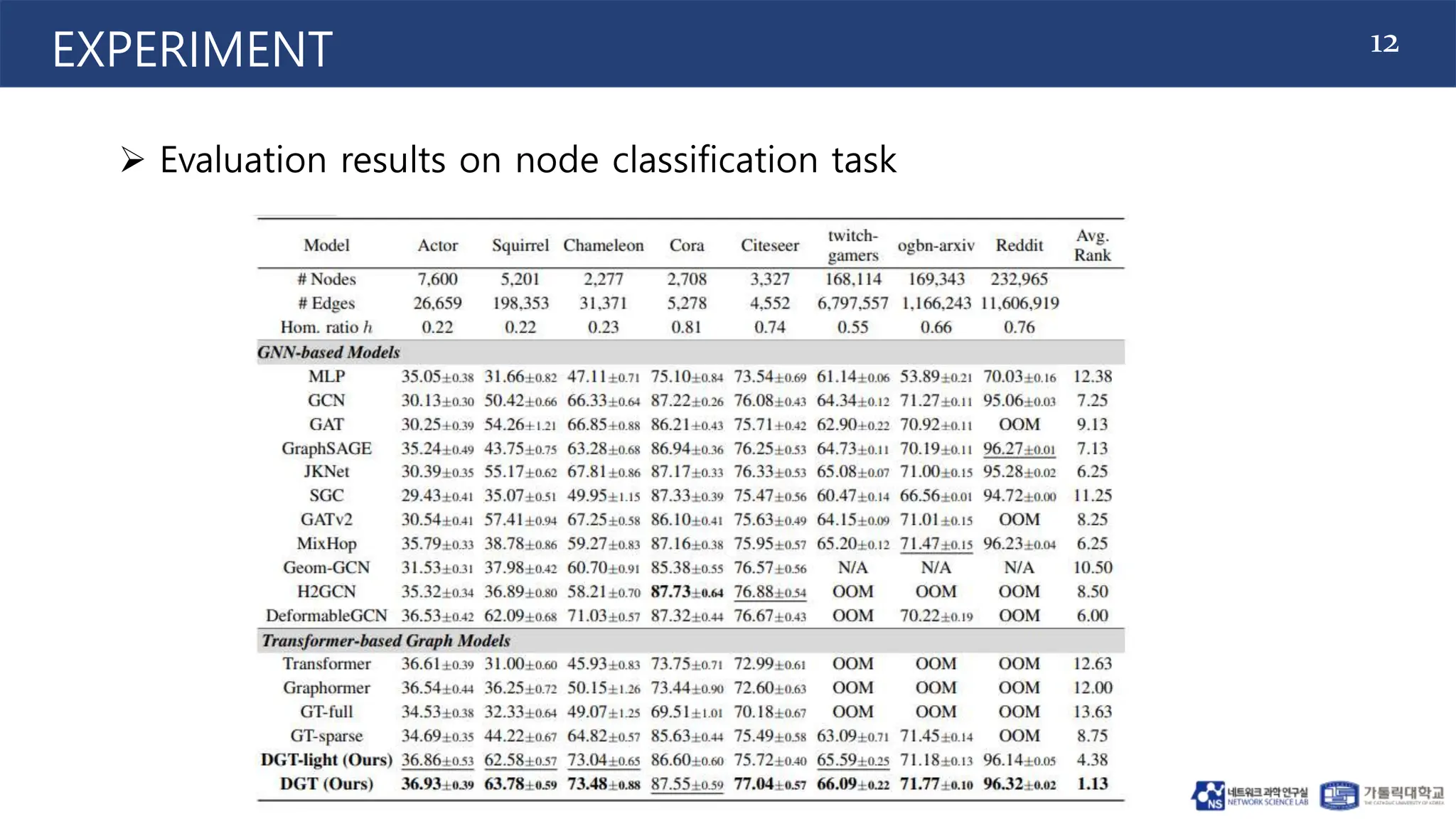
This document proposes the Deformable Graph Transformer (DGT) model, which uses a technique called Deformable Graph Attention (DGA) to perform sparse attention on graphs. DGA flexibly attends to relevant nodes based on their proximity, using multiple sorted node sequences. It also introduces learnable positional encodings called Katz PE that reflect positional information through paths between nodes. The document evaluates DGT on node classification tasks and finds it outperforms other transformer-based graph models while addressing scalability issues.