
Download as PDF, PPTX






![+ Graphormer Layer.
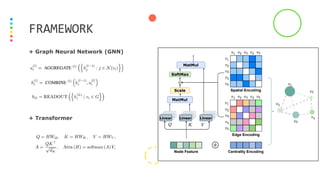
+ Special Node:
- Add a special node called [VNode] to the graph, and make connection between
[VNode] and each node individually.
- [VNode] is connected to all other nodes in graph to represent the sequence-level
feature on downstream tasks.
- The virtual node can aggregate the information of the whole graph (like the
READOUT function) and then propagate it to each node.
DETAILS OF GRAPHORMER](https://image.slidesharecdn.com/sanggraphormer-230324065624-6cce5c6f/85/Sang_Graphormer-pdf-9-320.jpg)

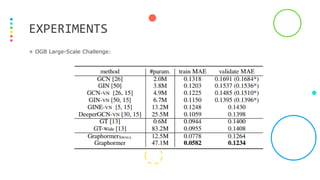


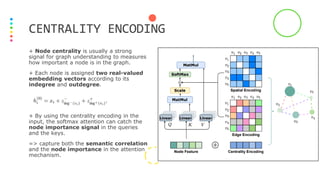
This document presents Graphormer, a Transformer-based model for graph representation learning. Graphormer achieves state-of-the-art performance on graph tasks by introducing three novel encodings: centrality encoding to capture node importance, spatial encoding to encode structural relations between nodes, and edge encoding to incorporate edge features. Experiments show Graphormer outperforms GNN baselines by over 10% on various graph datasets and tasks.


![240304_Thanh_LabSeminar[Pure Transformers are Powerful Graph Learners].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240304thanhlabseminartokengt-240409105926-a93f6988-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NS][Lab_Seminar_240617]A Survey on Graph Neural Networks and Graph Transform...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240617asurvey-240624082546-9e44d3fd-thumbnail.jpg?width=640&height=640&fit=bounds)




























































