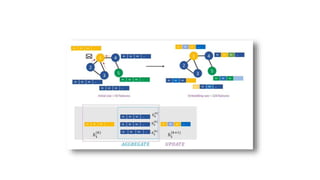
This document provides an overview of graph neural networks for node classification. It discusses supervised graph neural network approaches like graph convolutional networks (GCN) and graph attention networks. It also covers unsupervised approaches like variational graph auto-encoders and deep graph infomax. Additionally, it discusses general frameworks for graph neural networks like neural message passing networks and issues like over-smoothing when GNNs become too deep.






















































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)














