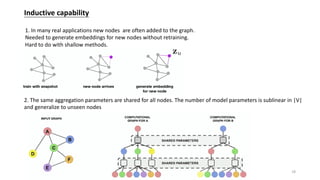
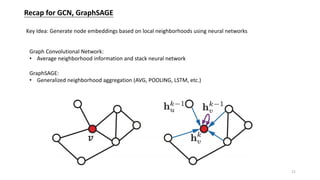
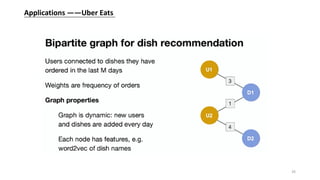
This document provides an overview of graph representation learning and various methods for learning embeddings of nodes in graph-structured data. It introduces shallow methods like DeepWalk and Node2Vec that learn embeddings by generating random walks. It then discusses deep methods like graph convolutional networks (GCN) and GraphSAGE that learn embeddings through neural network aggregation of node neighborhoods. Graph attention networks are also introduced as a learnable aggregator for GCN. Finally, applications of these methods at Pinterest for pin recommendation and at Uber Eats for dish recommendation are briefly described.

![Agenda
- Graph Representation Learning
- Shallow Methods
- Deepwalk[Bryan, 2014 KDD]
- Node2Vec[A Grover, 2016 KDD]
- Deep Methods: GNN
- Graph Convolutional Networks [Kipf., ICLR 2017](GCN)
- GraphSAGE [WL, 2017 NIPS]
- Graph Attention Networks[Veličković, ICLR 2018] (GAT)
- Applications
- Pins recommendation with PinSage by Pinterest
- Dish Recommendation on Uber Eats with GCN
2](https://image.slidesharecdn.com/gnn-overview-200513164343/85/Gnn-overview-2-320.jpg)
![Graph Representation Learning
Node Embedding Graph Embedding
Representation learning is learning representations of input data typically by transforming it or
extracting features from it(by some means), that makes it easier to perform a task like classification
or prediction. [Yoshua Bengio 2014]
Embedding is ALL you need:
word2vec, doc2vec, node2vec, item2vec, struc2vec…
4](https://image.slidesharecdn.com/gnn-overview-200513164343/85/Gnn-overview-4-320.jpg)

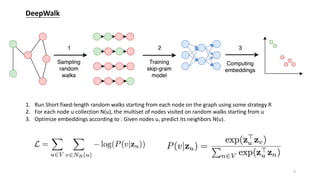
![Shallow Encoding —— an embedding-lookup table
ENC(v)=Zv
Methods: DeepWalk[Perozzi et al. 2014 KDD], Node2vec[Grover et al. 2016 KDD], etc.
7](https://image.slidesharecdn.com/gnn-overview-200513164343/85/Gnn-overview-7-320.jpg)

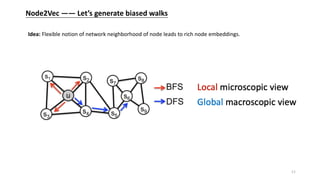


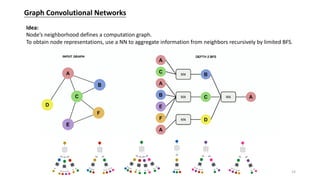

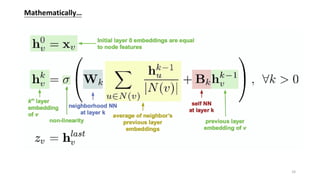



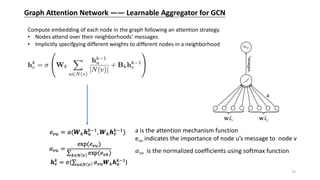
![Graph Attention Network —— Learnable Aggregator for GCN
Idea: Borrow the idea of attention mechanisms and learn to assign different weights to different
neighbors in the aggregation process.
Attention Is All You Need [A Vaswani, 2017 NIPS]
22](https://image.slidesharecdn.com/gnn-overview-200513164343/85/Gnn-overview-22-320.jpg)





















![[기초개념] Graph Convolutional Network (GCN)](https://cdn.slidesharecdn.com/ss_thumbnails/agistdkimgcn190507-190507153736-thumbnail.jpg?width=640&height=640&fit=bounds)














































