Downloaded 98 times





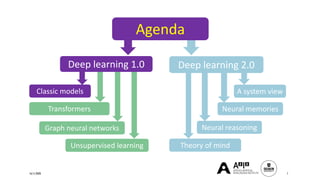
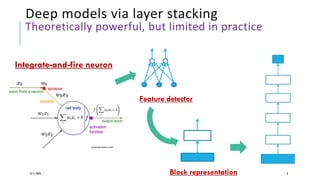
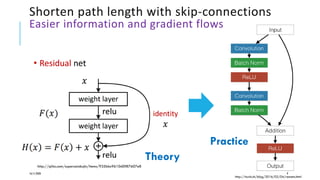
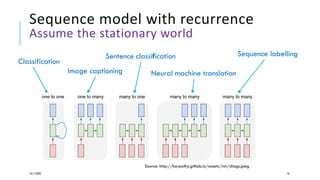
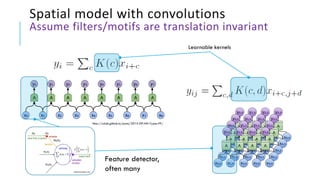



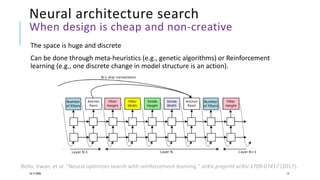
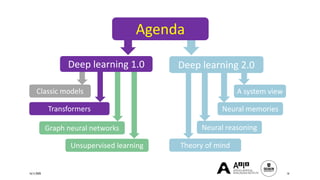

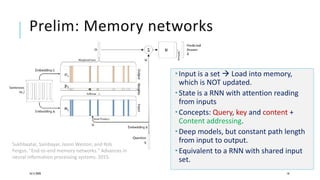
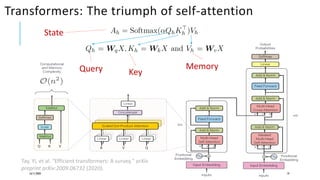


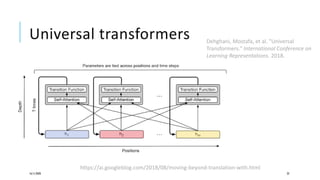
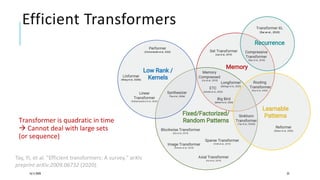
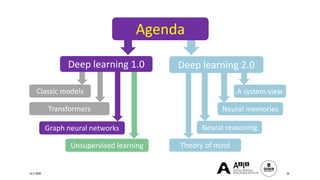

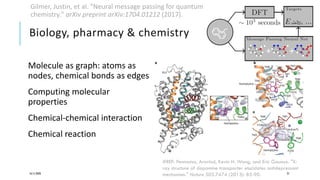
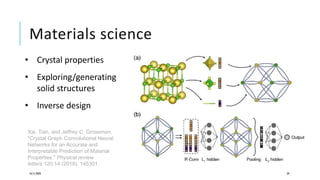
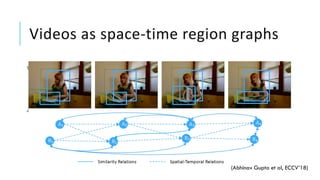
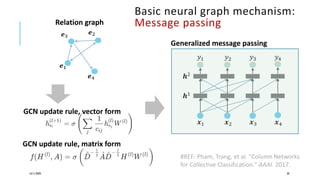

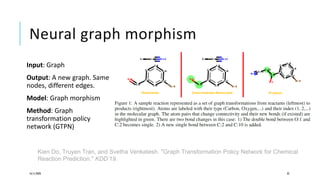
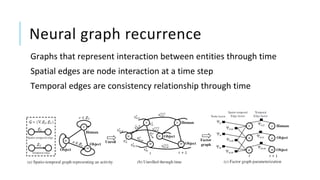
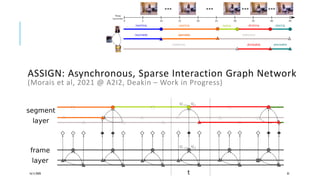


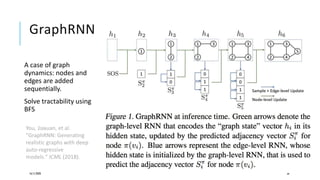
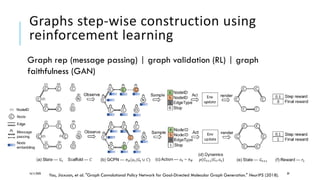
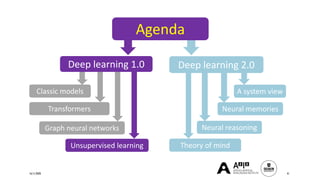


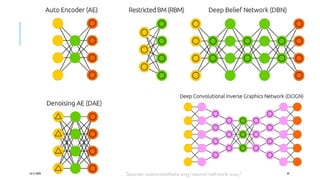


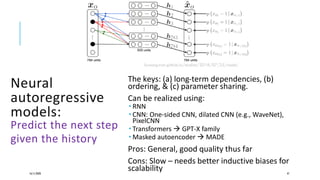

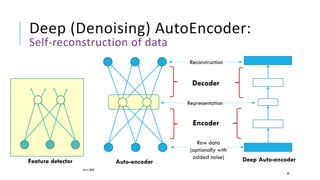
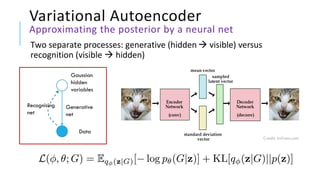

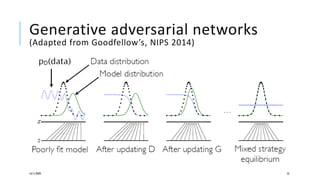

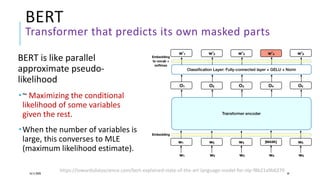
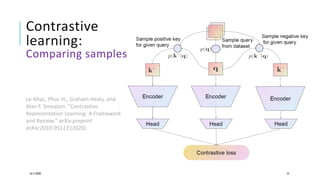



The document presents a comprehensive tutorial on deep learning, addressing its evolution into deep learning 2.0, focusing on various models including transformers and graph neural networks. It explores key concepts such as attention mechanisms, neural architecture search, and unsupervised learning methods, detailing their benefits and applications. Additionally, the tutorial emphasizes the scalability and adaptability of deep learning models across various domains and tasks.












































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)