Download as PDF, PPTX
![Asynchronous Methods for Deep Reinforcement Learning
Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Tim Harley, Timothy P., David Silver, Koray Kavukcuoglu
Google DeepMind
Montreal Institute for Learning Algorithms (MILA), University of Montreal
Journal reference: ICML 2016
Cite as: arXiv:1602.01783 [cs.LG]
(or arXiv:1602.01783v2 [cs.LG] for this version)
資應所 105065702 李思叡
1](https://image.slidesharecdn.com/ppdlpresentationforisa-190317085322/85/Asynchronous-Methods-for-Deep-Reinforcement-Learning-1-320.jpg)











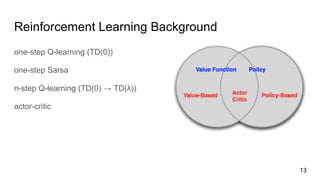



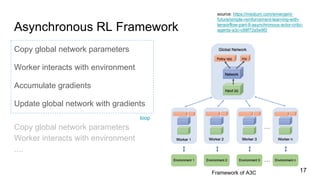




















The document discusses asynchronous methods for deep reinforcement learning, highlighting the limitations of experience replay and proposing a framework that executes multiple agents in parallel across environments. This approach enhances training stability, reduces computational costs, and shows significant performance improvements in various tasks compared to traditional methods. Experimental results demonstrate robust efficiencies and effective training using reduced resources on a single machine.














![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)



![[기초개념] Recurrent Neural Network (RNN) 소개](https://cdn.slidesharecdn.com/ss_thumbnails/agistpurnndkim190430-190430140949-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]AlphaStarとその関連技術](https://cdn.slidesharecdn.com/ss_thumbnails/dlalphastar-190605035416-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IBIS2017 講演] ディープラーニングによる画像変換](https://cdn.slidesharecdn.com/ss_thumbnails/ibis2017iizuka-171120134119-thumbnail.jpg?width=640&height=640&fit=bounds)










































