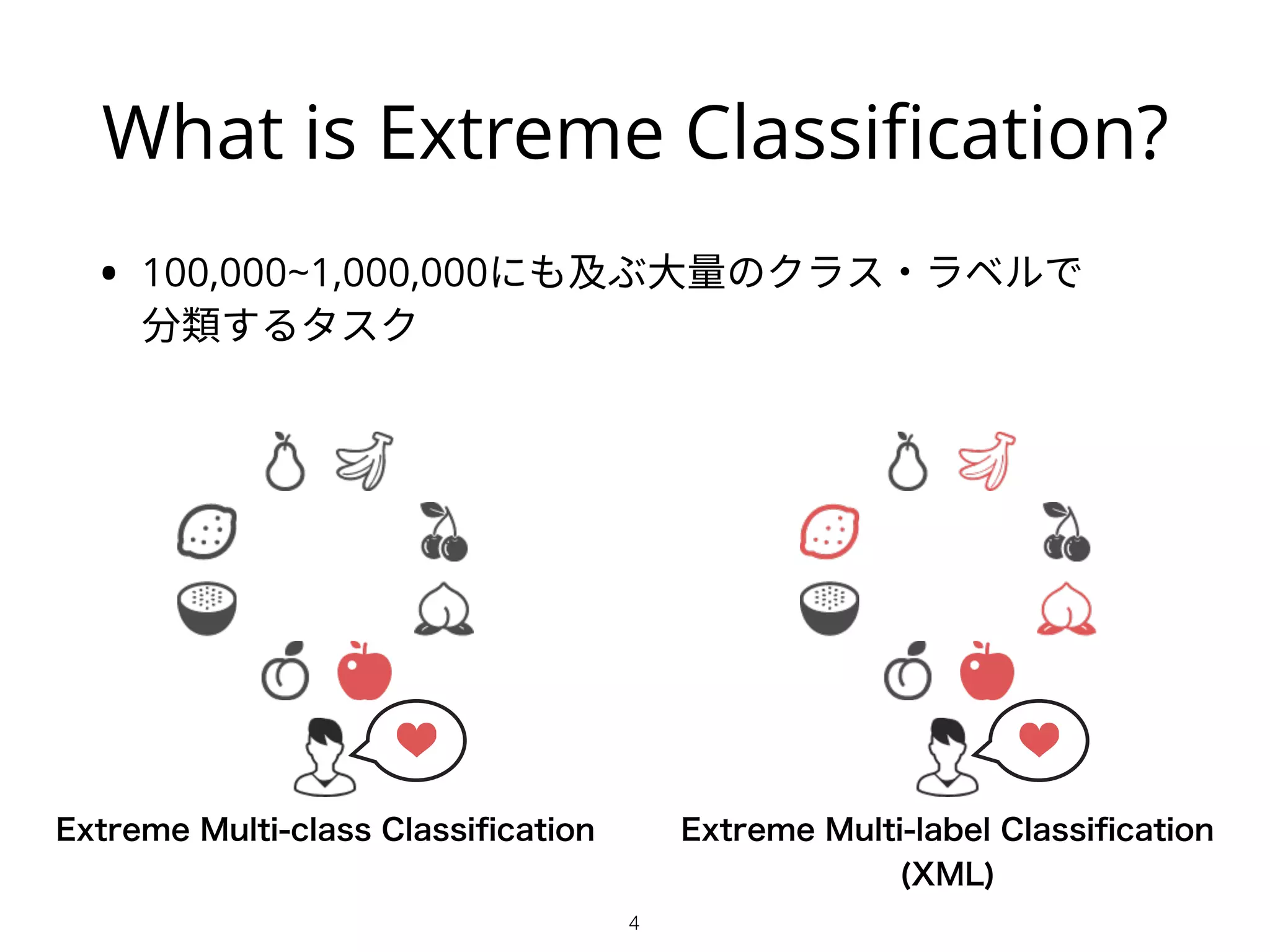
What is ExtremeClassification?
• 100,000~1,000,000にも及ぶ大量のクラス・ラベルで
分類するタスク
!4
5.
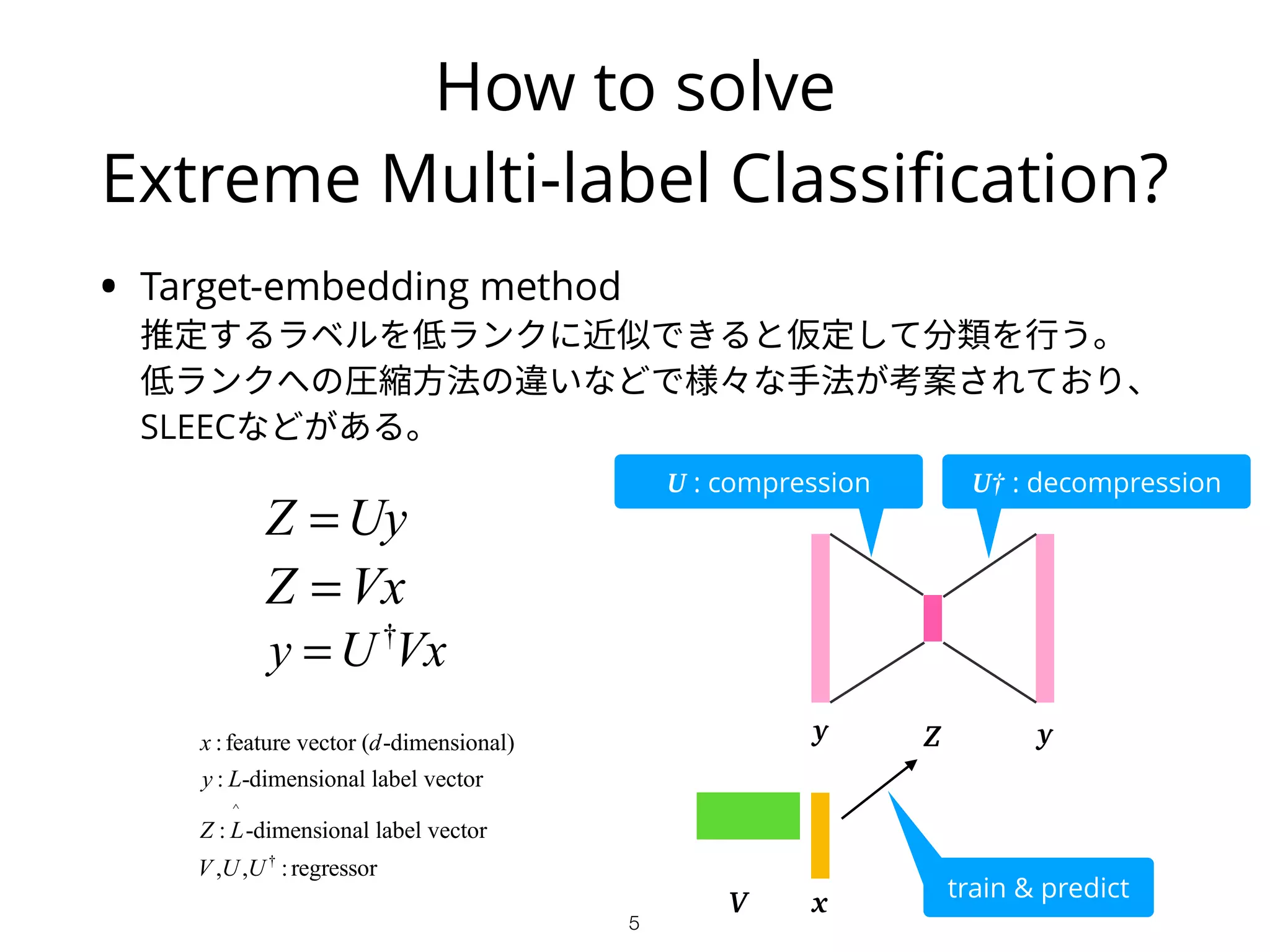
How to solve
ExtremeMulti-label Classification?
• Target-embedding method
推定するラベルを低ランクに近似できると仮定して分類を行う。
低ランクへの圧縮方法の違いなどで様々な手法が考案されており、
SLEECなどがある。
!5
Z = Uy
Z = Vx
y = U†
Vx
U : compression U† : decompression
y Z y
V x
train & predict
x :feature vector (d-dimensional)
y : L-dimensional label vector
Z : L
^
-dimensional label vector
V ,U,U†
:regressor
6.
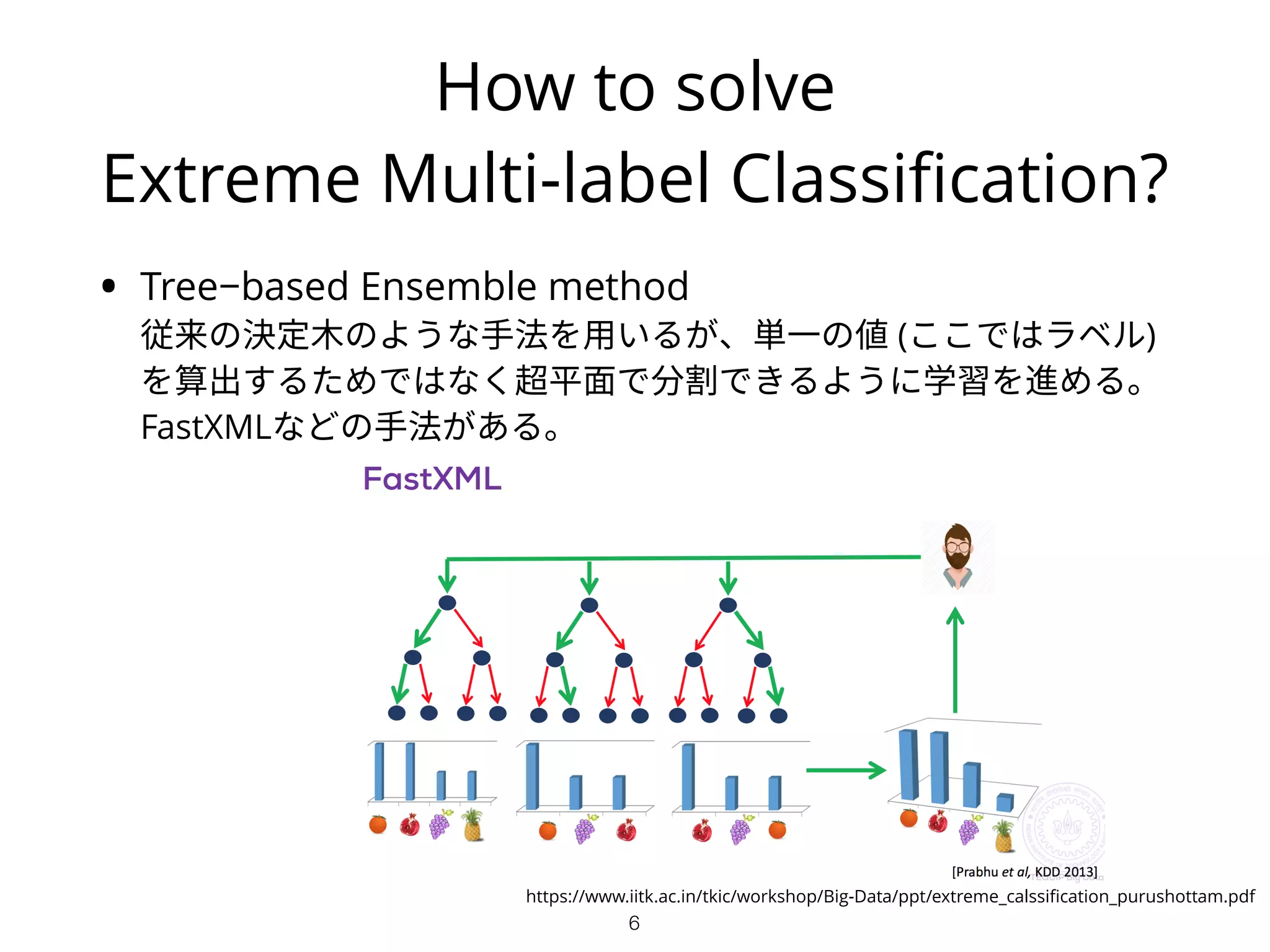
How to solve
ExtremeMulti-label Classification?
• Tree−based Ensemble method
従来の決定木のような手法を用いるが、単一の値 (ここではラベル)
を算出するためではなく超平面で分割できるように学習を進める。
FastXMLなどの手法がある。
!6
https://www.iitk.ac.in/tkic/workshop/Big-Data/ppt/extreme_calssification_purushottam.pdf
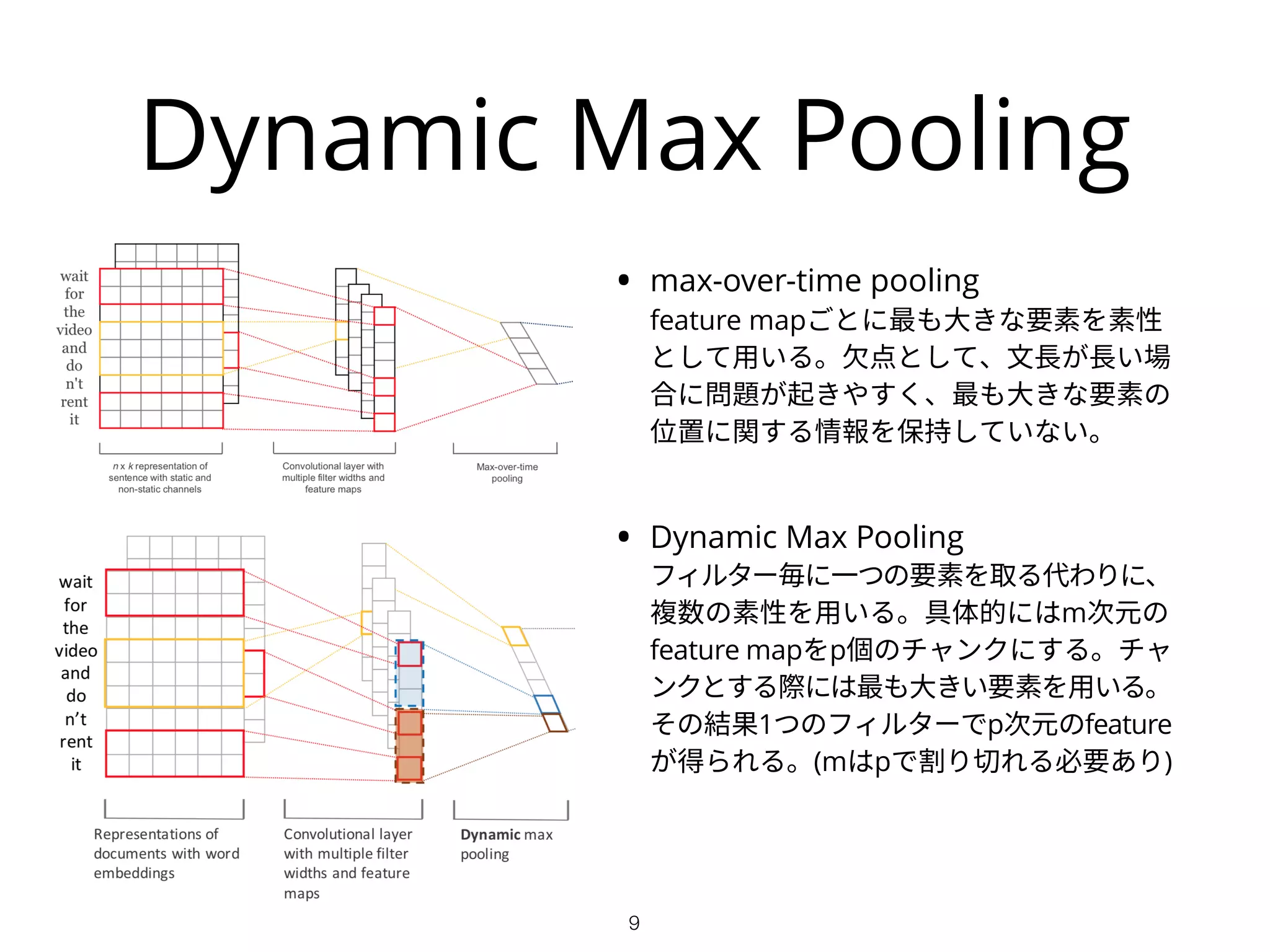
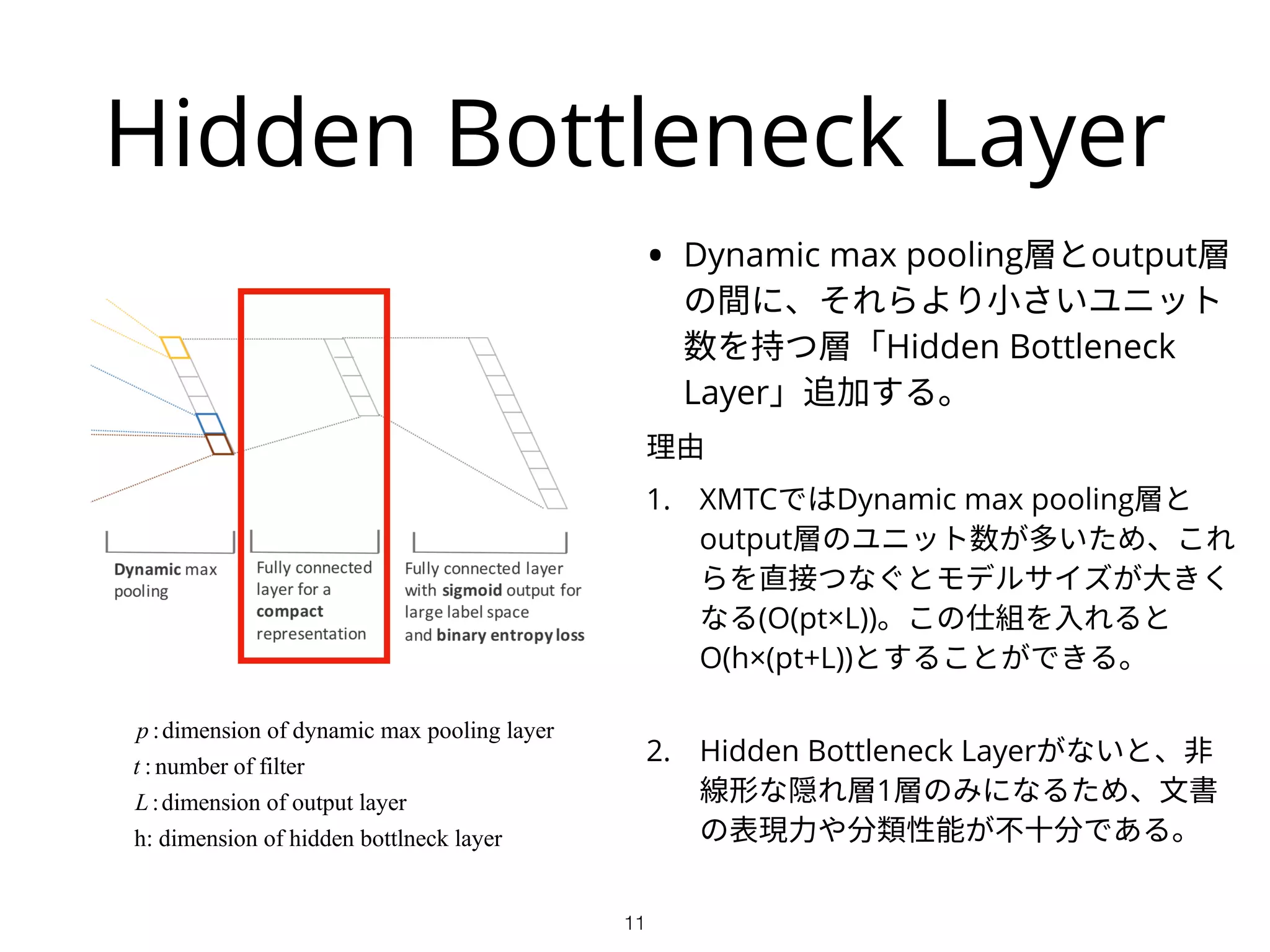
Hidden Bottleneck Layer
•Dynamic max pooling層とoutput層
の間に、それらより小さいユニット
数を持つ層「Hidden Bottleneck
Layer」追加する。
理由
1. XMTCではDynamic max pooling層と
output層のユニット数が多いため、これ
らを直接つなぐとモデルサイズが大きく
なる(O(pt×L))。この仕組を入れると
O(h×(pt+L))とすることができる。
2. Hidden Bottleneck Layerがないと、非
線形な隠れ層1層のみになるため、文書
の表現力や分類性能が不十分である。
!11
p :dimension of dynamic max pooling layer
t : number of filter
L:dimension of output layer
h: dimension of hidden bottlneck layer
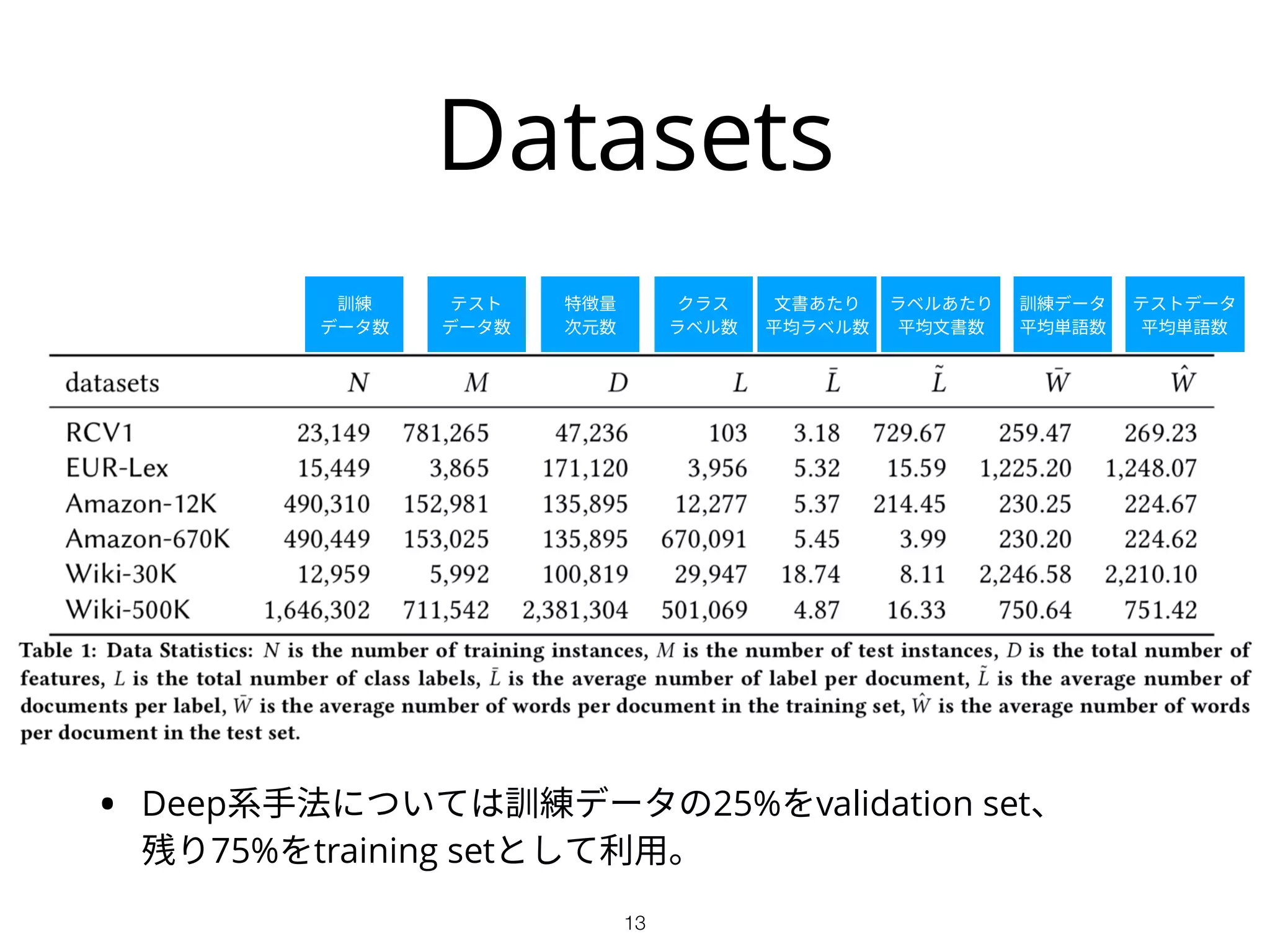
Ablation Test
• keyattributeのそれぞれが性能向上への寄与を確認
• v1 loss function
• v2 loss function + hidden layer
• v3 loss function + hidden layer + max pooling layer (=XML-CNN)
!17
18.
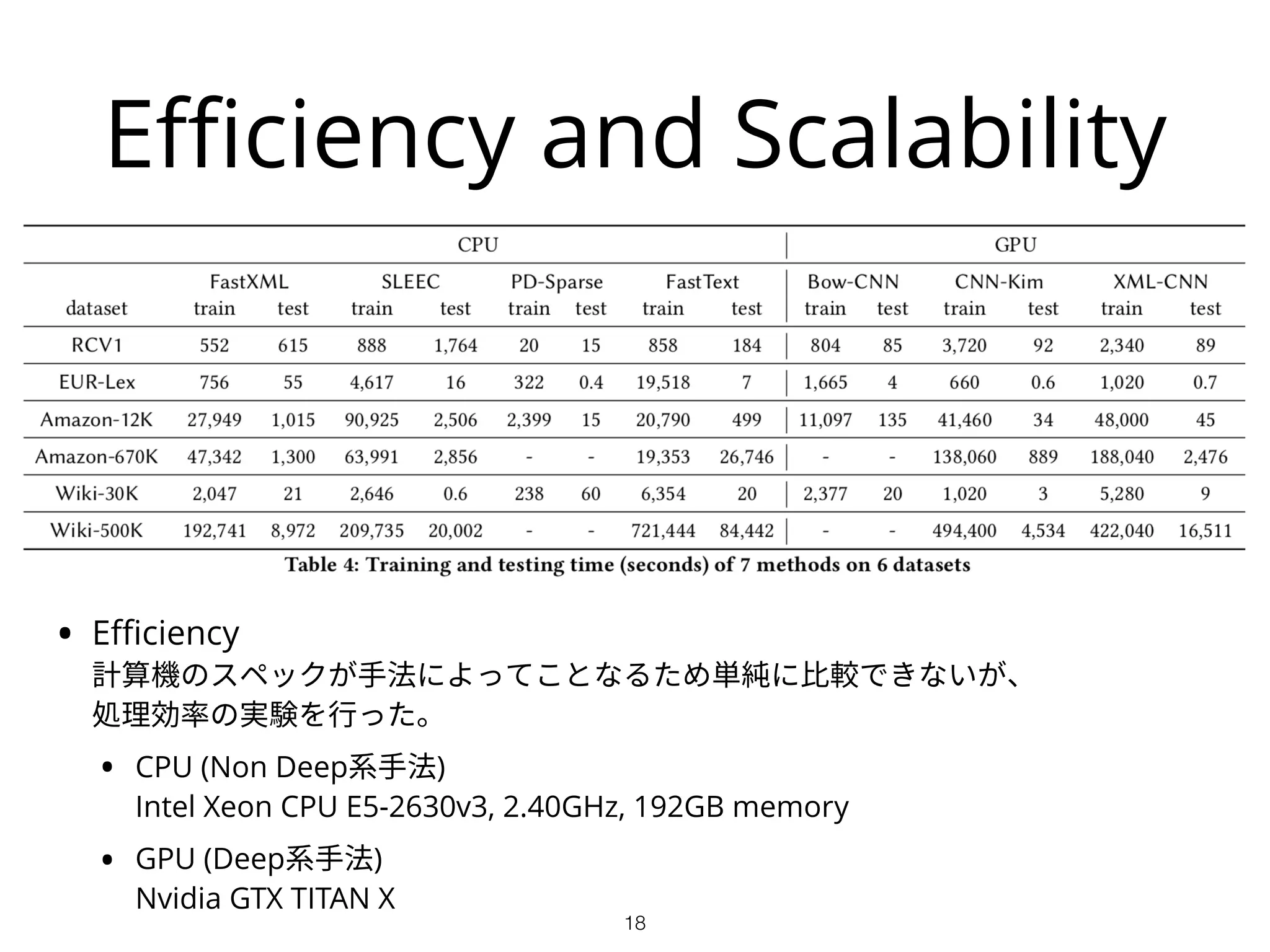
Efficiency and Scalability
•Efficiency
計算機のスペックが手法によってことなるため単純に比較できないが、
処理効率の実験を行った。
• CPU (Non Deep系手法)
Intel Xeon CPU E5-2630v3, 2.40GHz, 192GB memory
• GPU (Deep系手法)
Nvidia GTX TITAN X
!18















![[DL輪読会]Geometric Unsupervised Domain Adaptation for Semantic Segmentation](https://cdn.slidesharecdn.com/ss_thumbnails/20220121gudalin-220121050547-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]A closer look at few shot classification](https://cdn.slidesharecdn.com/ss_thumbnails/acloserlookatfew-shotclassification-190304034759-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]AutoAugment: LearningAugmentation Strategies from Data & Learning Data...](https://cdn.slidesharecdn.com/ss_thumbnails/dlp0712f-190719034120-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DeepLearning論文読み会] Dataset Distillation](https://cdn.slidesharecdn.com/ss_thumbnails/datasetdistillation-181114165952-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...](https://cdn.slidesharecdn.com/ss_thumbnails/181214dlpointnet-181214053349-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)
























