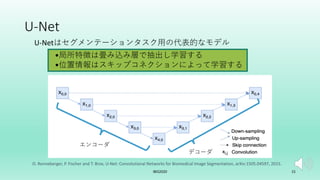
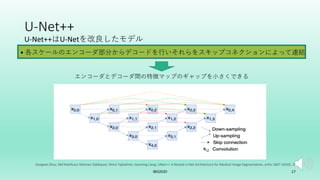
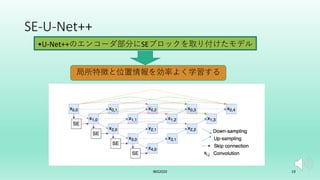
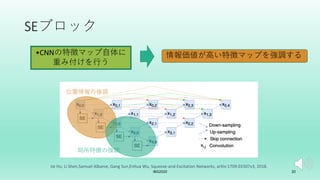
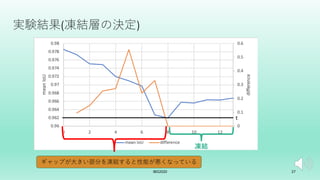
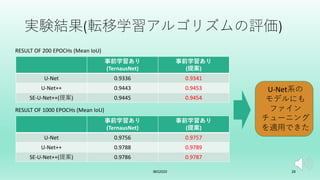
U-Net++を拡張した転移学習モデルを提案した. 画像分類タスクでは局所特徴を学習すれば良いがセグメンテーションタスクはそれに加えて位置情報も学習する必要がある. 故にタスク間の学習すべき特徴に差異が生じる. そこでSEブロックを組み込むことで局所特徴と位置情報の両方を効率よく学習するSE-U-Net++と畳み込み層のパラメータを比較することでタスクの差異を埋める転移学習アルゴリズムを提案した.




















![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators](https://cdn.slidesharecdn.com/ss_thumbnails/stylegan-nada-210813013304-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...](https://cdn.slidesharecdn.com/ss_thumbnails/20210806journalclub-210806023711-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DL輪読会]Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Ob...](https://cdn.slidesharecdn.com/ss_thumbnails/20190726-190725235641-thumbnail.jpg?width=640&height=640&fit=bounds)
