




















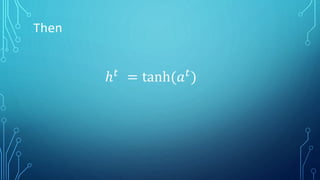




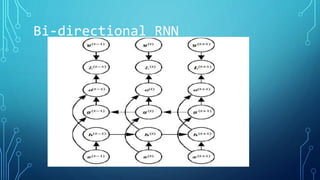
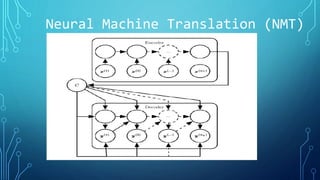

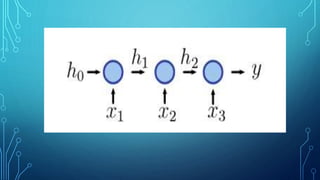

The document discusses deep learning approaches for natural language processing (NLP). It introduces NLP and common applications. Word representations like one-hot and distributed representations are covered, with a focus on Word2Vec models. Recurrent neural networks (RNNs) are described as useful for sequential language data, including variants like bidirectional RNNs and applications such as neural machine translation and sentiment analysis.



































































