Downloaded 72 times
![Day 5
Closing
[course site]](https://image.slidesharecdn.com/dlcvd5closing-160803180548/75/Deep-Learning-for-Computer-Vision-Closing-UPC-2016-1-2048.jpg)







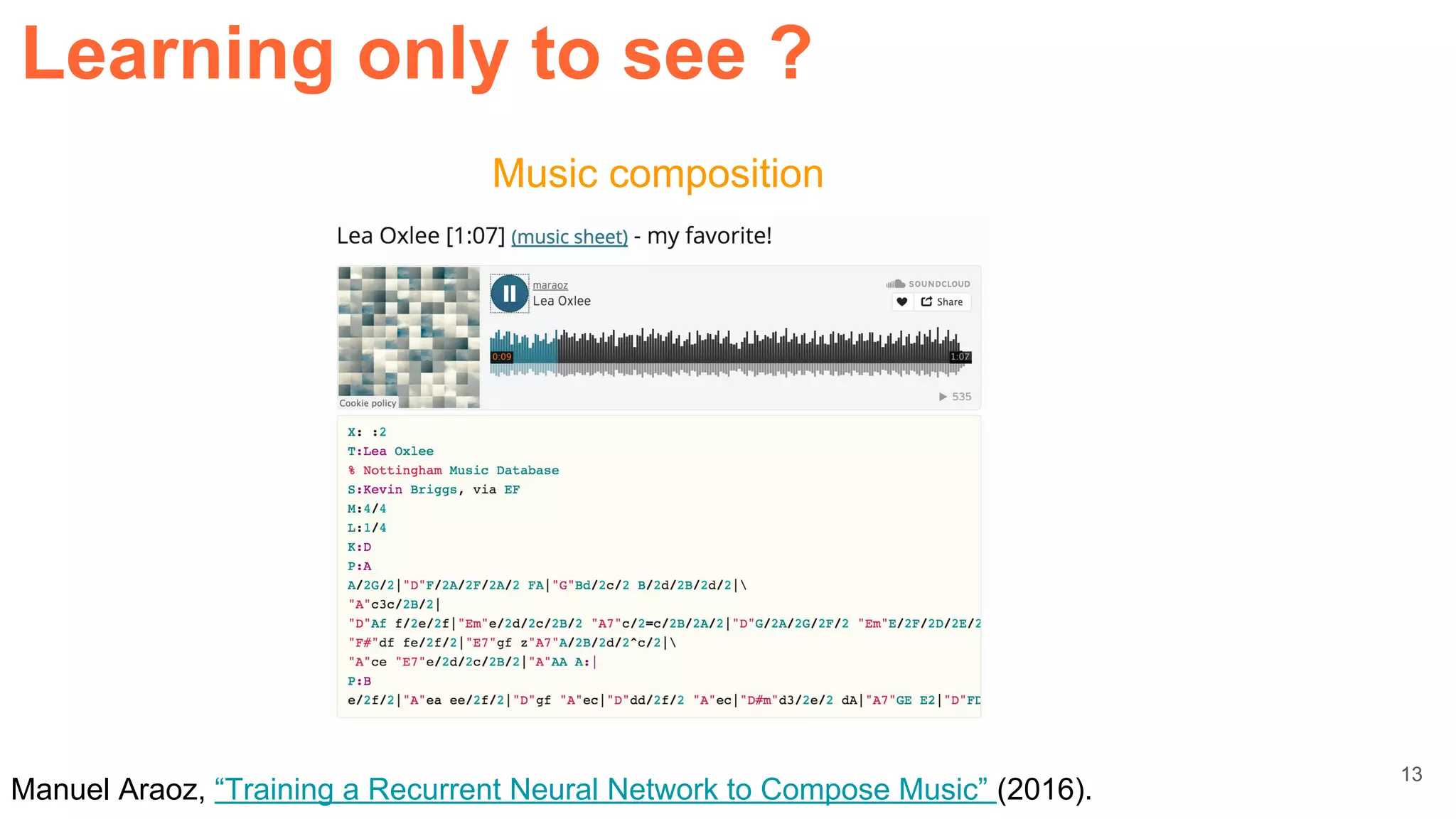






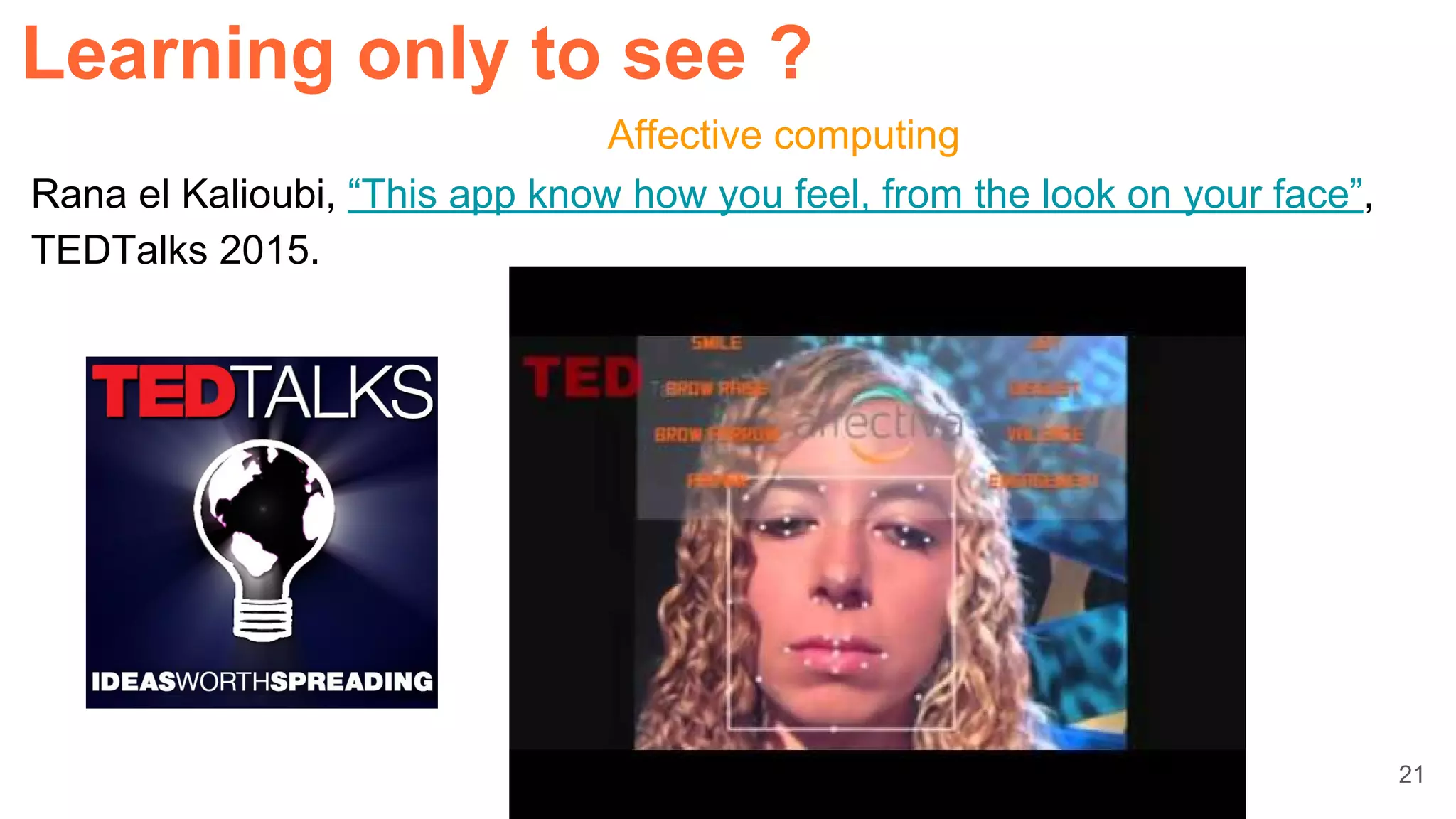
![22
Nexi Project,
from MIT Media Lab
(Photos: Spencer Lowel)
[video]
Affective computing
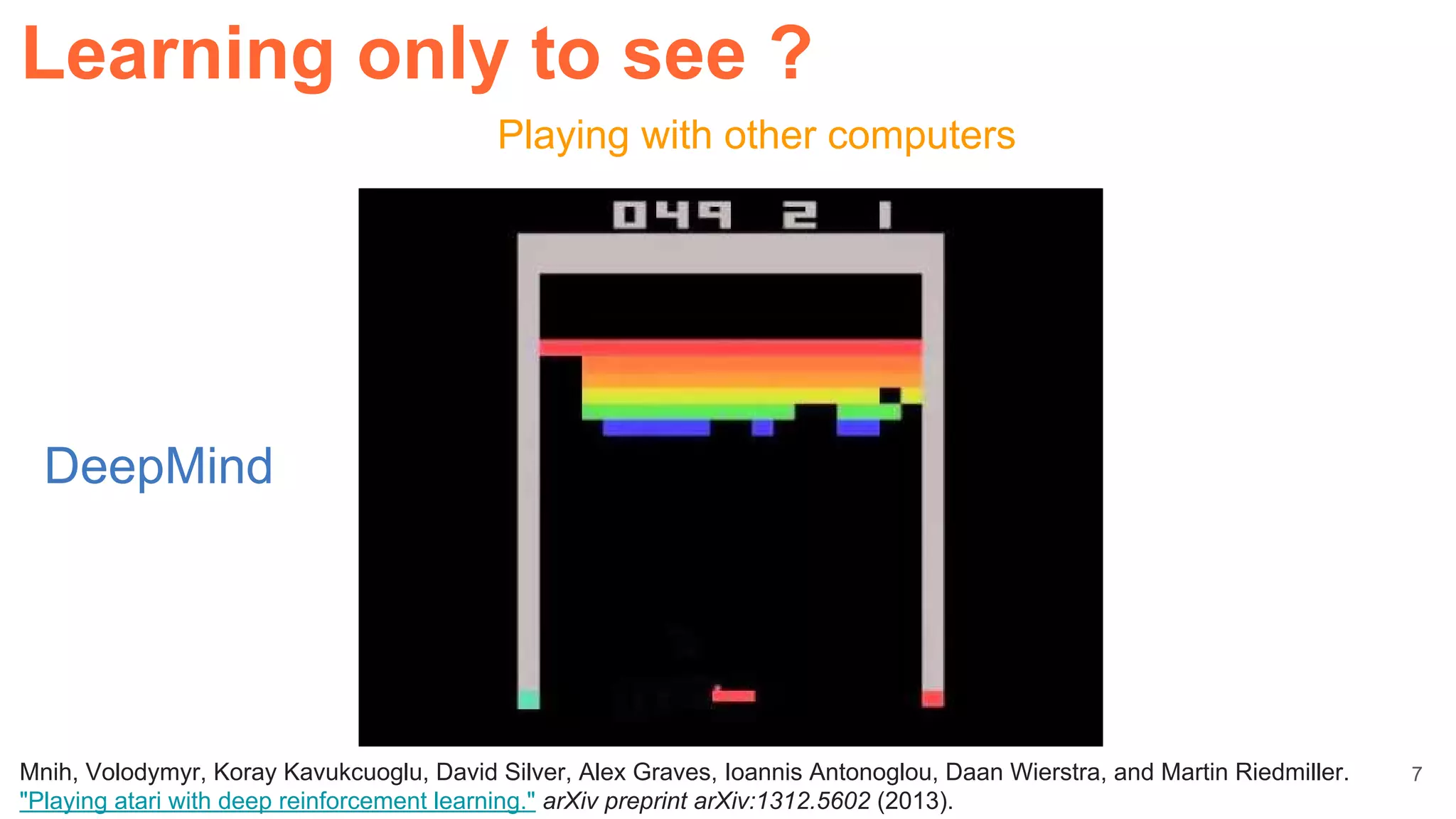
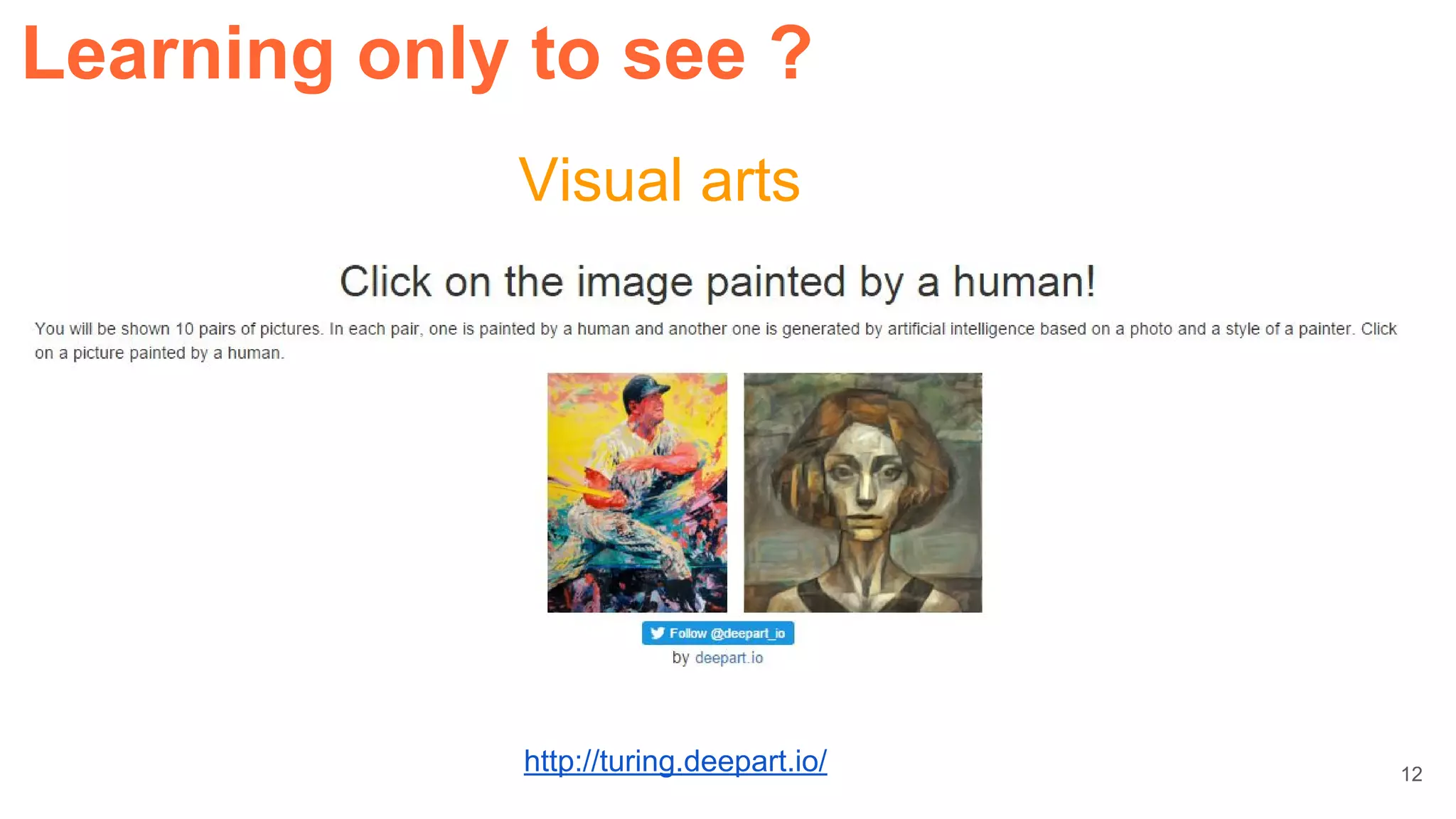
Learning only to see ?](https://image.slidesharecdn.com/dlcvd5closing-160803180548/75/Deep-Learning-for-Computer-Vision-Closing-UPC-2016-22-2048.jpg)
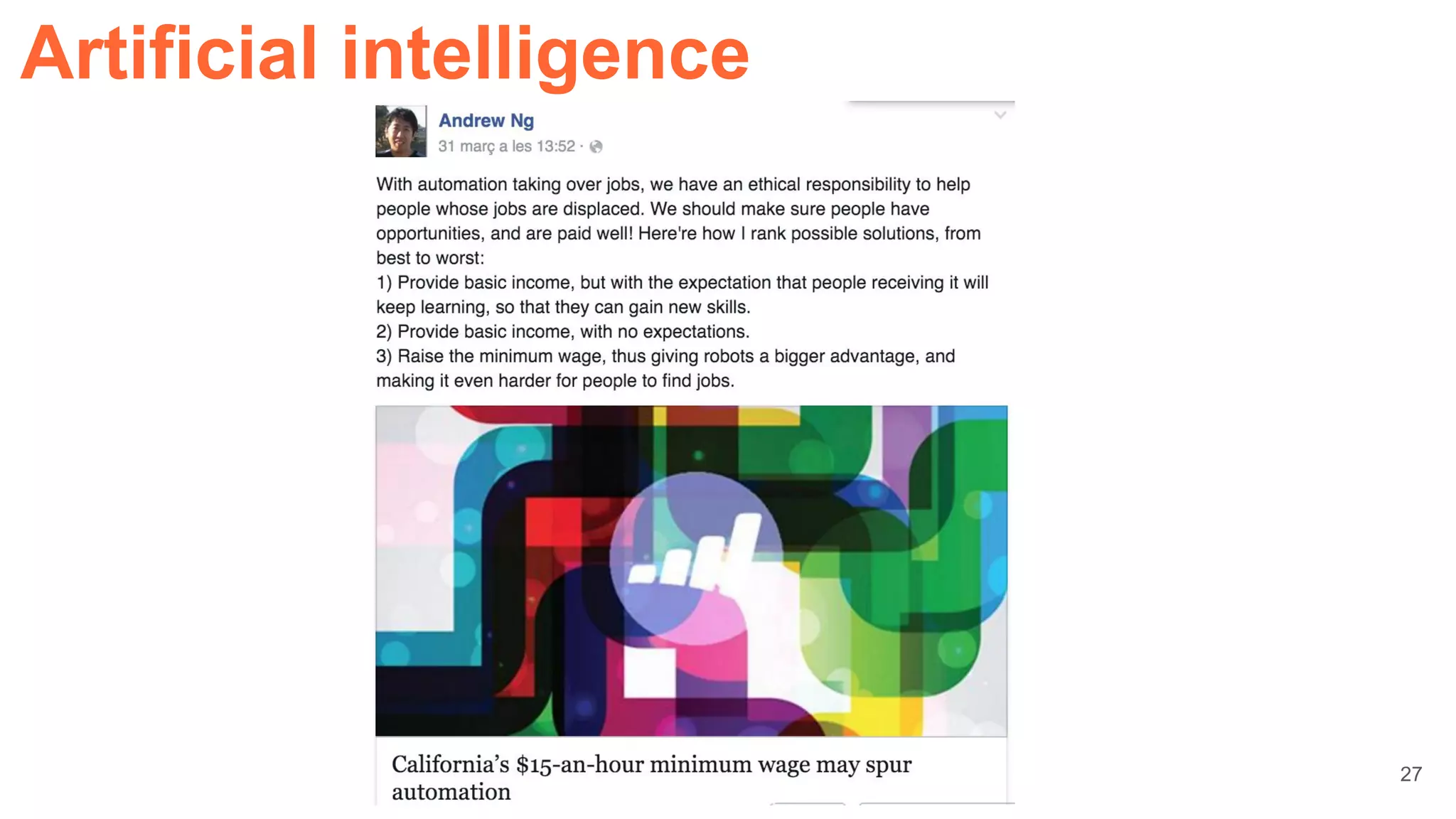
![“Google’s chairman (Eric Schmidth) thinks artificial intelligence will let
scientists solve some of the world’s "hard problems," like population
growth, climate change, human development, and education.”
(Bloomberg Business, 11/01/2016)
[+info @ MIT Technology Review]
Artificial intelligence
23](https://image.slidesharecdn.com/dlcvd5closing-160803180548/75/Deep-Learning-for-Computer-Vision-Closing-UPC-2016-23-2048.jpg)










![Learn more
[Website]
Consider extending your project to a workshop paper (not announced yet)
and apply for some volunteer opportunities for free registration.
Also: specific
workshop and
social event for
Women in
Machine Learning
38](https://image.slidesharecdn.com/dlcvd5closing-160803180548/75/Deep-Learning-for-Computer-Vision-Closing-UPC-2016-38-2048.jpg)














The document discusses various applications and implications of artificial intelligence, particularly in areas such as computer vision, healthcare, and creative fields. It highlights projects and research from institutions like Google DeepMind and MIT Media Lab, as well as insights from prominent figures in AI. Additionally, it raises questions about the future impact of AI on society, including job displacement and ethical considerations.





















































































![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)













