Download to read offline
![Disentangling Motion, Foreground and
Background Features in Videos
Slides by Xunyu Lin
ReadAI, UPC
29th May, 2017
Xunyu Lin, Victor Campos, Xavier Giro-i-Nieto, Jordi
Torres, Cristian Canton Ferrer
[paper] (15 May 2017) [code] [demo]](https://image.slidesharecdn.com/disentanglemotionforegroundandbackgroundfeaturesinvideos-170713123427/85/Disentangle-motion-Foreground-and-Background-Features-in-Videos-1-320.jpg)
![Disentangling Motion, Foreground and
Background Features in Videos
Slides by Xunyu Lin
ReadAI, UPC
29th May, 2017
Xunyu Lin, Victor Campos, Xavier Giro-i-Nieto, Jordi
Torres, Cristian Canton Ferrer
[paper] (15 May 2017) [code] [demo]](https://image.slidesharecdn.com/disentanglemotionforegroundandbackgroundfeaturesinvideos-170713123427/75/Disentangle-motion-Foreground-and-Background-Features-in-Videos-1-2048.jpg)





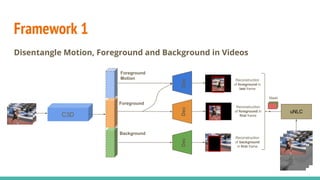
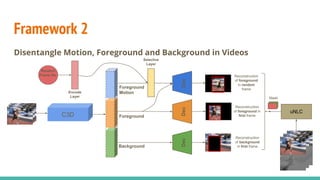
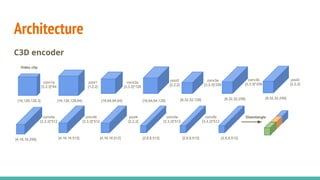
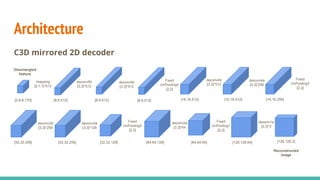





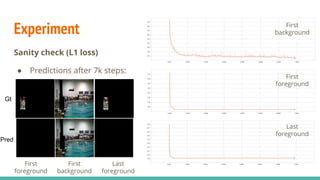


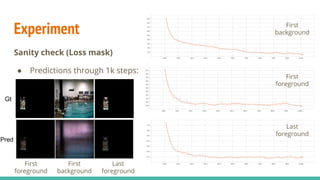
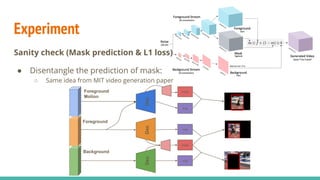
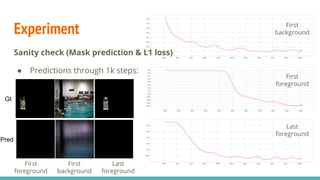

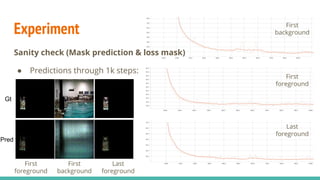
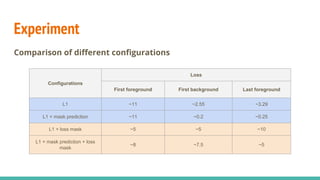
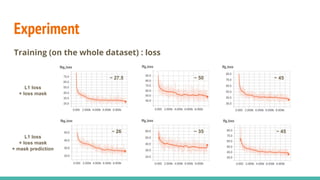




The document discusses a novel approach to unsupervised video feature learning, focusing on disentangling motion, foreground, and background components in videos. It highlights the importance of learning through observation, mimicking human perception, and presents a methodology for improving video representation using loss definitions for reconstruction and feature loss. The findings suggest that this approach can enhance video segmentation and representation and propose future work involving larger datasets and adversarial loss techniques.







































































