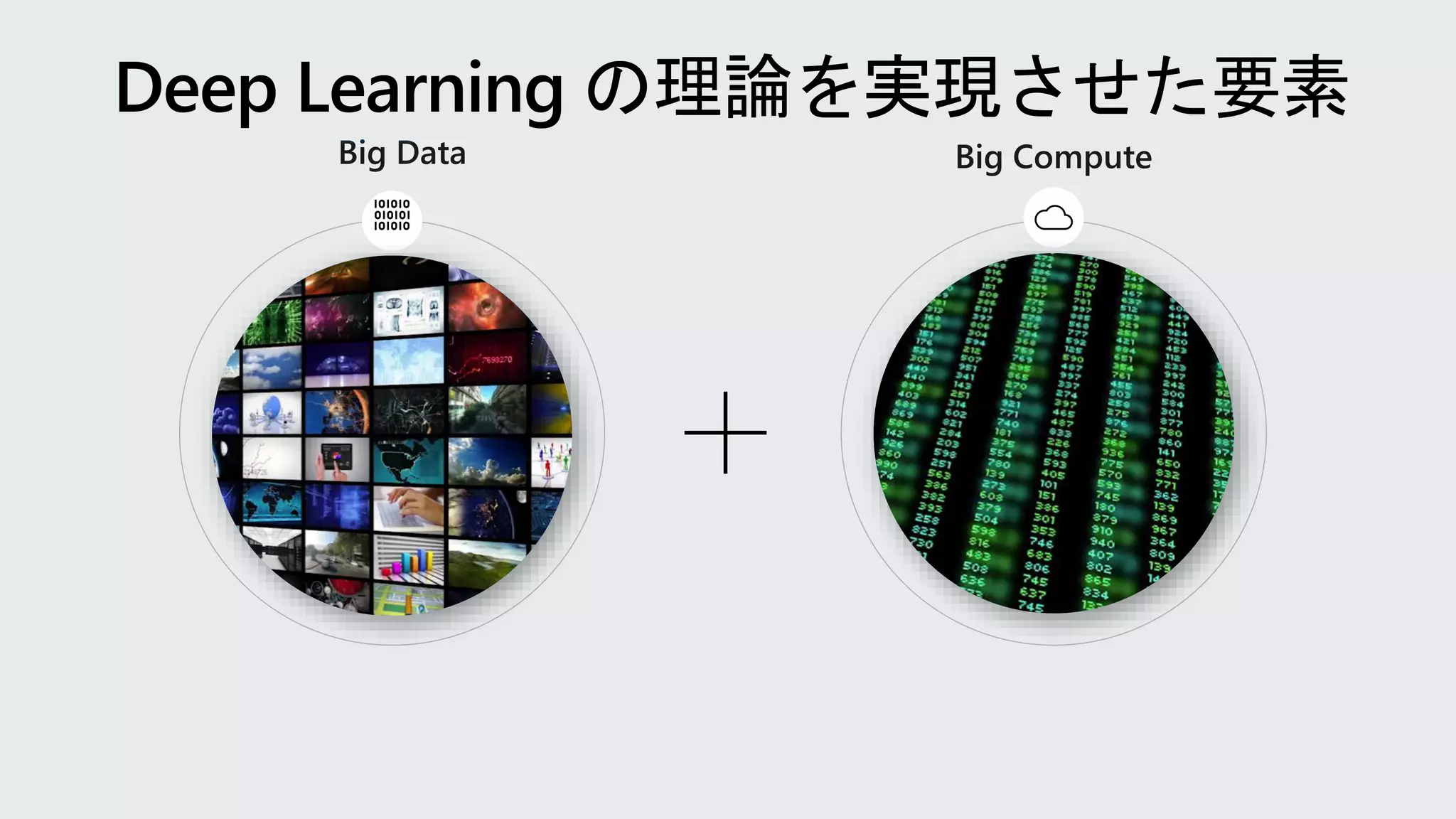
Speech
Recognition
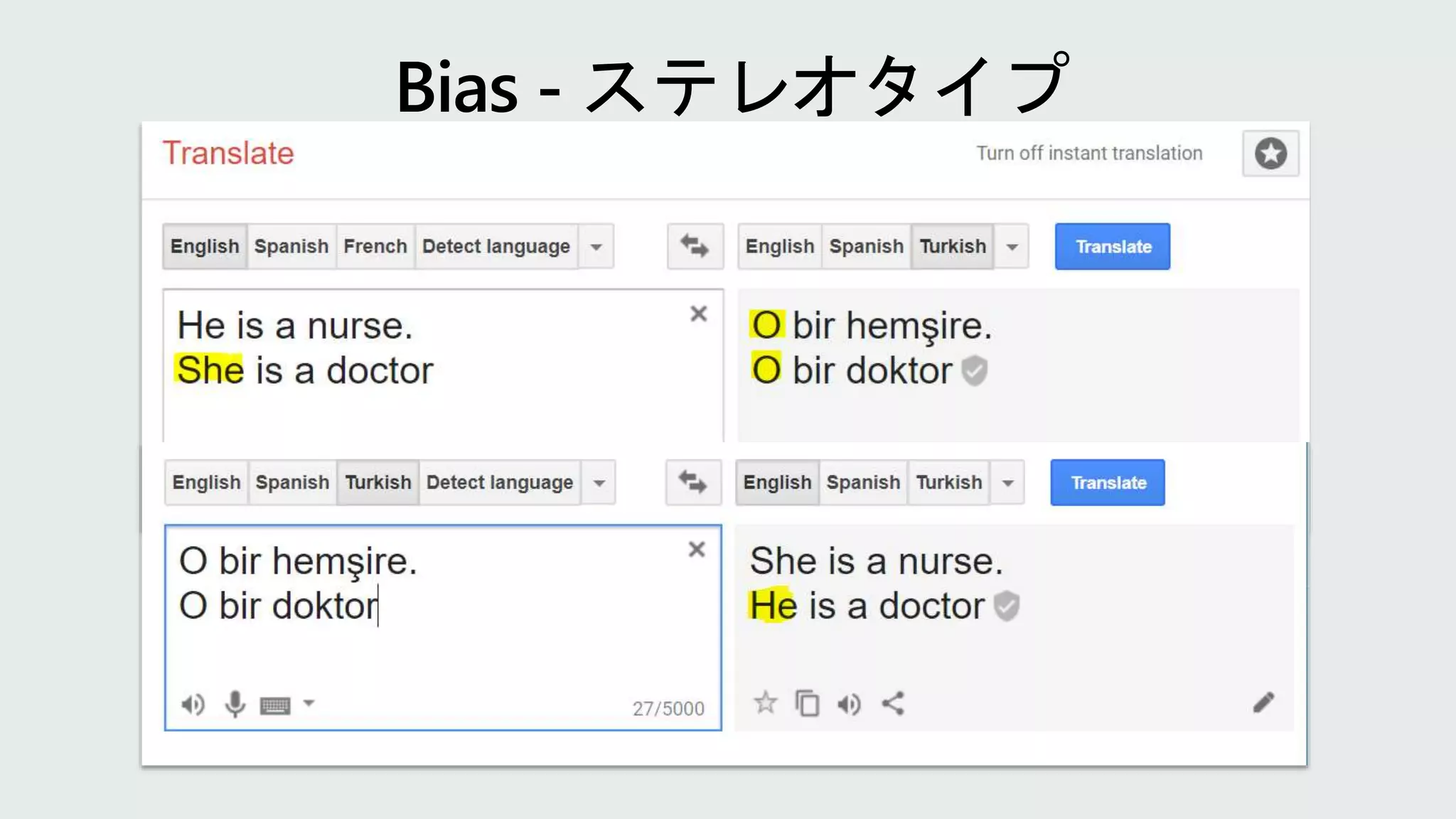
Vision Translation
Reading
Speech
Synthesis
2016
Object recognition
humanparity
2017
Speech recognition
human parity
2018
Reading comprehension
human parity
2018
Machine translation
human parity
2018
Speech synthesis
near-human parity
Language
Understanding
2019
General Language
Understanding human parity
Language
Generation
2020
Document summary at human
parity
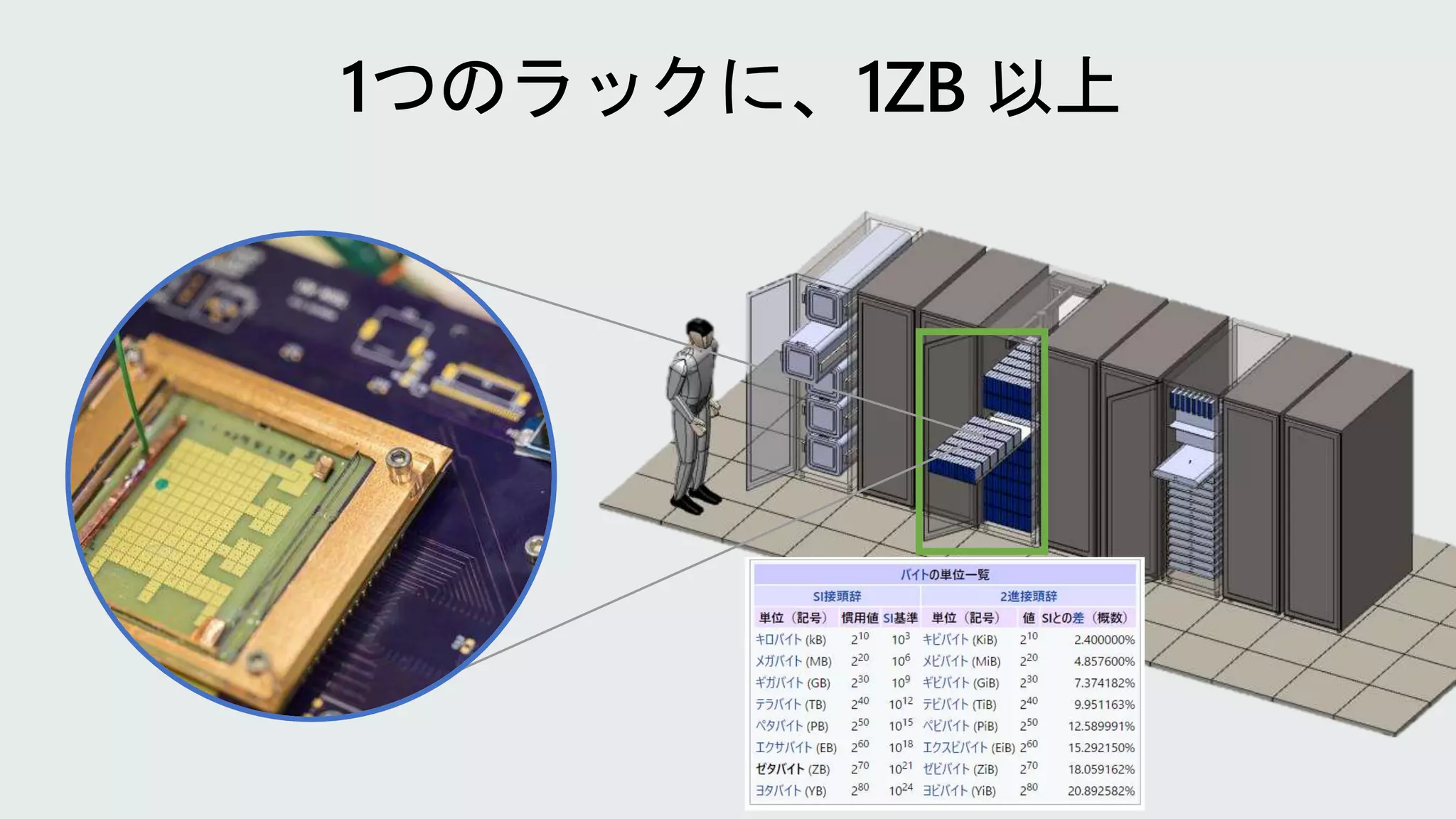
22.
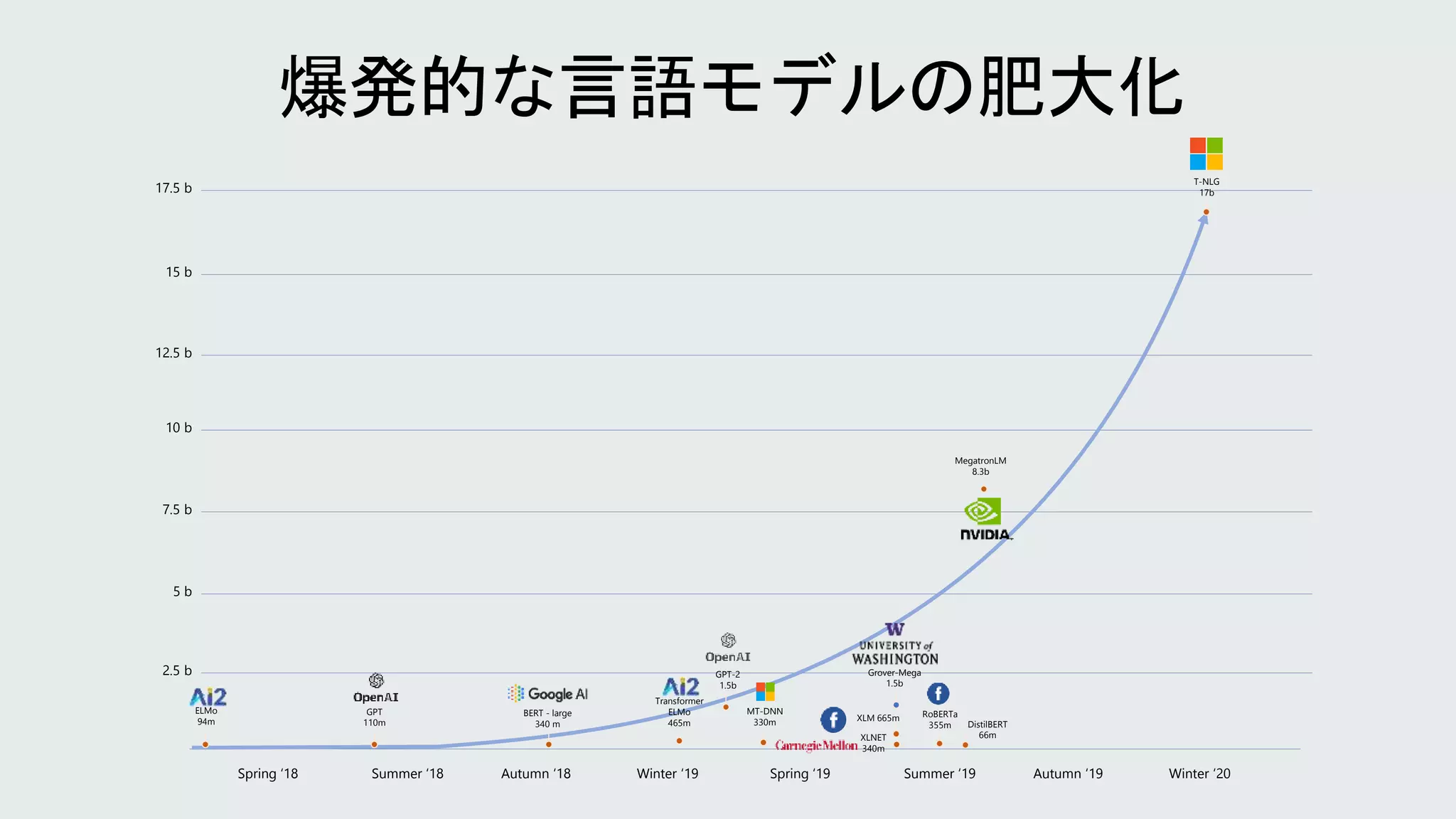
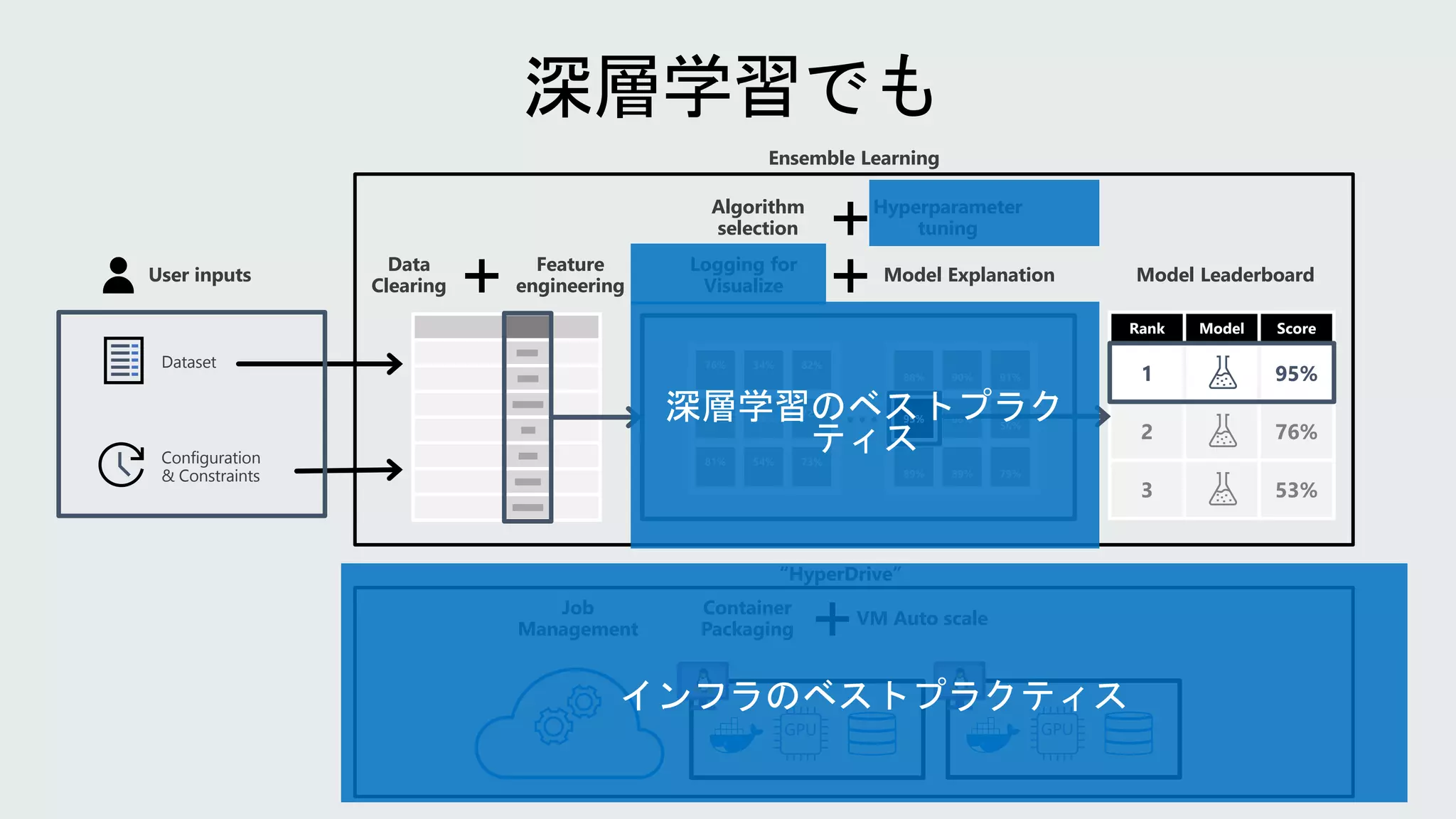
爆発的な言語モデルの肥大化
5 b
7.5 b
10b
12.5 b
15 b
17.5 b
Spring ‘18 Summer ‘18 Autumn ‘18 Winter ‘19 Spring ‘19 Summer ‘19 Autumn ‘19 Winter ‘20
2.5 b
ELMo
94m
GPT
110m
BERT - large
340 m
Transformer
ELMo
465m
GPT-2
1.5b
MT-DNN
330m
XLNET
340m
XLM 665m
Grover-Mega
1.5b
RoBERTa
355m DistilBERT
66m
MegatronLM
8.3b
T-NLG
17b
23.
自然言語からのコードに生成で、Citizen Developer でも数式の機能を容易に使える
Professional Developer は、数式の検索とチューニングに費やす時間を短縮することで、オーサリングを高速化
ギャラリーとデータ テーブルで最初にサポートされ、ユーザーからのフィードバックに基づいて、より多くのコント
ロールと数式に展開
24.
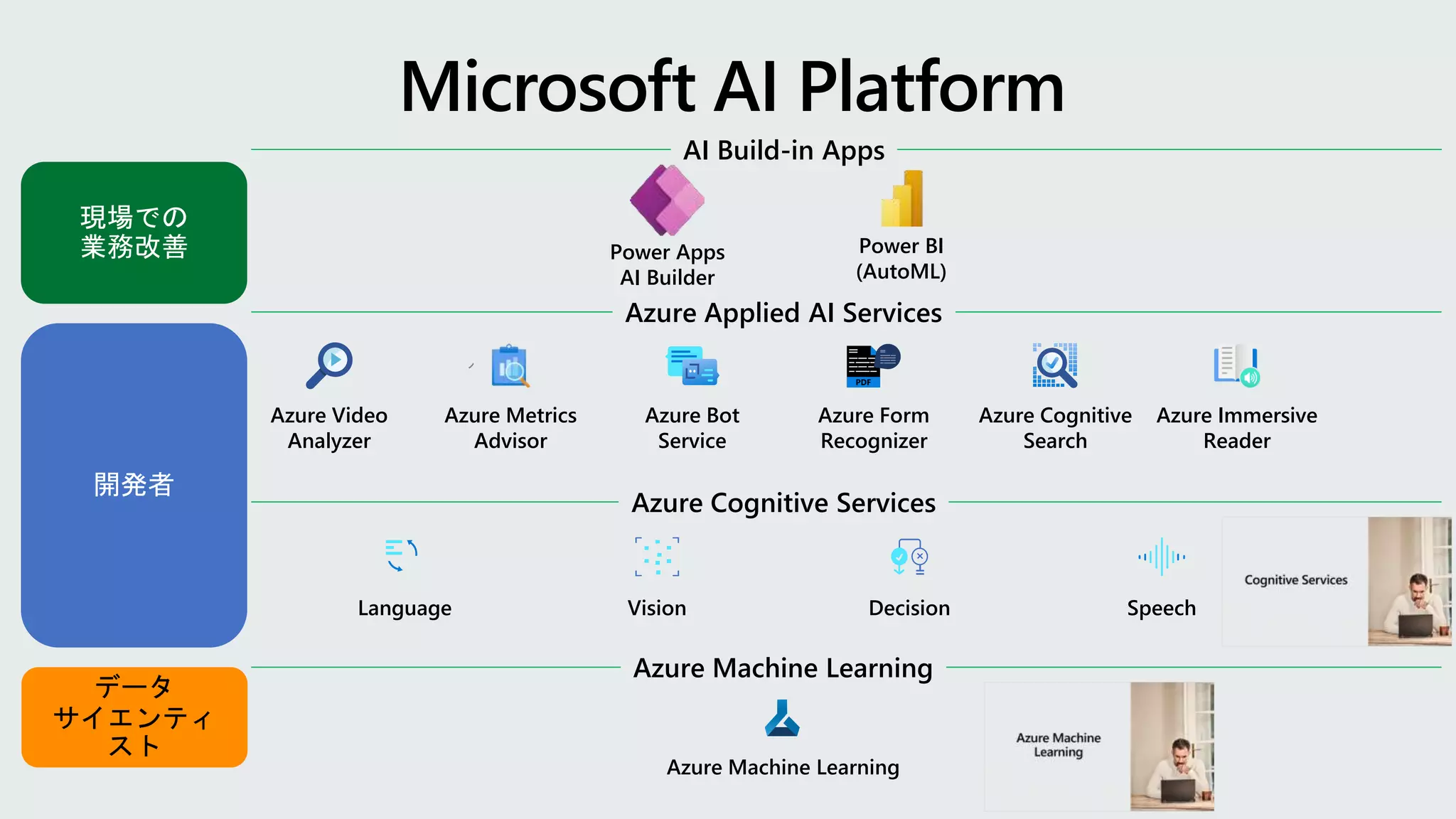
Azure Metrics
Advisor
Azure Video
Analyzer
AzureBot
Service
Azure Applied AI Services
Azure Form
Recognizer
Azure Cognitive
Search
Azure Immersive
Reader
Azure Cognitive Services
Vision Speech
Language Decision
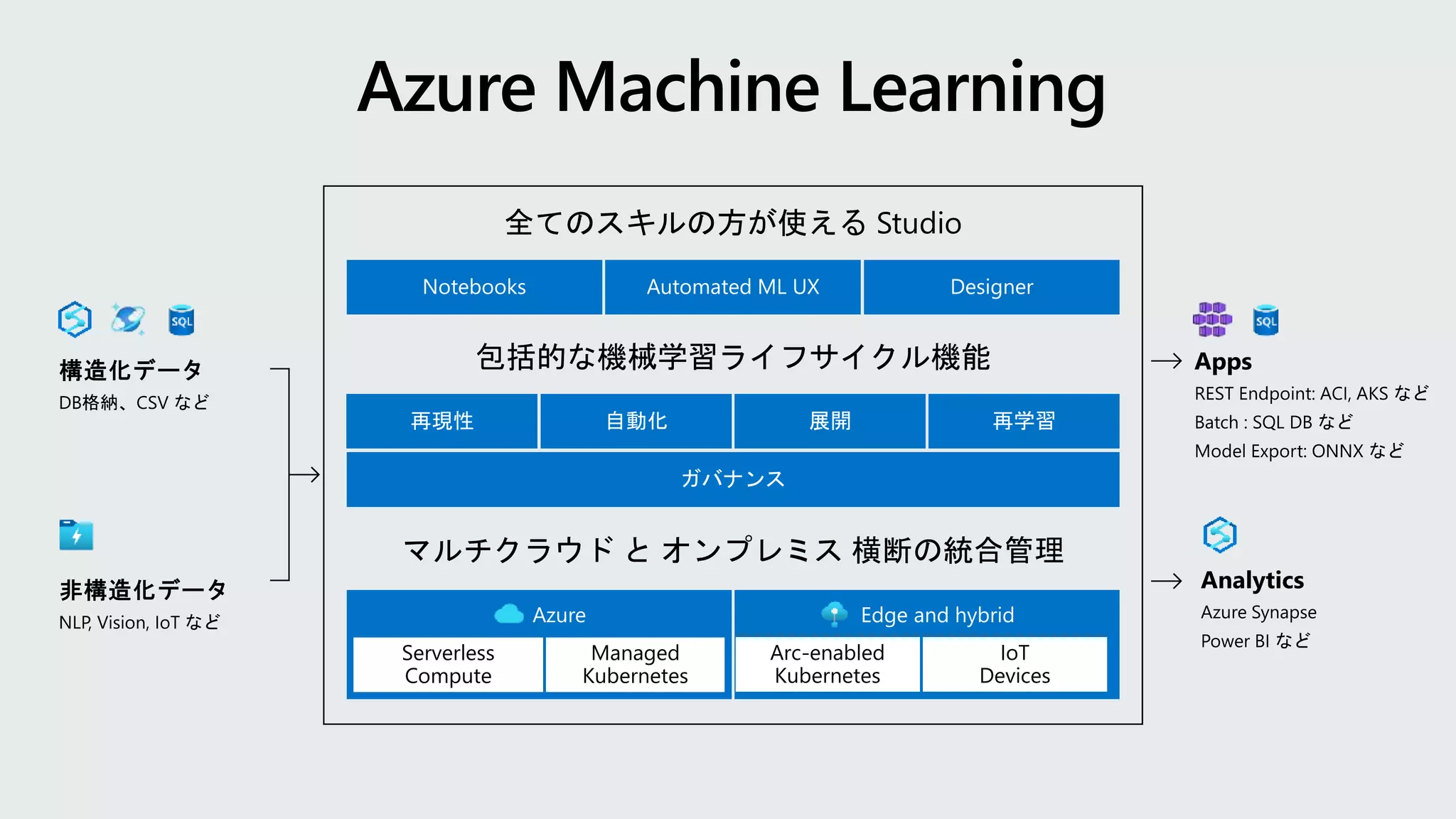
Azure Machine Learning
Azure Machine Learning
AI Build-in Apps
Power Apps
AI Builder
Power BI
(AutoML)
26.
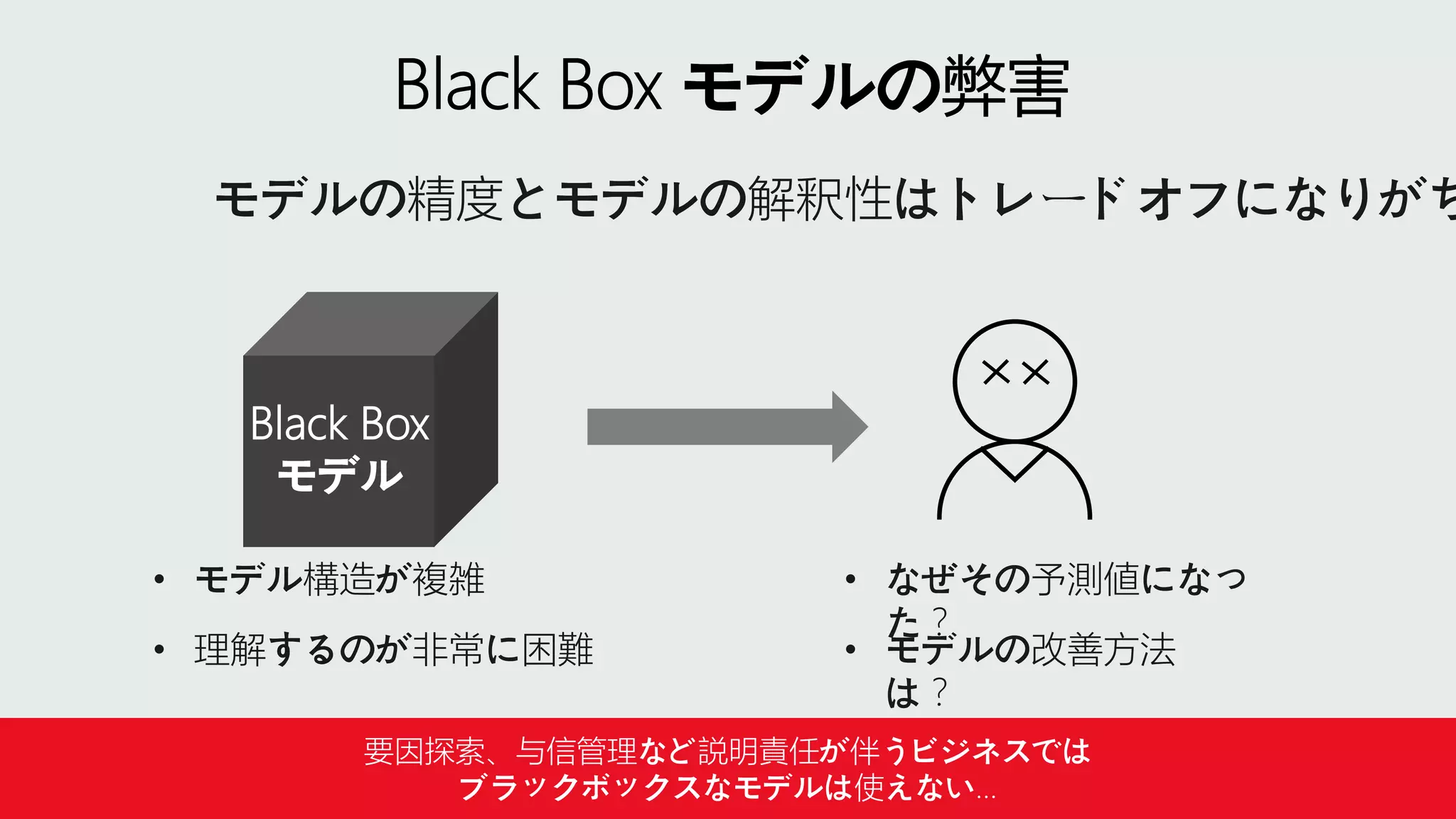
ビジネスですぐに利用できる AI を活用した自動化サービス
DO C U M E N T S
Azure Form Recognizer
S E A R C H
Azure Cognitive Search
A C C E S S I B I L I T Y
Azure Immersive Reader
V I D E O S
Azure Video Analyzer
M O N I T O R I N G
Azure Metrics Advisor
C O N V E R S A T I O N S
Azure Bot Service
27.
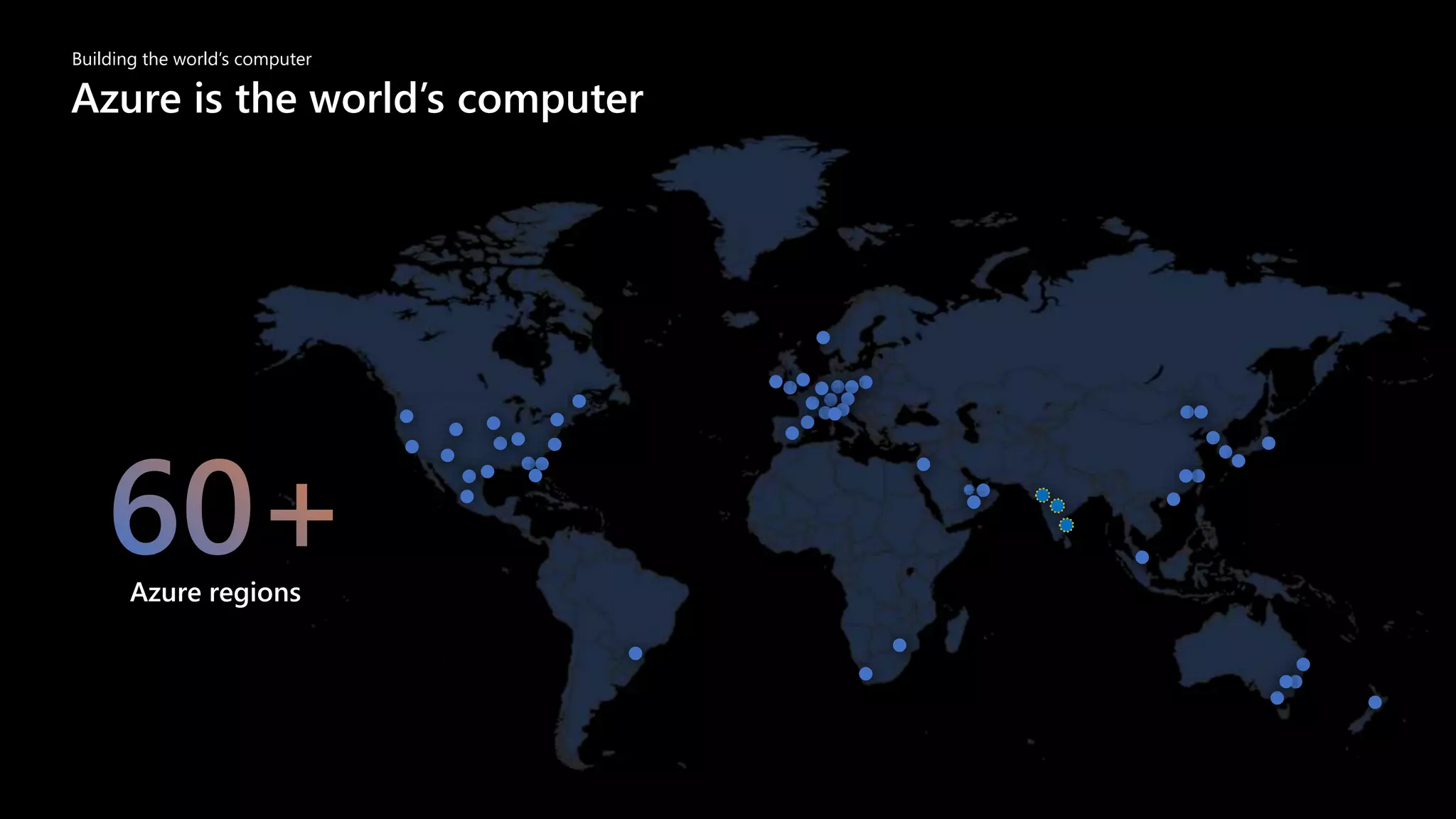
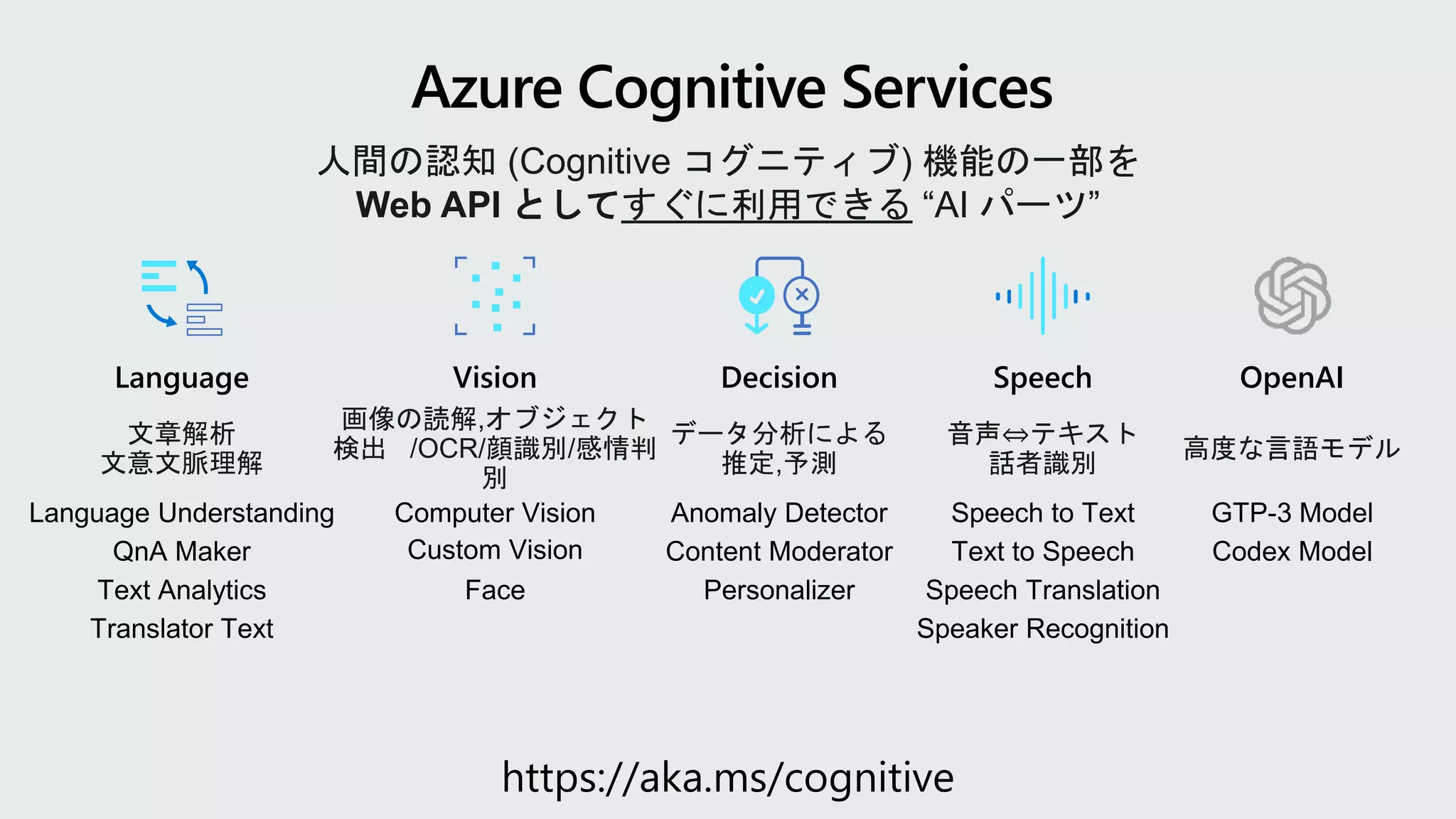
https://aka.ms/cognitive
人間の認知 (Cognitive コグニティブ)機能の一部を
Web API としてすぐに利用できる “AI パーツ”
Vision
Face
Computer Vision
Custom Vision
Speech
Speaker Recognition
Speech to Text
Text to Speech
Speech Translation
Language
Translator Text
Language Understanding
Text Analytics
QnA Maker
Decision
Content Moderator
Personalizer
Anomaly Detector
OpenAI
GTP-3 Model
Codex Model
My Computer DataStore
Azure ML
Workspace
Compute Target
Experiment
Docker Image
39.
import
'--data-folder' type str
'data_folder''data folder
mounting point’
'train-images.gz' False 255.0
'test-images.gz' False 255.0
'train-labels.gz' True 1
'test-labels.gz' True 1
#1. Dataset
'./data/mnist'
'mnist' True
True
Data Store
40.
import
'--batch-size' type int
'batch_size''mini
batch size for training'
'--epoch' type int
'epoch' 'epoch size
for training’
from import
'--data-folder' 'mnist'
'--batch-size' 50
'--epoch' 20
'--first-layer-neurons' 300
'--second-layer-neurons' 100
'--learning-rate' 0.001
'--activation'
'--optimizer'
'--loss'
'--dropout' 0.2
'--gpu'
'keras' 'matplotlib'
‘train.py'
True
1800
#2. Script Folder
'./keras-mnist'
True
import
‘./train.py'
'./utils.py'
Docker Image
Data Store
41.
from import
# startan Azure ML run
class LogRunMetrics
# callback at the end of every epoch
def on_epoch_end
# log a value repeated which creates a list
'Loss' 'loss'
'Accuracy' 'acc'
2
Experiment
42.
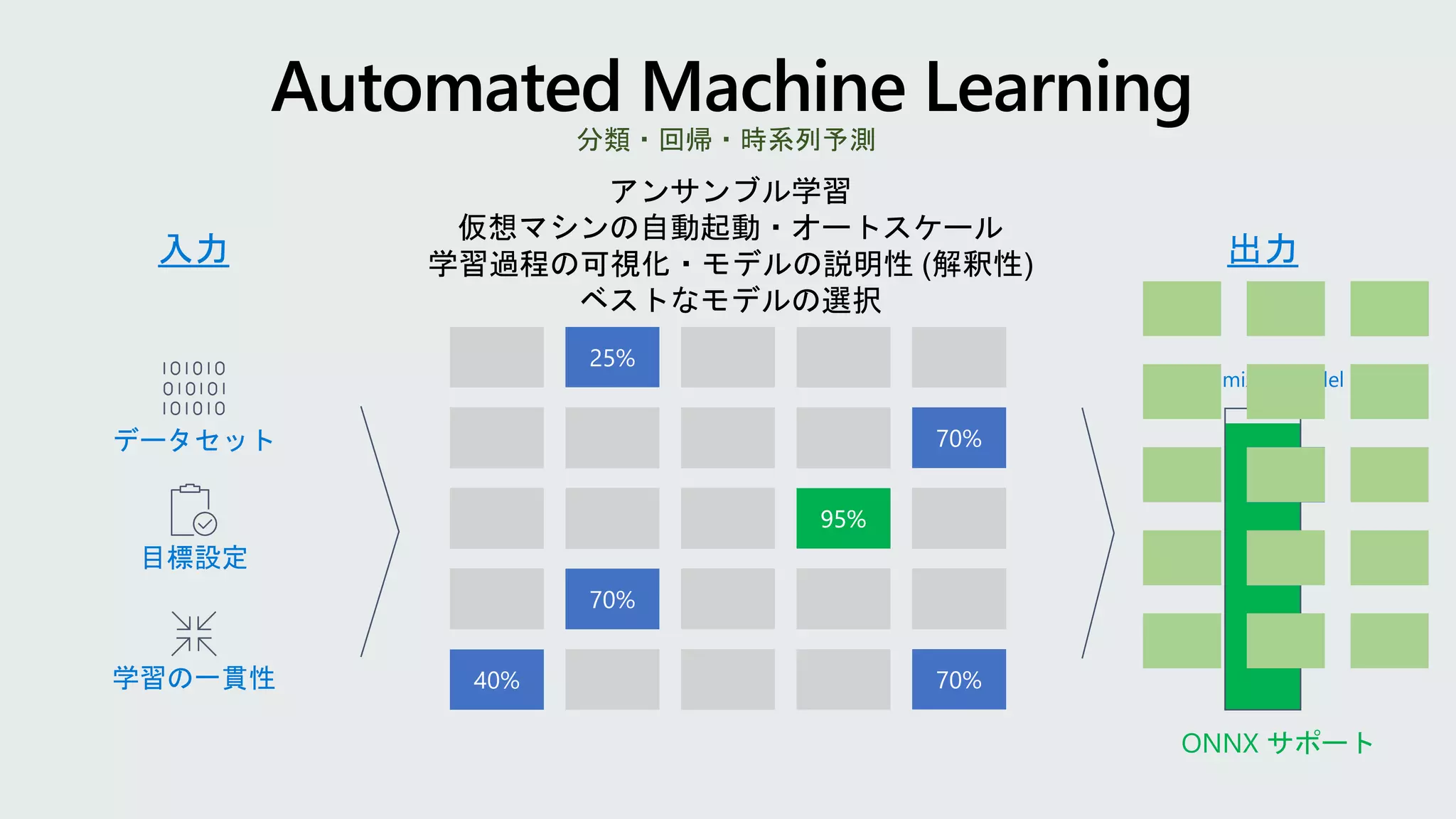
主要な深層学習・機械学習ライブラリの抽象化クラス
from azureml.train.estimator importEstimator
script_params = { ‘--learning-rate’: 0.3, '--regularization': 0.8 }
est = Estimator(source_directory=script_folder,
script_params=script_params,
compute_target=compute_target,
entry_script='train.py’,
conda_packages=['scikit-learn'])
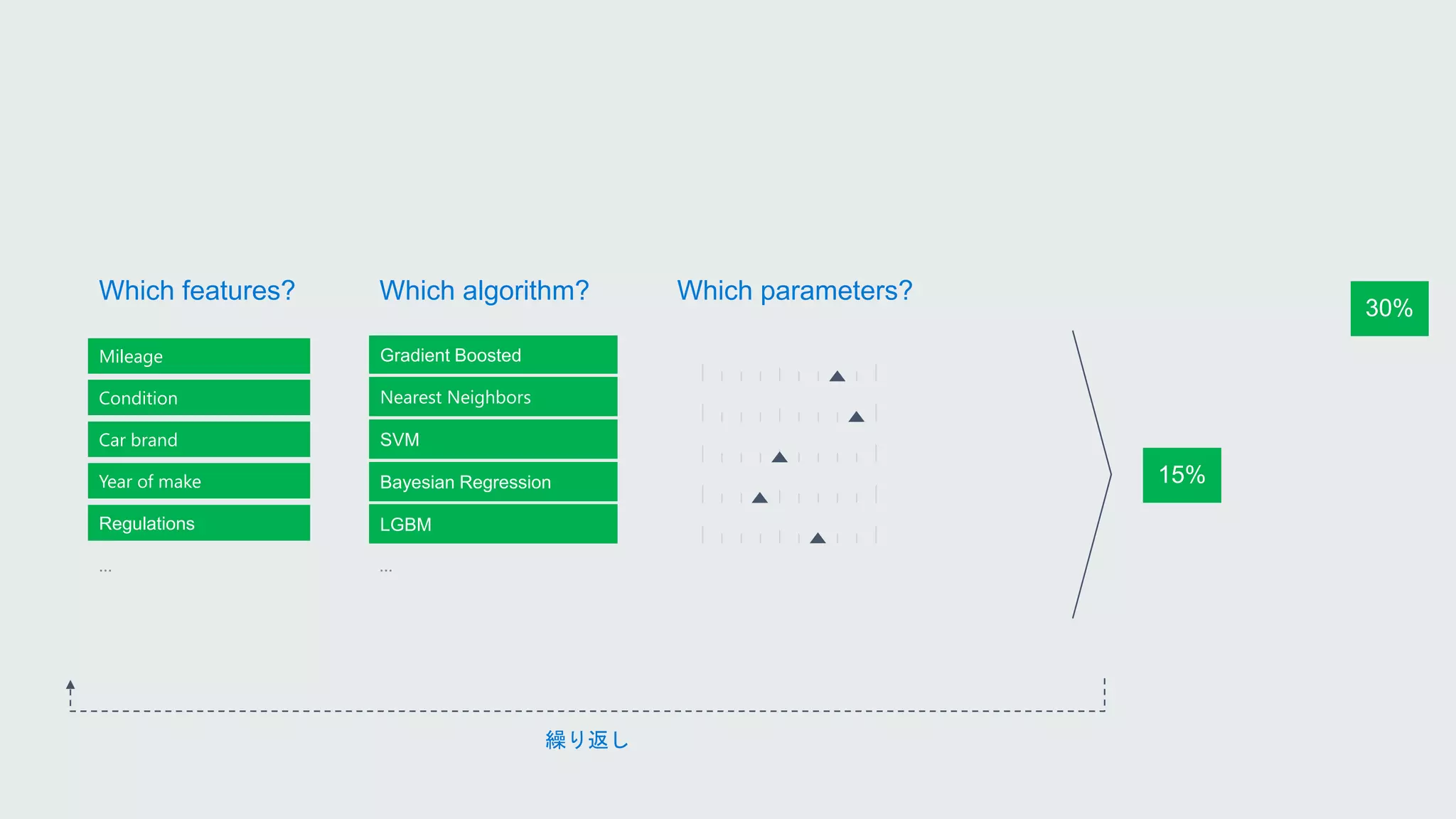
Mileage
Condition
Car brand
Year ofmake
Regulations
…
Parameter 1
Parameter 2
Parameter 3
Parameter 4
…
Gradient Boosted
Nearest Neighbors
SVM
Bayesian Regression
LGBM
…
Mileage Gradient Boosted Criterion
Loss
Min Samples Split
Min Samples Leaf
Others Model
Which algorithm? Which parameters?
Which features?
Car brand
Year of make
試行錯誤
47.
Criterion
Loss
Min Samples Split
MinSamples Leaf
Others
N Neighbors
Weights
Metric
P
Others
Which algorithm? Which parameters?
Which features?
Mileage
Condition
Car brand
Year of make
Regulations
…
Gradient Boosted
Nearest Neighbors
SVM
Bayesian Regression
LGBM
…
Nearest Neighbors
Model
繰り返し
Gradient Boosted
Mileage
Car brand
Year of make
Car brand
Year of make
Condition
48.
Mileage
Condition
Car brand
Year ofmake
Regulations
…
Gradient Boosted
Nearest Neighbors
SVM
Bayesian Regression
LGBM
…
Gradient Boosted
SVM
Bayesian Regression
LGBM
Nearest Neighbors
Which algorithm? Which parameters?
Which features?
繰り返し
Regulations
Condition
Mileage
Car brand
Year of make
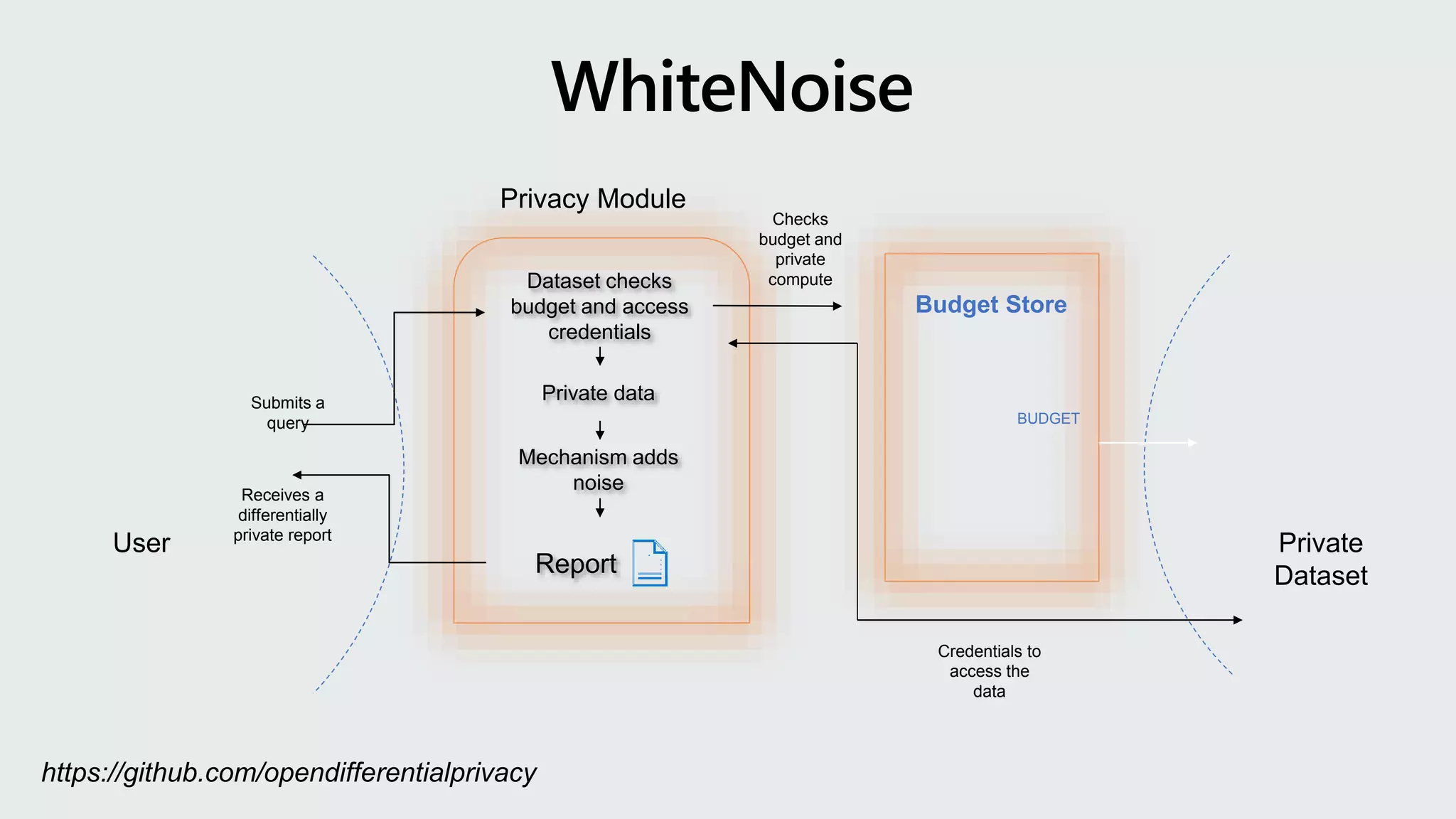
Privacy Module
Report
Budget Store
BUDGET
UserPrivate
Dataset
Submits a
query
Receives a
differentially
private report
Mechanism adds
noise
Private data
Dataset checks
budget and access
credentials
Checks
budget and
private
compute
Credentials to
access the
data
https://github.com/opendifferentialprivacy
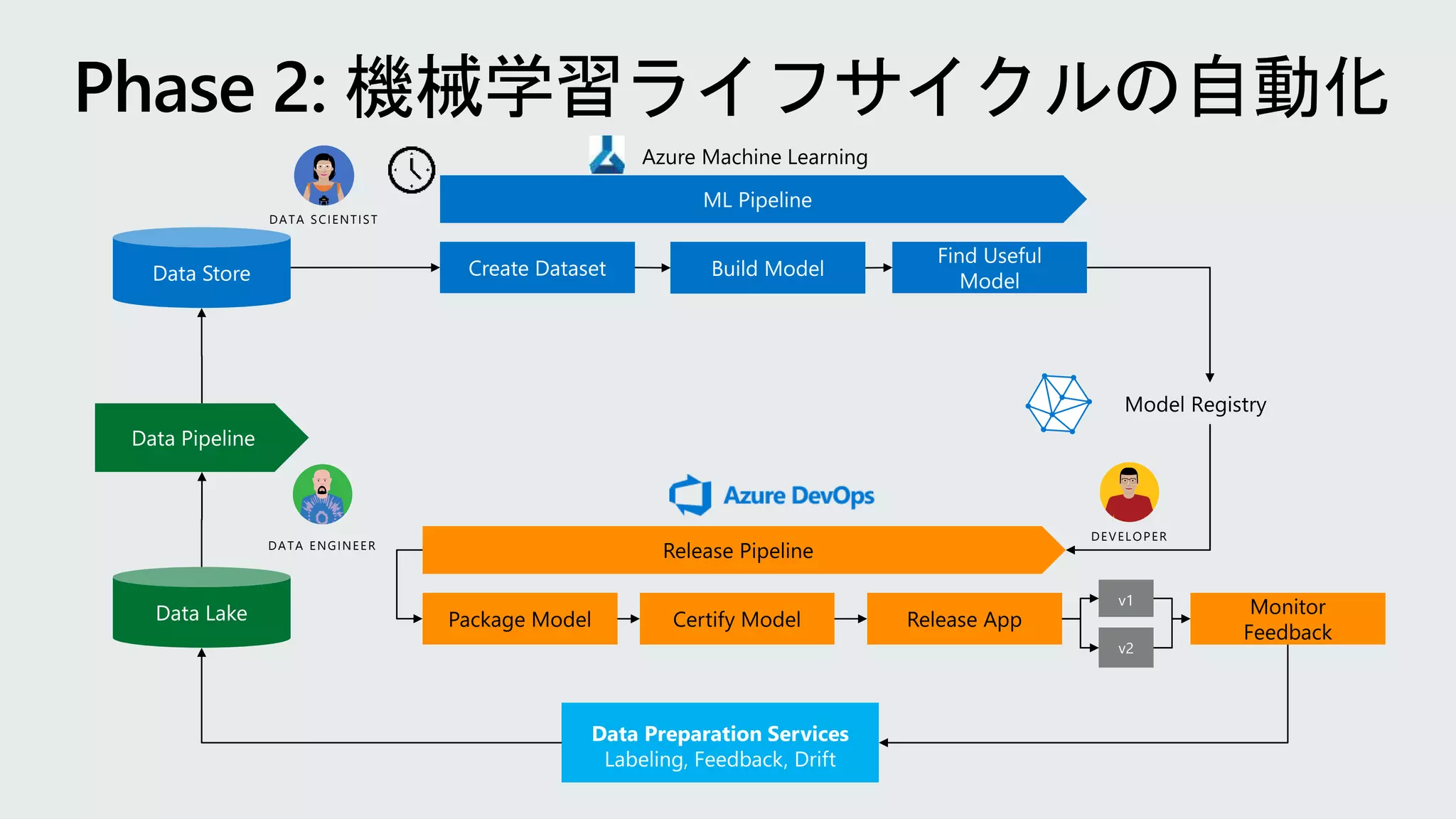
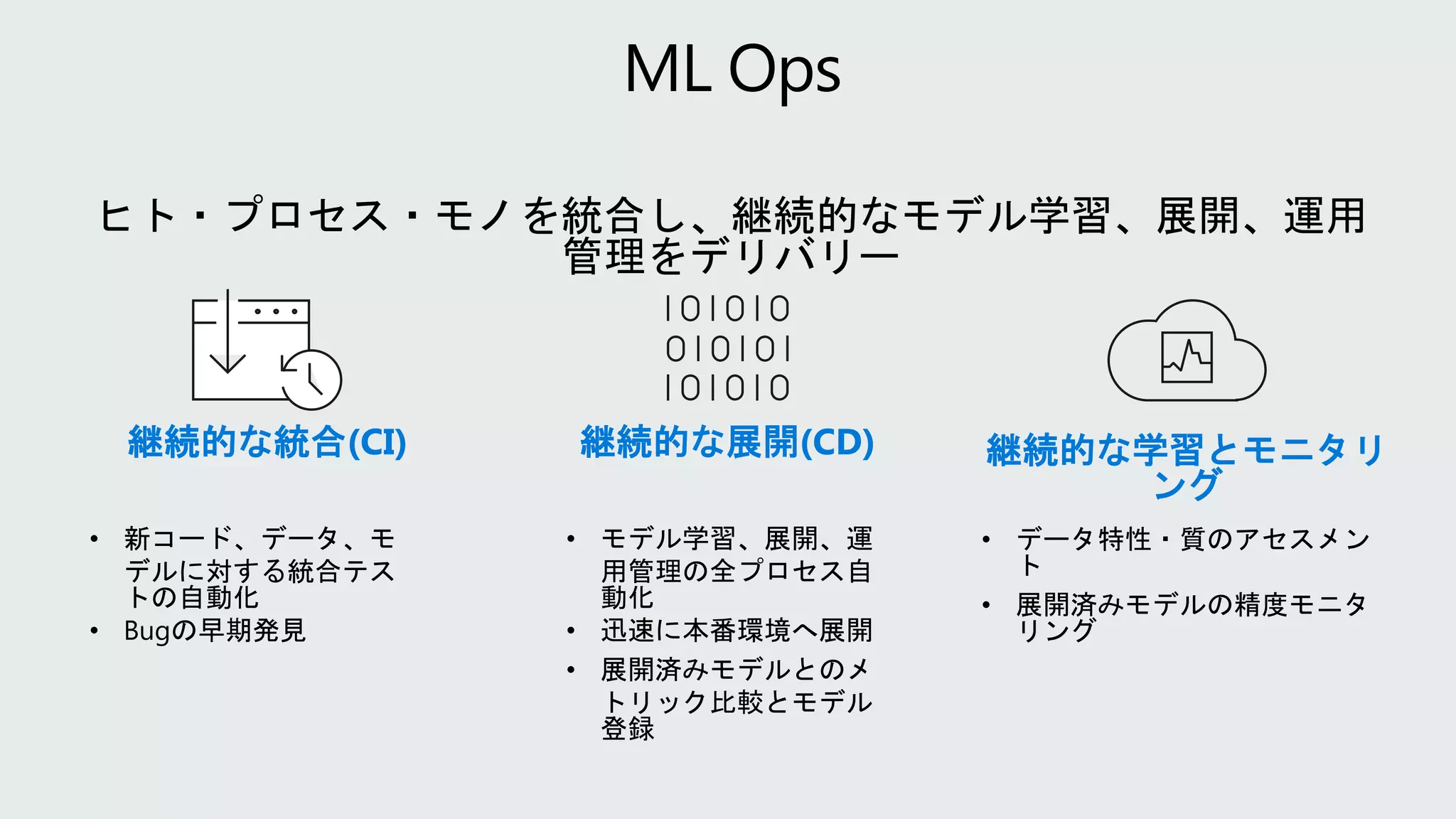
Model reproducibility Modelretraining
Model deployment
Model validation
Train model Validate
model
Deploy
model
Monitor
model
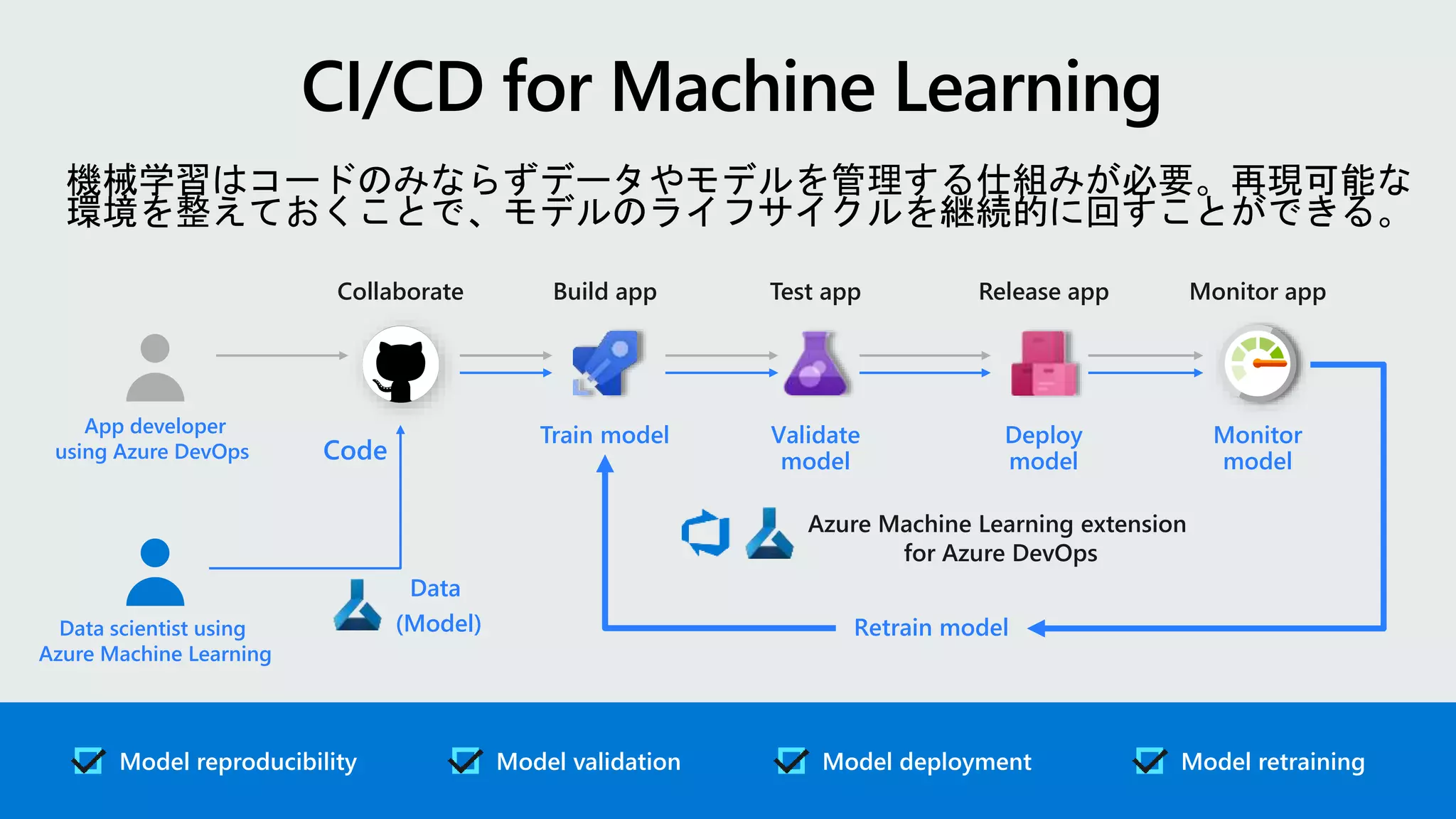
Build app
Collaborate Test app Release app Monitor app
App developer
using Azure DevOps
Data scientist using
Azure Machine Learning
Retrain model
Azure Machine Learning extension
for Azure DevOps
Data
(Model)
Code
機械学習はコードのみならずデータやモデルを管理する仕組みが必要。再現可能な
環境を整えておくことで、モデルのライフサイクルを継続的に回すことができる。




























![主要な深層学習・機械学習ライブラリの抽象化クラス
from azureml.train.estimator import Estimator
script_params = { ‘--learning-rate’: 0.3, '--regularization': 0.8 }
est = Estimator(source_directory=script_folder,
script_params=script_params,
compute_target=compute_target,
entry_script='train.py’,
conda_packages=['scikit-learn'])](https://image.slidesharecdn.com/20220415aionazurepublic-220414092222/75/AI-on-Azure-42-2048.jpg)










































































![[Developers Festa Sapporo 2018] Azure AI ~Microsoft AzureでのAI開発のイマ~](https://cdn.slidesharecdn.com/ss_thumbnails/20181117devfestasapporoazureaipublic-181119035506-thumbnail.jpg?width=640&height=640&fit=bounds)












































