Downloaded 114 times














![21
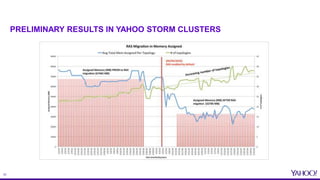
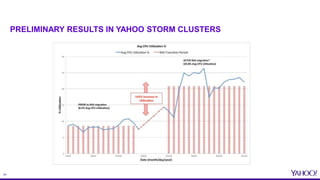
SELECTED RESULTS (THROUGHPUT) FROM PAPER [1] – YAHOO
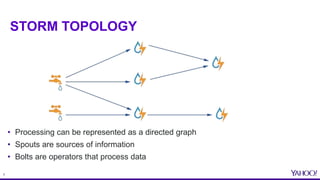
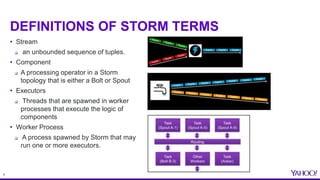
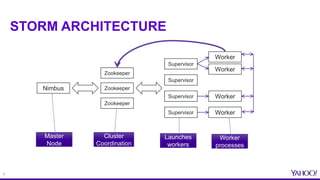
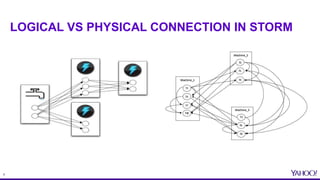
TOPOLOGIES
47% improvement!
50% improvement!
* Figures used [1]](https://image.slidesharecdn.com/june29550yahoopeng-160712175118/85/Resource-Aware-Scheduling-in-Apache-Storm-21-320.jpg)
![22
SELECTED RESULTS (THROUGHPUT) FROM PAPER [1] – YAHOO
TOPOLOGIES](https://image.slidesharecdn.com/june29550yahoopeng-160712175118/85/Resource-Aware-Scheduling-in-Apache-Storm-22-320.jpg)


![27
REFERENCES
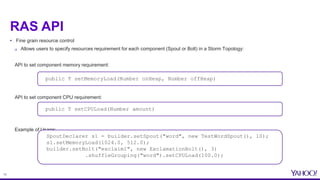
• [1] Peng, Boyang, Mohammad Hosseini, Zhihao Hong, Reza Farivar, and Roy Campbell. "R-storm:
Resource-aware scheduling in Storm." In Proceedings of the 16th Annual Middleware Conference,
pp. 149-161. ACM, 2015.
http://web.engr.illinois.edu/~bpeng/files/r-storm.pdf
• [2] Official Resource Aware Scheduler Documentation
https://storm.apache.org/releases/2.0.0-SNAPSHOT/Resource_Aware_Scheduler_overview.htm
• [3] Umbrella Jira for Resource Aware Scheduling in Storm
https://issues.apache.org/jira/browse/STORM-893](https://image.slidesharecdn.com/june29550yahoopeng-160712175118/85/Resource-Aware-Scheduling-in-Apache-Storm-27-320.jpg)

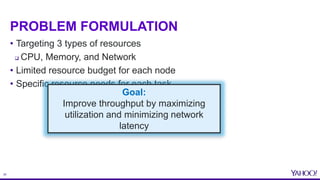




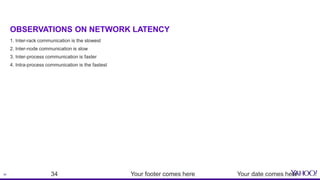
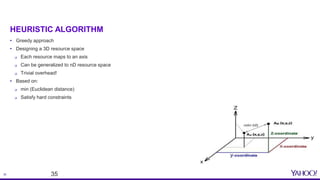



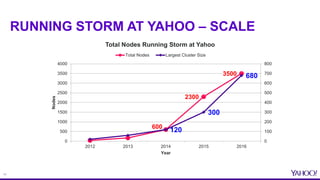
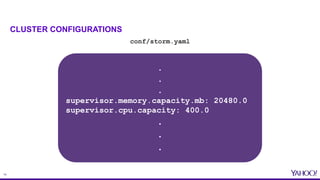
This document provides an overview of resource aware scheduling in Apache Storm. It discusses the challenges of scheduling Storm topologies at Yahoo scale, including increasing heterogeneous clusters, low cluster utilization, and unbalanced resource usage. It then introduces the Resource Aware Scheduler (RAS) built for Storm, which allows fine-grained resource control and isolation for topologies through APIs and cgroups. Key features of RAS include pluggable scheduling strategies, per user resource guarantees, and topology priorities. Experimental results from Yahoo Storm clusters show significant improvements to throughput and resource utilization with RAS. The talk concludes with future work on improved scheduling strategies and real-time resource monitoring.


























![[232] 성능어디까지쥐어짜봤니 송태웅](https://cdn.slidesharecdn.com/ss_thumbnails/232-161025013504-thumbnail.jpg?width=640&height=640&fit=bounds)




















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)














