Download as PDF, PPTX







































![Event Patterns
// Measure how long it takes users to respond to Tweet
insert into ResponseDelay
select t.id as tweet_id,
t.user as author,
m.value as responder,
t.ts as start_ts,
m.ts as stop_ts,
m.ts - t.ts as duration
from pattern [
every (t=Tweet -> m=Mention(value = t.user))
];](https://image.slidesharecdn.com/codebits-111111114854-phpapp01/85/Complex-Event-Processing-with-Esper-43-320.jpg)
![Detecting Missing Events
// No Tweet from @codebits in 1 hour
select *
from pattern [ every Tweet(user = ‘codebits’) ->
(timer:interval(1 hour) and not Tweet(user = ‘codebits’))
];](https://image.slidesharecdn.com/codebits-111111114854-phpapp01/85/Complex-Event-Processing-with-Esper-44-320.jpg)











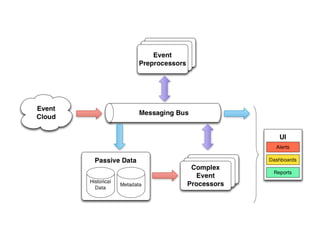
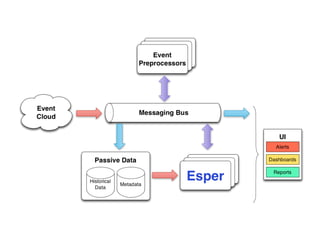
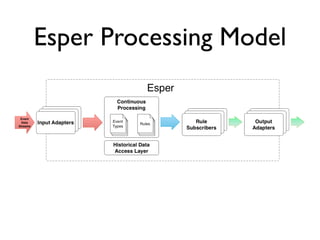
This document provides an overview of complex event processing (CEP) and Esper, an open source CEP engine. It defines CEP as analyzing and controlling interrelated events to understand modern distributed systems. Esper makes it easier to build CEP applications by providing an event processing language (EPL) to define event types, continuous queries, and event patterns similar to SQL. It supports features like filtering, aggregation, windows, correlations, and pattern detection on streaming event data. While powerful, Esper has limitations around memory usage, resilience, and distribution that must be considered.

















![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)





































































