Downloaded 40 times





![CEP Queries 2
Using data from a Football game
Kick stream shows kicks by players on the ball
Ball possession is hit by me, followed by any number of hits by me,
followed by hit by someone else
from every k1 =KickStream,
KickStream[playerid = k1.playerid]*,
KickStream[playerid != k1.playerid]
select ..
insert into BallPosessionStream;](https://image.slidesharecdn.com/copyofwso2bigdatapitch-2015q2-151008153955-lva1-app6892/85/Introduction-to-WSO2-Data-Analytics-Platform-15-320.jpg)


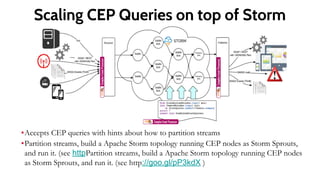
![CEP Queries On Strom
@dist(parallel='4’) ask to run it with 4 nodes
Use partition definition to break the data so they can run in parallel
define partition on TempStream.region {
@dist(parallel='4’)
from TempStream[temp > 33]
insert into HighTempStream;
}
from HighTempStream#window(1h)
select max(temp)as max
insert into HourlyMaxTempStream;](https://image.slidesharecdn.com/copyofwso2bigdatapitch-2015q2-151008153955-lva1-app6892/85/Introduction-to-WSO2-Data-Analytics-Platform-19-320.jpg)


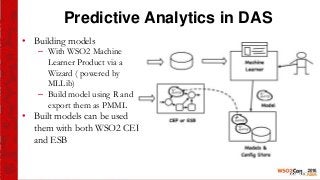


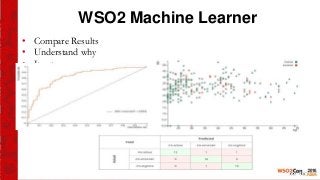


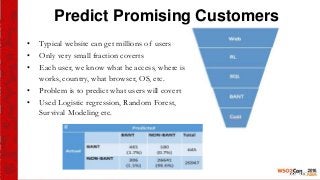

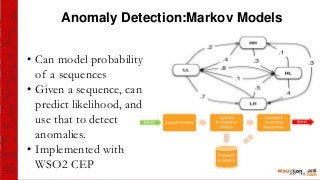
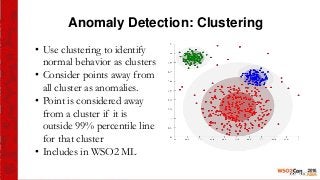





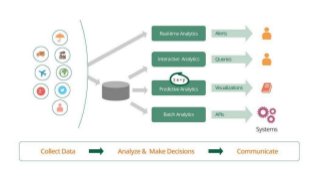


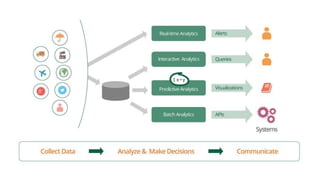
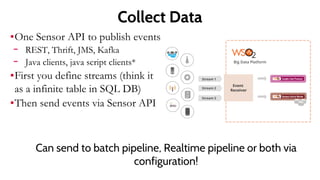
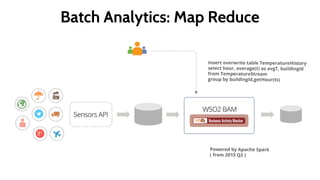
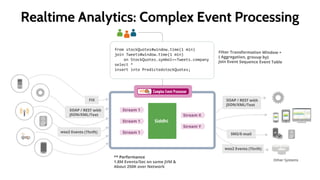
This document provides an introduction to the WSO2 Analytics Platform. It discusses how the platform allows users to collect data from various sources using a sensor API, then perform analysis on the data through both batch and real-time means. Batch analysis uses technologies like Apache Spark and Hadoop to perform tasks like finding averages, max/min, and building KPIs. Real-time analysis uses complex event processing to run queries over streaming data and detect patterns. The platform also enables predictive analytics using machine learning algorithms and anomaly detection. Results are then communicated through dashboards and alerts.




































































































