



















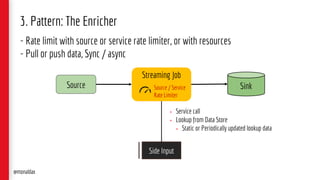
![2. Script UDF* Component
[Static / Dynamic]
*UDF – User Defined Function
@monaldax](https://image.slidesharecdn.com/untitled-190304144547/85/Patterns-of-Streaming-Applications-44-320.jpg)






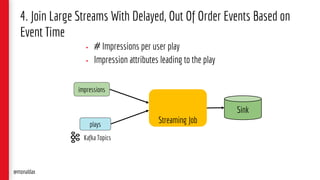
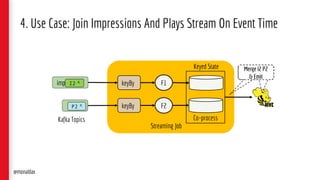
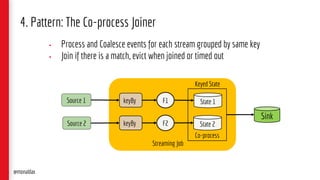




![5. Event-Sourced Materialized View
[Event Driven Application]
@monaldax](https://image.slidesharecdn.com/untitled-190304144547/85/Patterns-of-Streaming-Applications-65-320.jpg)
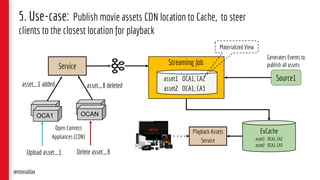
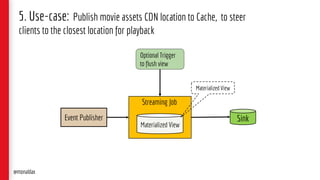

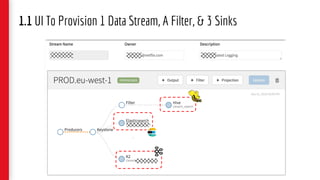
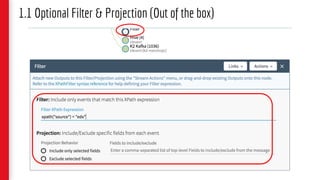
![5. Code Snippet – Union Source & Processing
val kafkaSource
.flatMap(new FlatmapFunction())) //split by movie
.assignTimestampsAndWatermarks(new AssignerWithPunctuatedWatermarks[...]())
.union(fullPublishSource) // union with full publish source
.keyBy(0, 1) // (cdn stack, movie)
.process(new UpdateFunction())) // update in-memory state, output at intervals.
.keyBy(0, 1) // (cdn stack, movie)
.process(new PublishToEvCacheFunction())); // publish to evcache
@monaldax](https://image.slidesharecdn.com/untitled-190304144547/85/Patterns-of-Streaming-Applications-69-320.jpg)




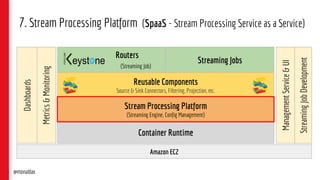

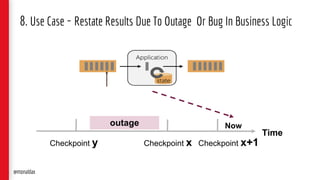
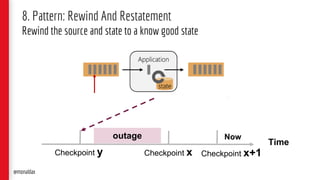






The document presents a detailed overview of streaming applications and architectures, particularly focusing on the use of Apache Flink for stream processing. It highlights the purpose and structure of QCon conferences, showcases various design patterns for stream processing applications, and discusses the significance of low-latency analytics and scalable data processing. Additionally, it provides insights into best practices and use cases from industry leaders like Netflix.







































![[WSO2Con EU 2018] Patterns for Building Streaming Apps](https://cdn.slidesharecdn.com/ss_thumbnails/3-181113092919-thumbnail.jpg?width=640&height=640&fit=bounds)















































