Downloaded 77 times


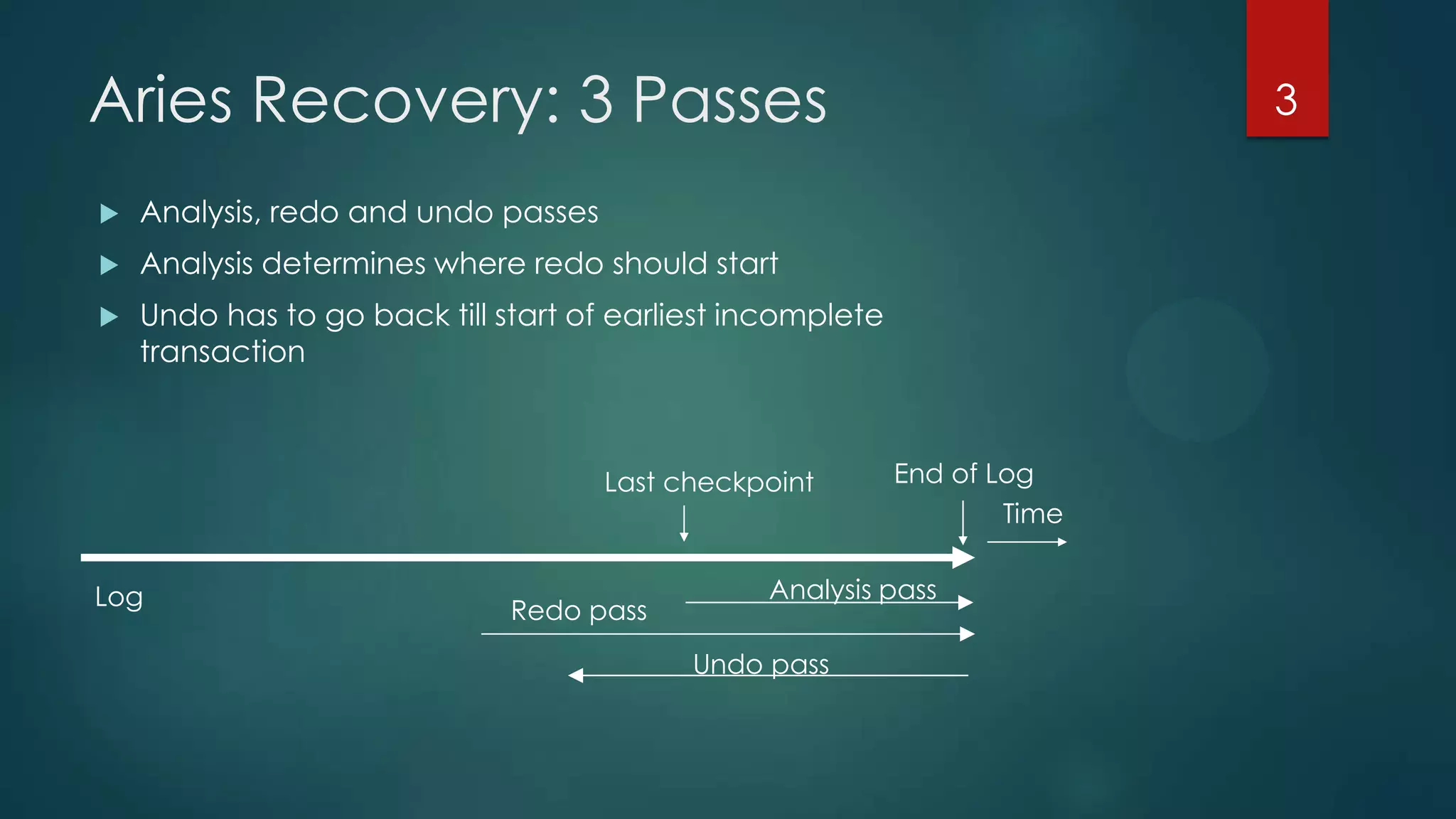



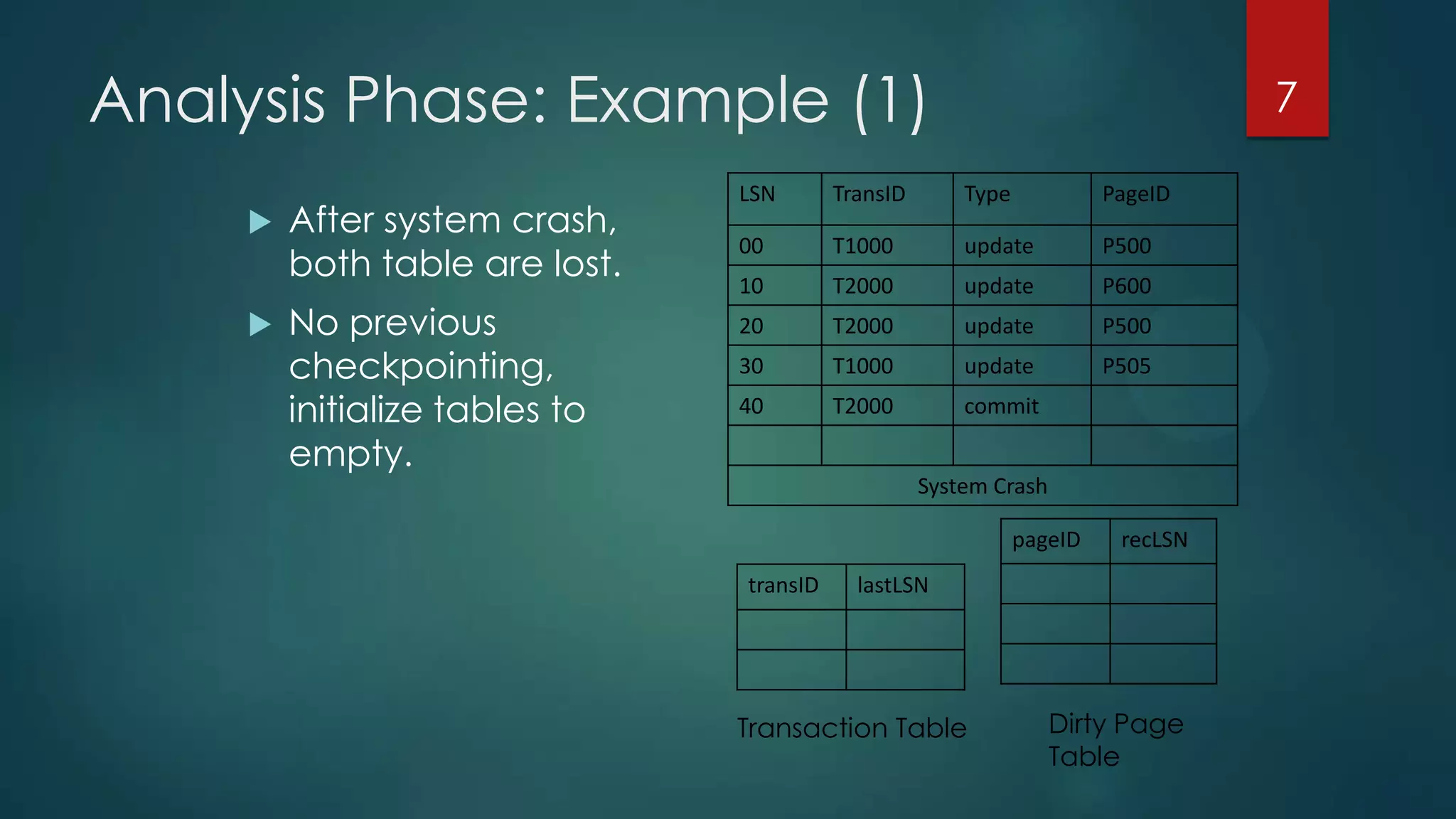
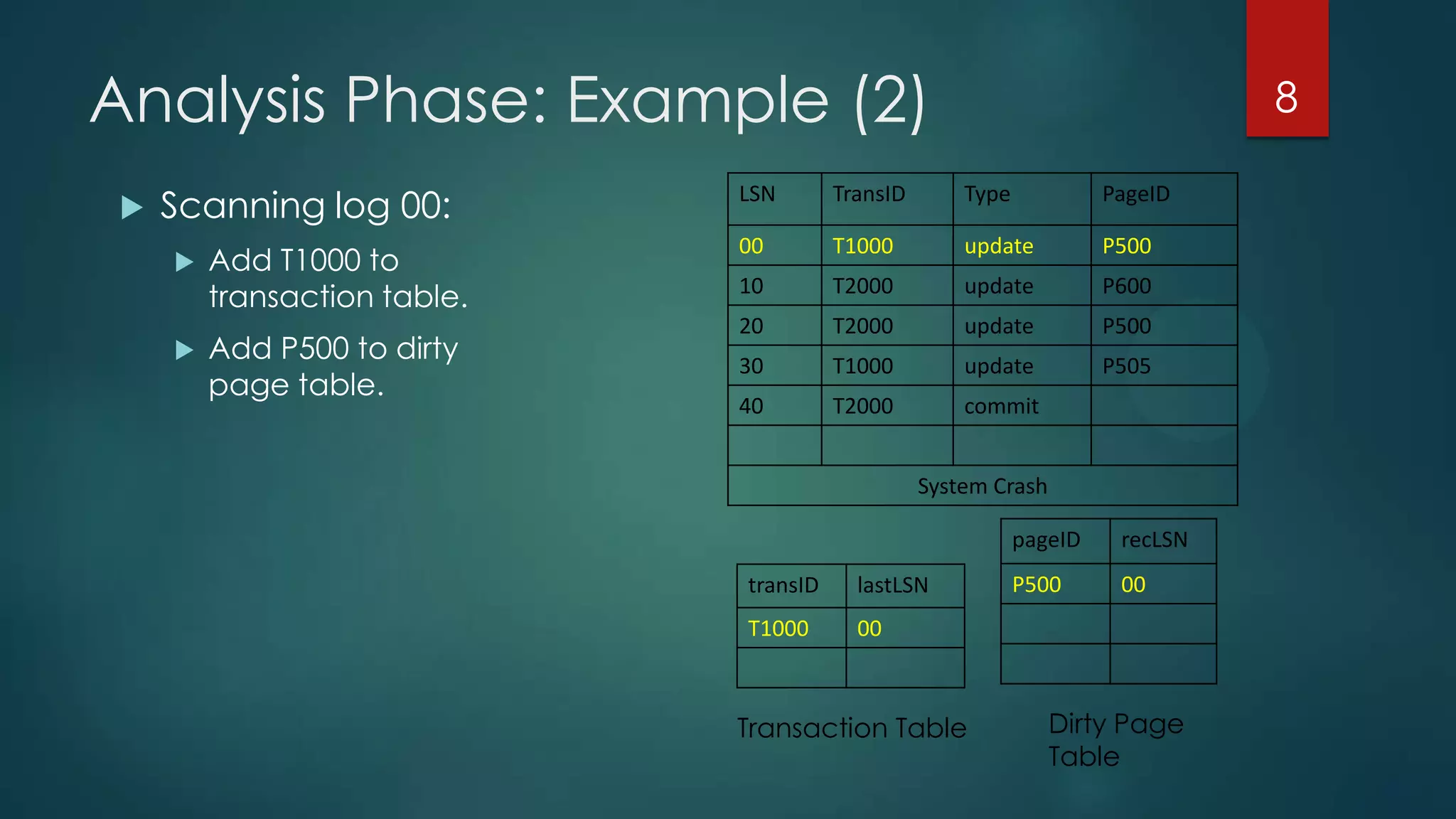






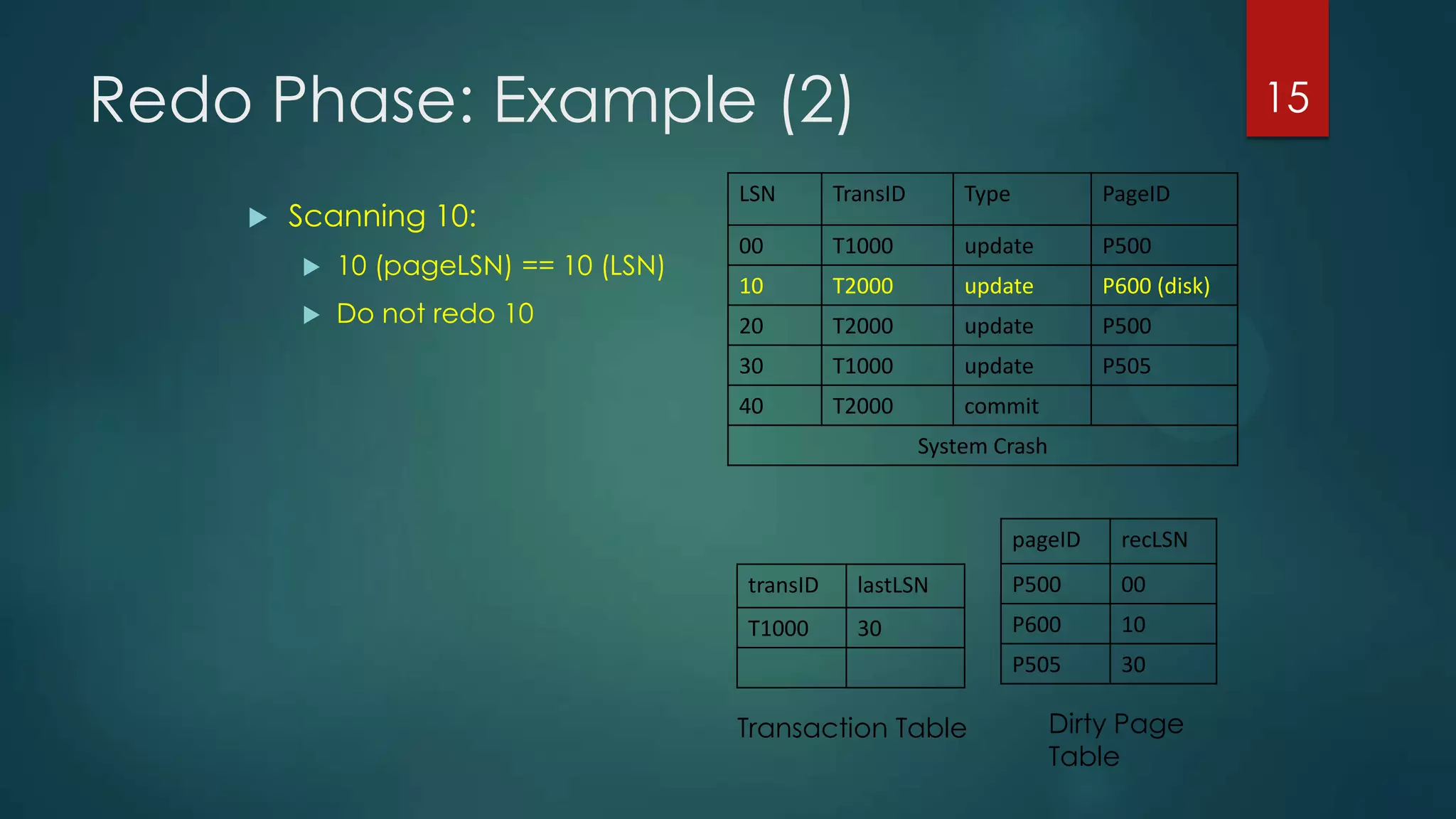







The document describes the ARIES recovery algorithm, which involves three passes - analysis, redo, and undo. The analysis pass scans the log from the most recent checkpoint and determines which transactions need to be undone, which pages were dirty at the time of crash, and the redo start point. The redo pass repeats history by redoing log records from the redo start point. The undo pass rolls back incomplete transactions by scanning the log backwards and undoing actions of uncommitted transactions.





























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













