This document discusses optimizing code for ARM architectures. It provides information on various ARM platforms used in devices like the GameBoy Advance, Nintendo DS, Nintendo DSi, Nintendo 3DS, PlayStation Vita, Apple devices and Android. It outlines key features of ARM architectures like multiple instruction sets, variable cycle execution, load/store multiple instructions and DSP/SIMD extensions. It also provides tips for optimizing code like using 32-bit data types, avoiding pointer aliasing, improving loop unrolling and counting down in loops where possible.


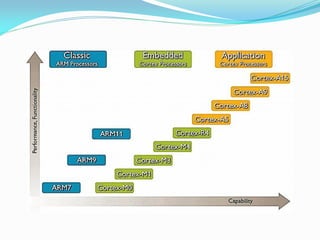

![ARM platforms
PlayStation Vita
ARM Cortex-A9 MPCore (ARMv7)
Apple iPhone/iPod/iPad
ARM1176JZ(F)-S (ARMv6)
ARM Cortex-A8 [Apple 4] (ARMv7)
ARM Cortex-A9 [Apple 5] (ARMv7)
Android](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-4-320.jpg)



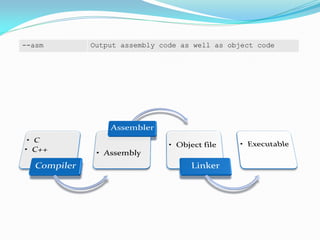

![--asm Output assembly code as well as object code
-S Output assembly code instead of object code
--interleave Interleave source with disassembly
(use with --asm or -S)
;;;22 // calculate a point on a quadratic Bezier curve
;;;23 Vector2f math::bezier(const Vector2f& a, const Vector2f& b, const Vector2f& c, const f32 t)
000000 ed9f1a16 VLDR s2,|L5.96|
;;;24 {
;;;25 const f32 tInv = 1 - t;
;;;26 const f32 tInvSq = tInv * tInv;
;;;27 const f32 tSq = t * t;
;;;28 const f32 t2tInv = (t * 2) * tInv;
000004 eddf0a16 VLDR s1,|L5.100|
000008 edd22a00 VLDR s5,[r2,#0]
00000c ee311a40 VSUB.F32 s2,s2,s0 ;25
000010 ee601a20 VMUL.F32 s3,s0,s1
000014 ee200a00 VMUL.F32 s0,s0,s0 ;27
000018 ee610a01 VMUL.F32 s1,s2,s2 ;26
00001c ee211a81 VMUL.F32 s2,s3,s2
.
.
.
000054 ed801a00 VSTR s2,[r0,#0]
000058 ed800a01 VSTR s0,[r0,#4]
;;;29
;;;30 return tInvSq * a + t2tInv * b + tSq * c;
;;;31 }
00005c e12fff1e BX lr](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-11-320.jpg)




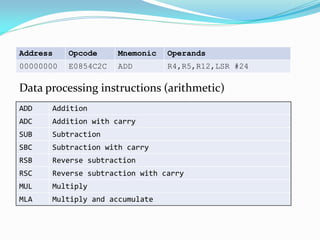
![Address Opcode Mnemonic Operands
00000000 E1D000F0 LDRSH R0,[R0,#0]
Register Load and Store instructionsLDR Load register from memory
STR Store register to memory
LDM Load multiple registers (32-bit aligned!)
STM Store multiple registers (32-bit aligned!)
Register Load and Store instructions
B Byte (8-bit)
SB Signed byte (8-bit)
H Half word (16-bit)
SH Signed half word (16-bit)
D Double word (64-bit)](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-16-320.jpg)










![[Tip!] Use do {} while
Use do-while loops when the initial test isn’t required
Tip: replace initial test with an ‘assert(n > 0)’](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-28-320.jpg)
![[Tip!] Count down loops
Count down in loops
where possible
int i = n - 1;
do
{
// ...
} while(--i >= 0);](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-29-320.jpg)



![[Tip!] Improve Loop Unrolling
Intrinsic Description
__promise Allows the compiler to optimize loop unrolling
(also improves NEON vectorization)
// Promise the compiler that the loop
// iteration count is divisible by 16
__promise((n % 16) == 0);
for (int i = 0; i < n; i++)
{
// ...
}](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-33-320.jpg)



![Pointer Aliasing
A compiler must assume two pointers could point to
the same location.
LDR r2,[r0,#0] ; load this->mAge
LDR r3,[r1,#0] ; load state.deltaTime
; interlock
ADD r2,r2,r3 ; mAge += state.deltaTime
STR r2,[r0,#0] ; store updated mAge
LDR r1,[r1,#0] ; reload state.deltaTime
LDR r2,[r0,#4] ; load this->mDelay
; interlock
SUB r1,r2,r1 ; mDelay -= state.deltaTime
STR r1,[r0,#4] ; store updated mDelay
BX lr ; return](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-37-320.jpg)


![Pointer Aliasing
Do not dereference multiple times; cache the value in a
local.
Or use __restrict to promise the compiler that a
pointer does not alias other pointers.
This improves code generation tremendously!
LDR r12,[r1,#0] ; load state.deltaTime
LDM r0,{r2, r3} ; load mAge, mDelay
ADD r2,r2,r12 ; mAge += state.deltaTime
SUB r3,r3,r12 ; mDelay -= state.deltaTime
STM r0,{r2, r3} ; store mAge, mDelay
BX lr ; return](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-40-320.jpg)





![[Tip!] Function arguments
bool Object::hit(int type, int damage, Object* pSource)
{
// R0 = this
// R1 = type
// R2 = damage
// R3 = pSource
...
// R0 = true
return true
}
Do not pass more than four 32-bit (integer) arguments
Non-static class member functions: 3 arguments
(this pointer counts as argument)](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-46-320.jpg)
![[Tip!] Function arguments
s64 dontDoThis(s32 a, s64 b, s32 c)
{
// R0 = a
// R1
// R2, R3 = b
// [SP+0] = c
return a + b + c;
// R0, R1 = result
}
64-bit arguments require two registers
Must use R0, R1 or R2, R3](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-47-320.jpg)
![[Tip!] Function arguments
s64 Object::rememberThis(s64 b, s32 a)
{
// R0 = this
// R1
// R2, R3 = b
// [SP+0] = a
return a + b + this->c;
// R0, R1 = result
}
64-bit arguments require two registers
Must use R0, R1 or R2, R3
Member functions: this pointer alert!](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-48-320.jpg)
![[Tip!] Function arguments
s64 Object::rememberThis(s32 a, s64 b)
{
// R0 = this
// R1 = a
// R2, R3 = b
return a + b + this->c;
// R0, R1 = result
}
64-bit arguments require two registers
Must use R0, R1 or R2, R3
Member functions: this pointer alert!](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-49-320.jpg)

![[Tip!] Use 32 bits!
Use 32 bits (or multiples thereof) for:
Arguments
Locals
Return values
When using smaller types compiler has to take care of:
Wrap-around
Sign-extension](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-51-320.jpg)
![[Tip!] Use 32 bits!
short addRange(short a, short b, short* pData)
{
short result = 0;
do
{
result += pData[a++];
}
while (a <= b);
return result;
}](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-52-320.jpg)
![[Tip!] Use 32 bits!
MOV r3,#0
|Loop|
ADD r12,r2,r0,LSL #1
LDRH r12,[r12,#0]
ADD r0,r0,#1
LSL r0,r0,#16 ; wrap-around and...
ADD r3,r3,r12
ASR r0,r0,#16 ; sign-extend
LSL r3,r3,#16
CMP r0,r1
ASR r3,r3,#16
MOVGT r0,r3
BLE |Loop|
BX lr](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-53-320.jpg)
![[Tip!] Use 32 bits!
MOV r3,#0
|Loop|
ADD r12,r2,r0,LSL #1
ADD r0,r0,#1
LDRH r12,[r12,#0]
SXTH r0,r0 ; sign-extend halfword
CMP r0,r1
ADD r3,r3,r12
SXTH r3,r3
MOVGT r0,r3
BLE |Loop|
BX lr
ARMv6](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-54-320.jpg)




![[Tip!] Signed vs Unsigned
int dividedByPower2(int d)
{
return d / 512;
}
ASR r1,r0,#31
ADD r0,r0,r1,LSR #23
ASR r0,r0,#9
BX lr
int moduloPower2(int d)
{
return d % 4;
}
ASR r1,r0,#31
ADD r1,r0,r1,LSR #30
BIC r1,r1,#3
SUB r0,r0,r1
BX lr
Signed division and modulus are more complicated
Exception: -1 >> 1 == -1](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-59-320.jpg)
![[Tip!] Signed vs Unsigned
LSR r0,r0,#9
BX lr
u32 moduloPower2(u32 d)
{
return d % 4U;
}
AND r0, r0, #3
BX lr
Signed division and modulus are more complicated
Exception: -1 >> 1 == -1
Use unsigned types where applicable!
u32 dividedByPower2(u32 d)
{
return d / 512U;
}](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-60-320.jpg)
![[Tip!] Signed vs Unsigned
ASR r1,r0,#31
ADD r0,r0,r1,LSR #23
ASR r0,r0,#9
BX lr
int moduloPower2(int d)
{
return d % 4;
}
ASR r1,r0,#31
ADD r1,r0,r1,LSR #30
BIC r1,r1,#3
SUB r0,r0,r1
BX lr
Signed division and modulus are more complicated
Exception: -1 >> 1 == -1
Use unsigned types where applicable!
int dividedByPower2(int d)
{
return d / 512;
}](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-61-320.jpg)
![[Tip!] Signed vs Unsigned
LSR r0,r0,#9
BX lr
u32 moduloPower2(u32 d)
{
return d % 4U;
}
AND r0, r0, #3
BX lr
Signed division and modulus are more complicated
Exception: -1 >> 1 == -1
Use unsigned types where applicable!
u32 dividedByPower2(u32 d)
{
return d / 512U;
}](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-62-320.jpg)









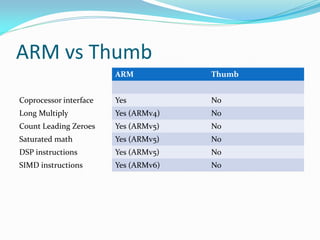
![ARM vs Thumb
ARM Thumb
Conditional execution Nearly all instructions Branch instructions
bool isLetter(int c)
{
return ((c >= 'A' && c <= 'Z') ||
(c >= 'a' && c <= 'z'));
}
MOV r1,r0
SUBS r1,r1,#’A’
CMP r1,#’Z’ – ‘A’
BLS |True|
SUBS r0,r0,#’a’
CMP r0,#’z’ – ‘a’
BHI |False|
|True|
MOVS r0,#1
BX lr
|False|
MOVS r0,#0
BX lr
Note: the compiler must ensure type bool is true
(1) or false (0). Avoid [implicit] casting to bool
when it’s not required, as it’s expensive!](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-72-320.jpg)
![[Tip!] Boolean type
bool isBitSet(int flags, int bit)
{
return flags & (1 << bit);
}
Note: the compiler must ensure type bool is true
(1) or false (0). Avoid [implicit] casting to bool
when it’s not required, as it’s expensive!
int isBitSet(int flags, int bit)
{
return flags & (1 << bit);
}
MOVS r2,#1
LSLS r2,r2,r1
TST r2,r0
BEQ |False|
MOVS r0,#1
BX lr
|False|
MOVS r0,#0
BX lr
MOV r2,r0
MOVS r0,#1
LSLS r0,r0,r1
ANDS r0,r0,r2
BX lr](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-73-320.jpg)









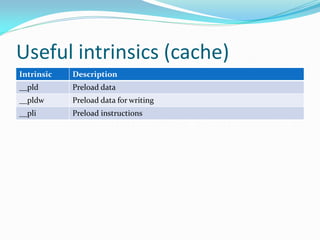

![Useful intrinsics (SIMD)
Intrinsic Description
__usad[a]8|16 Sum of absolute differences (4x8, 2x16)
__[u][q]add8|16 [Saturated] addition (4x8, 2x16)
__[u][q]sub8|16 [Saturated] subtraction (4x8, 2x16)
etc. Check: http://infocenter.arm.com/help](https://image.slidesharecdn.com/38158937-207d-477d-bfe0-52a5d12bae24-150320205004-conversion-gate01/85/OptimizingARM-86-320.jpg)


























![RF Module Design - [Chapter 8] Phase-Locked Loops](https://cdn.slidesharecdn.com/ss_thumbnails/rfch8-150613070348-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
























