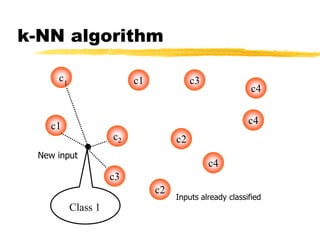
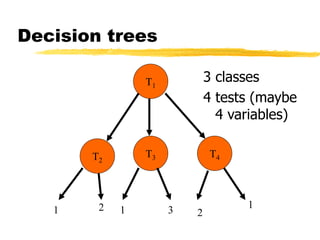
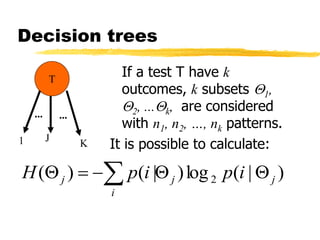
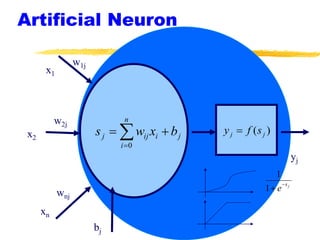
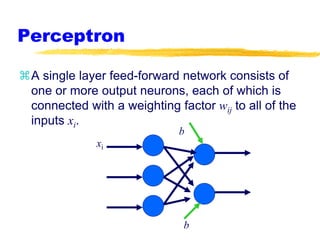
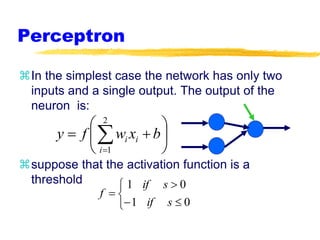
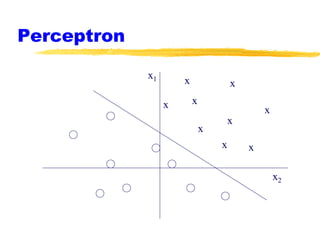
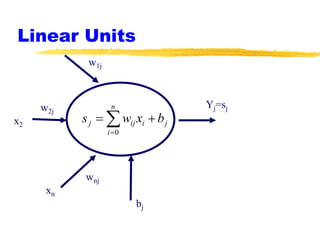
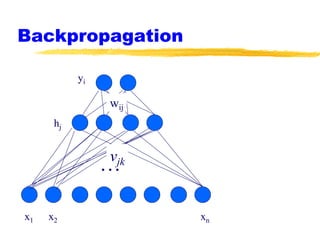
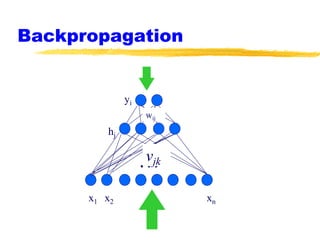
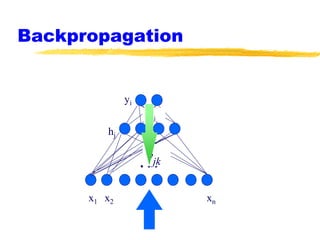
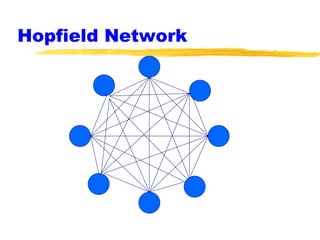
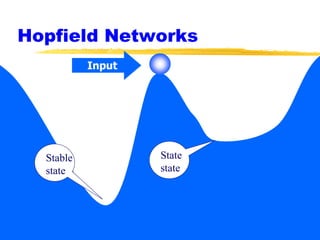
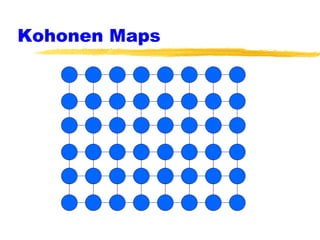
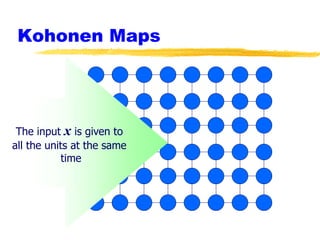
Machine learning and neural networks are discussed. Machine learning investigates how knowledge is acquired through experience. A machine learning model includes what is learned (the domain), who is learning (the computer program), and the information source. Techniques discussed include k-nearest neighbors algorithm, Winnow algorithm, naive Bayes classifier, decision trees, and reinforcement learning. Reinforcement learning involves an agent interacting with an environment to optimize outcomes through trial and error.













































































































































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)


















