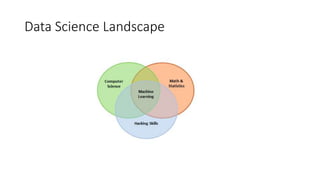
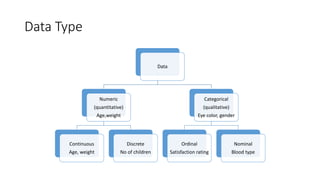
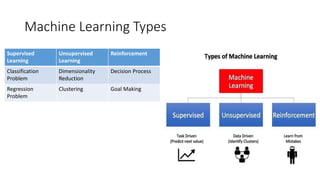
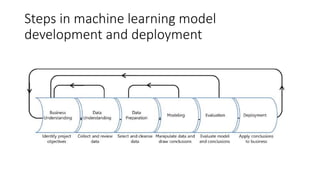
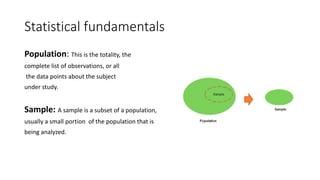
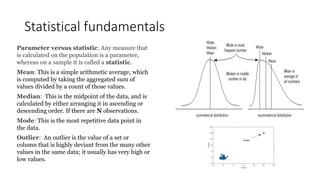
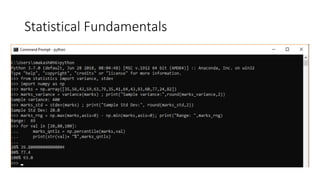
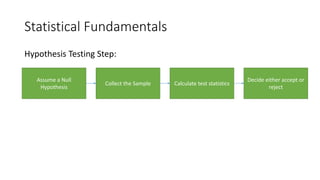
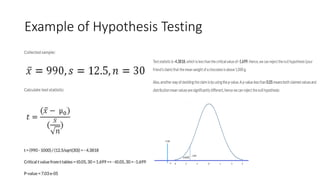
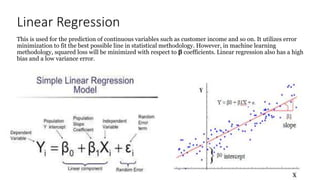
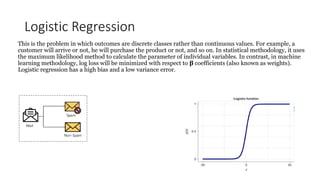
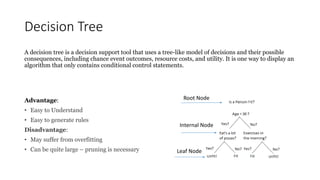
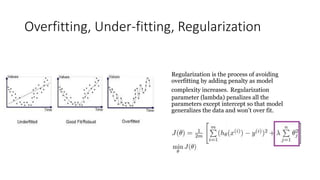
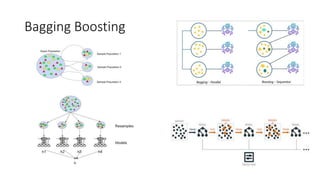
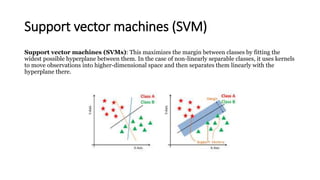
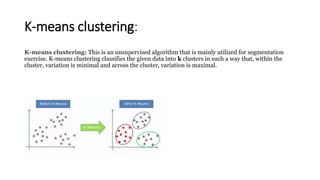
This document provides an overview of key concepts in statistics, machine learning, and data science. It discusses topics such as populations and samples, parameters and statistics, measures of central tendency and variation, hypothesis testing, linear and logistic regression, decision trees, overfitting and regularization, bagging and boosting, and random forests. The document also provides examples to illustrate statistical fundamentals like hypothesis testing, one sample t-tests, and type I and II errors.