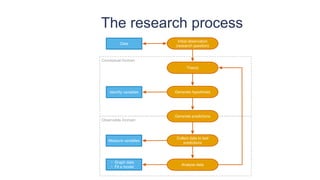
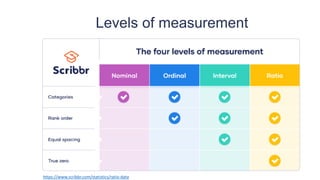
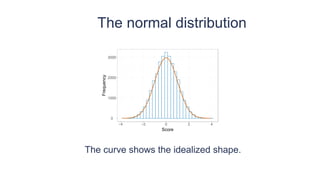
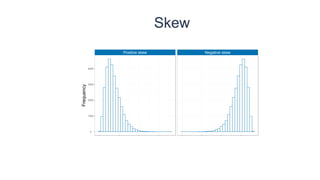
This document provides an overview of key concepts in statistical analysis and research methods. It discusses different types of data and variables, levels of measurement, validity and reliability, experimental and correlational research designs, measures of central tendency and dispersion, the normal distribution, hypothesis testing, and types of errors. It also covers effect sizes, correlations, and misconceptions about p-values and statistical significance. The document is serving as a learning module to help prepare students for quantitative methods and research.

























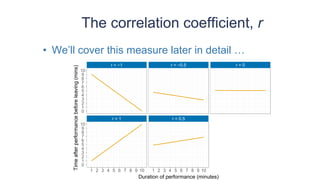
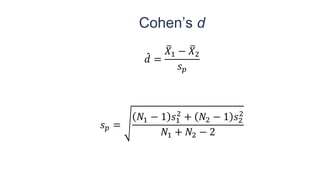


![Statistics Chapter 01[1]](https://cdn.slidesharecdn.com/ss_thumbnails/statistics-chapter011-1295487514-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













































