Download to read offline





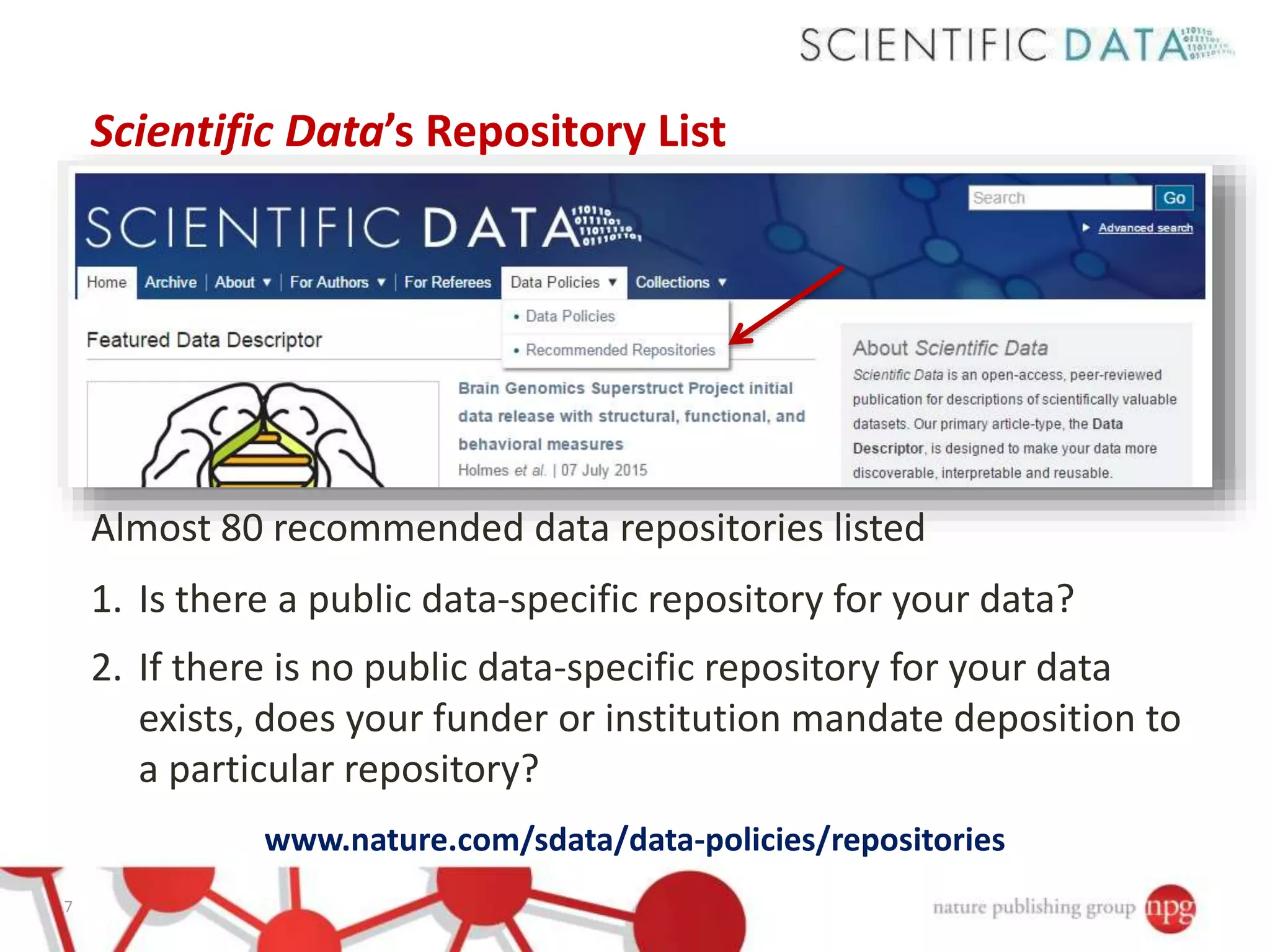






Varsha Khodiyar discussed data publishing and institutional repositories. Data papers allow data producers to receive credit and make data reuse easier by including details about what was done to generate the data, how it was processed, its location, who was involved and technical analyses supporting its quality. Unlike traditional articles, data papers do not contain new scientific hypotheses testing. Scientific Data publishes both a human-readable article and machine-accessible metadata. It recommends data repositories and allows authors to use their institution's repository when submitting, obtaining a DataCite DOI. Repositories are evaluated based on recognition, preservation plans, community standards implementation, stable identifiers and open access without commercial use restrictions.


























































































