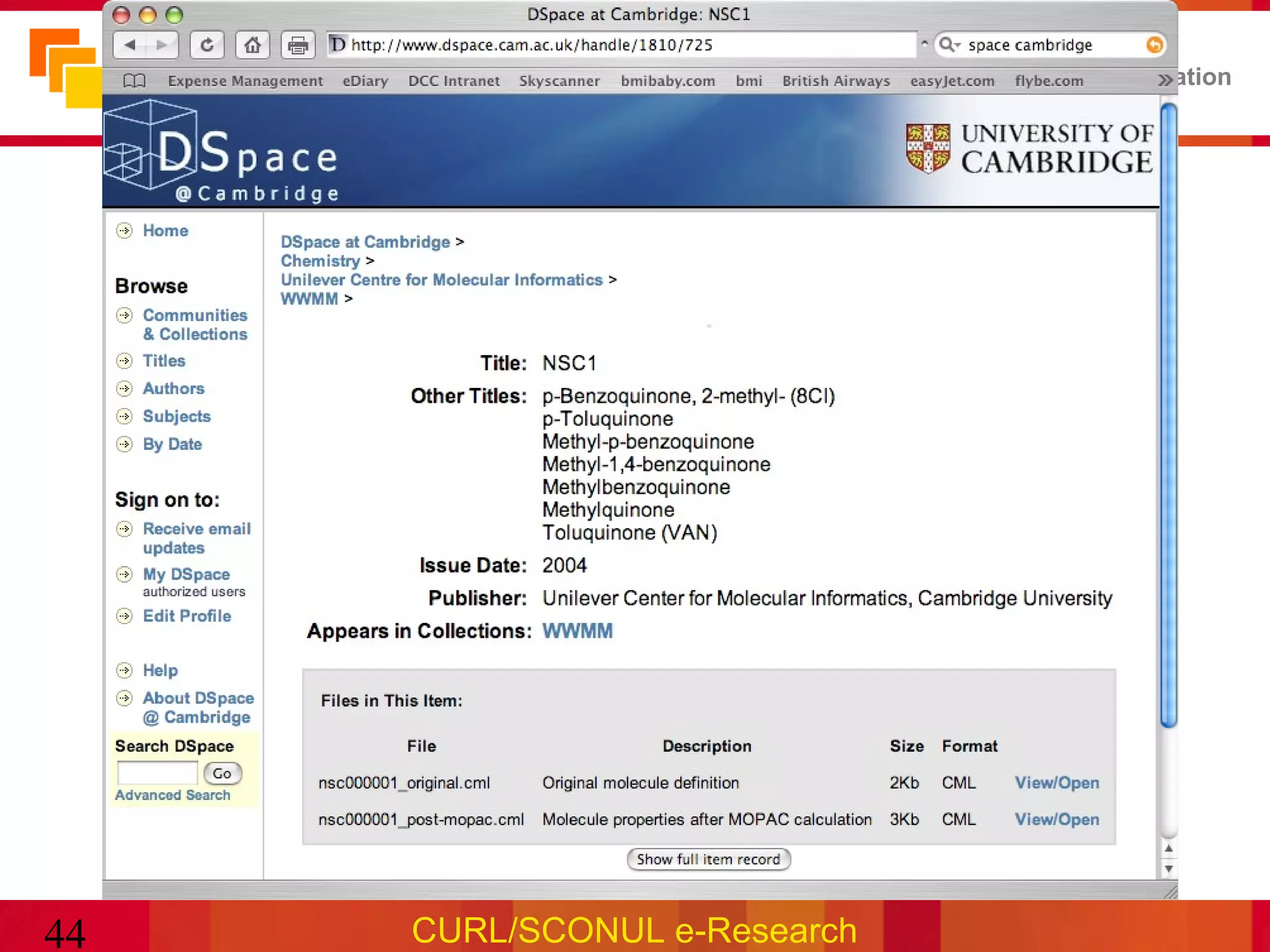
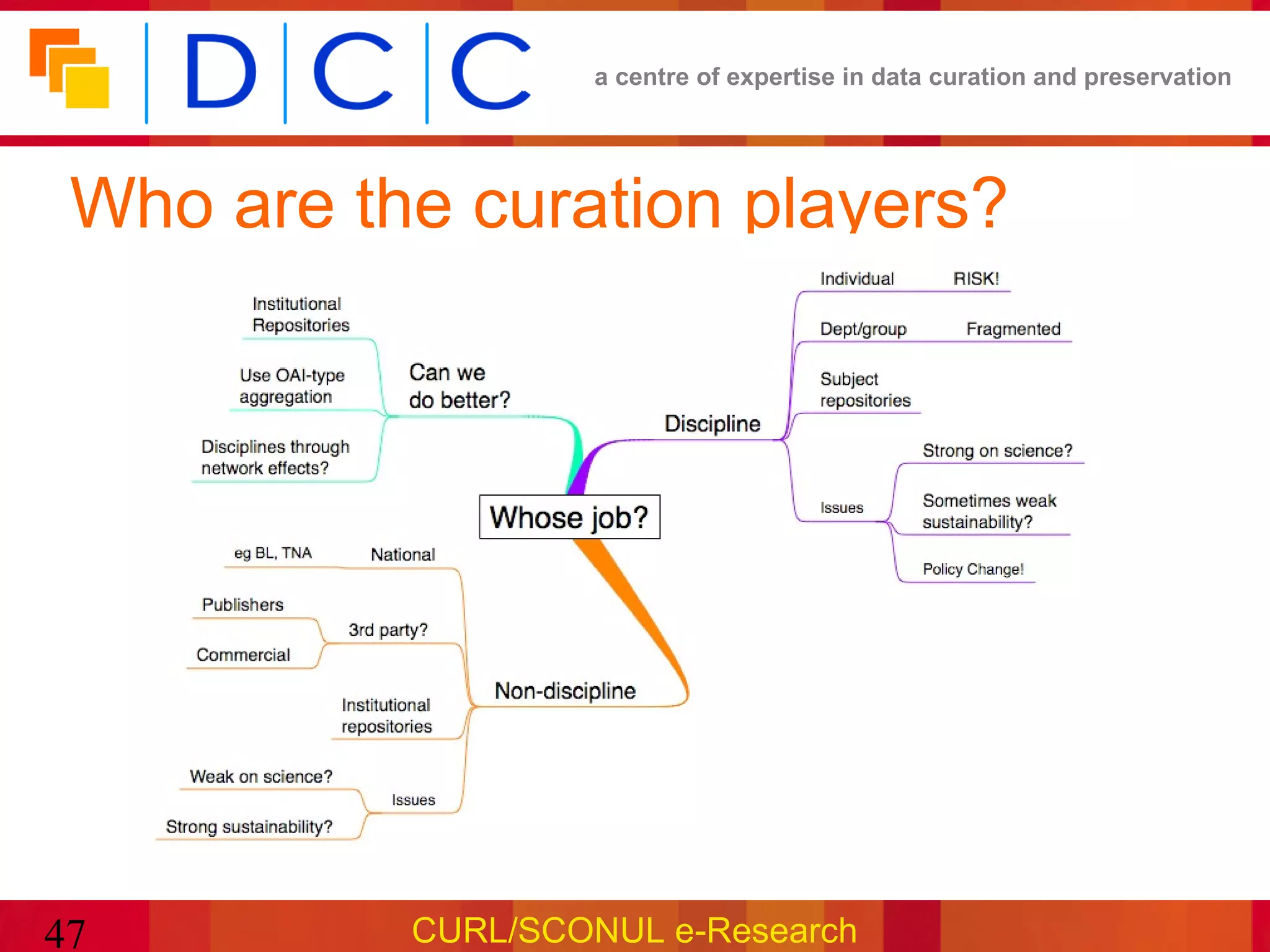
The document discusses the role of research libraries in curating and preserving data. It notes that data is increasingly important as evidence in science but poses new challenges compared to traditional scholarly literature. Research libraries are well positioned to help address these challenges by building infrastructure to curate and provide access to institutional research data over the long term. However, doing so effectively will require skills in domain knowledge, metadata practices, and digital preservation that differ from traditional library roles.









































![a centre of expertise in data curation and preservation
AHDS
• “AHRC Council has decided to cease funding the Arts and
Humanities Data Service (AHDS) from March 2008. […] Grant
holders must make materials they had planned to deposit with the
AHDS available in an accessible depository for at least three years
after the end of their grant”
• AHRC Press Release 14/05/2007
• (Note petition at http://petitions.pm.gov.uk/AHDSfunding/)
• Does not apply to Archaeology: ADS still funded?
• “Council believes that long term storage of digital materials and
sustainability is best dealt with by an active engagement with HEIs
rather than through a centralised service”
• “JISC has decided that it is unable to fund the service alone and
that therefore its own funding of the service will, in its current form,
cease on the same date. […] exploring with the AHDS … and the
wider community alternative approaches to maintaining strong
support for that community beyond March 2008”
• JISC Press Release 13/06/2007
48 CURL/SCONUL e-Research](https://image.slidesharecdn.com/dcc-curl-sconul-e-research-120925081110-phpapp02/75/Saving-private-data-sharing-Open-Data-Role-of-libraries-and-institutional-repositories-in-a-data-world-48-2048.jpg)




































































































