Download to read offline



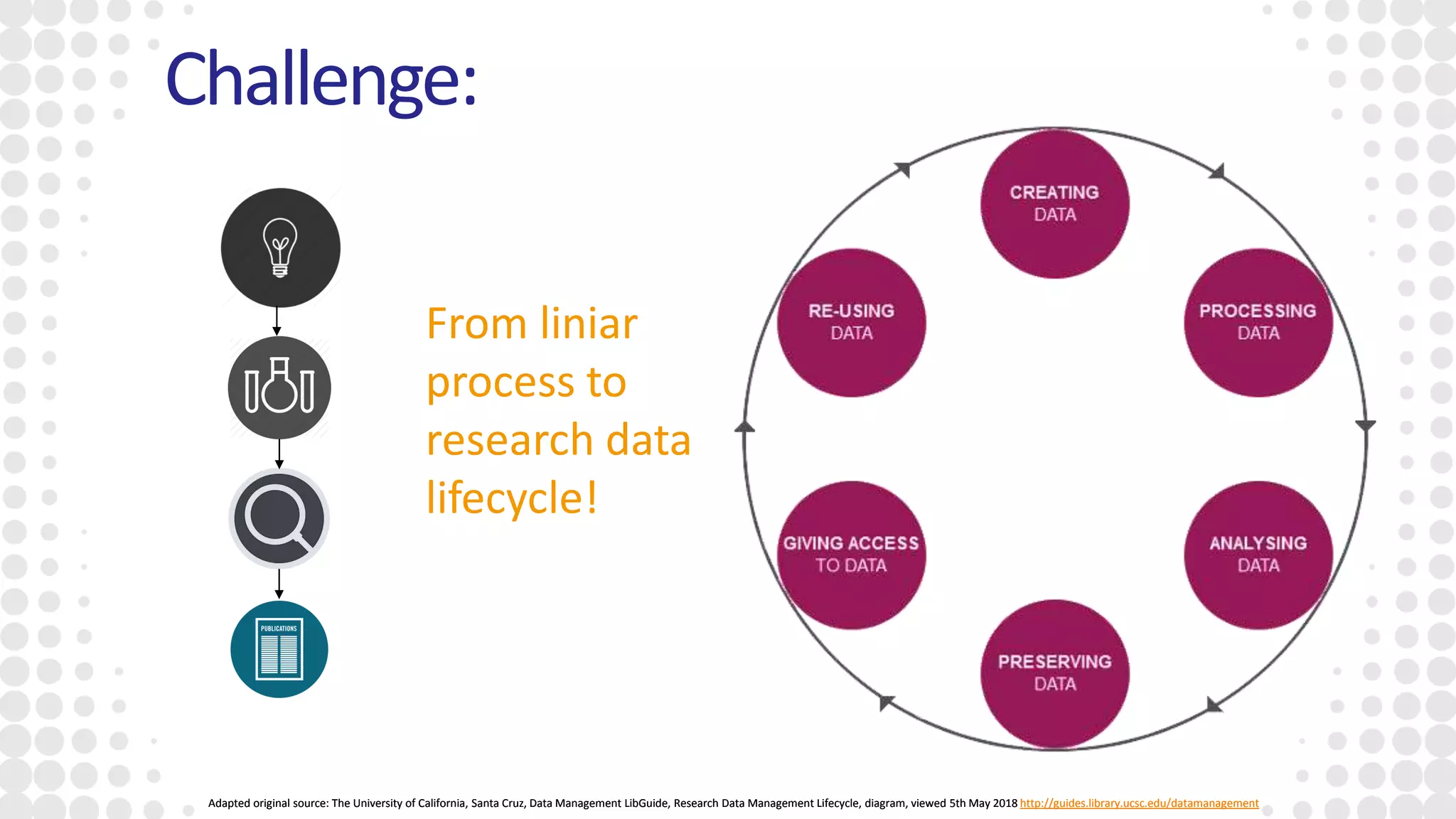




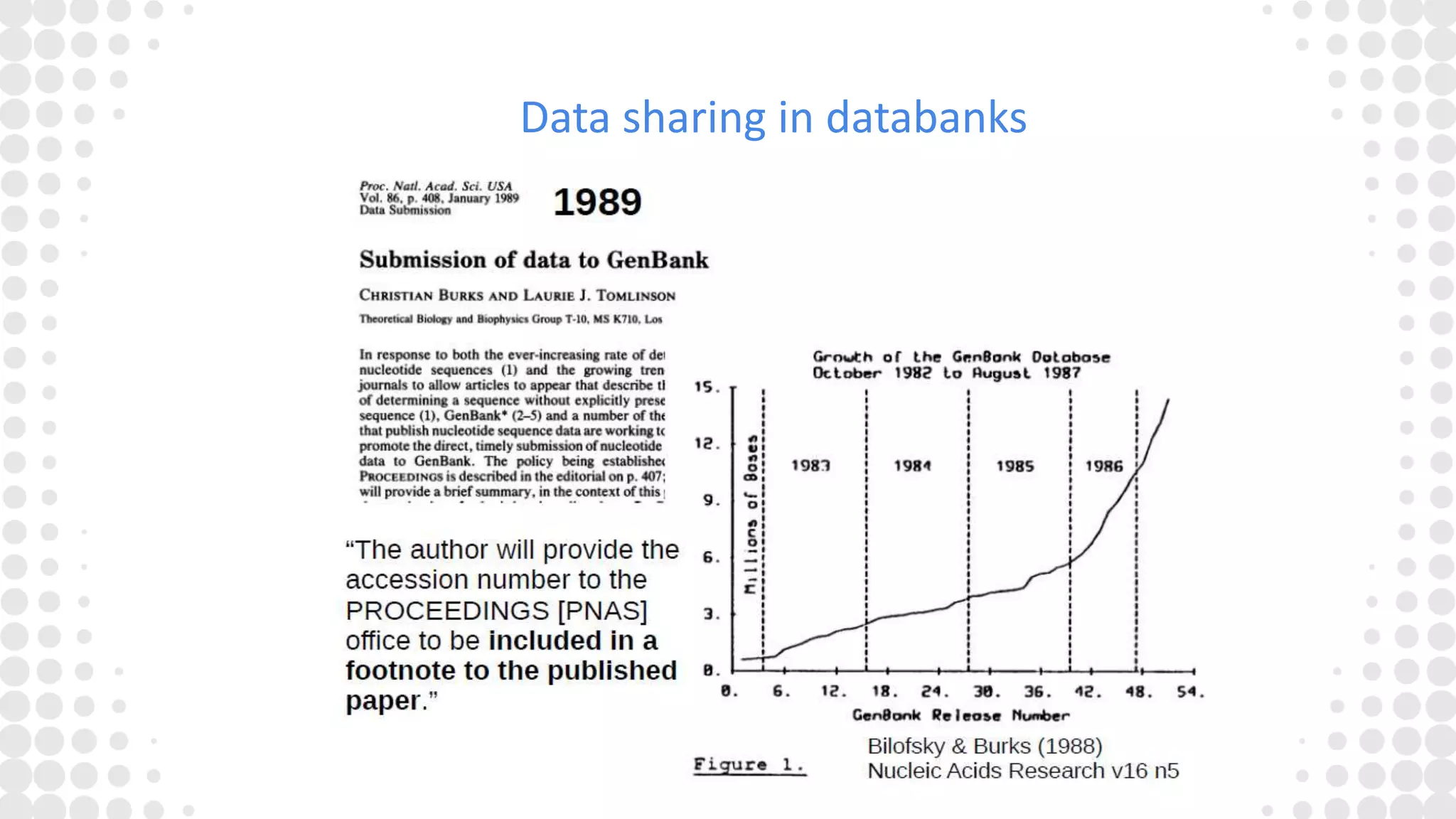






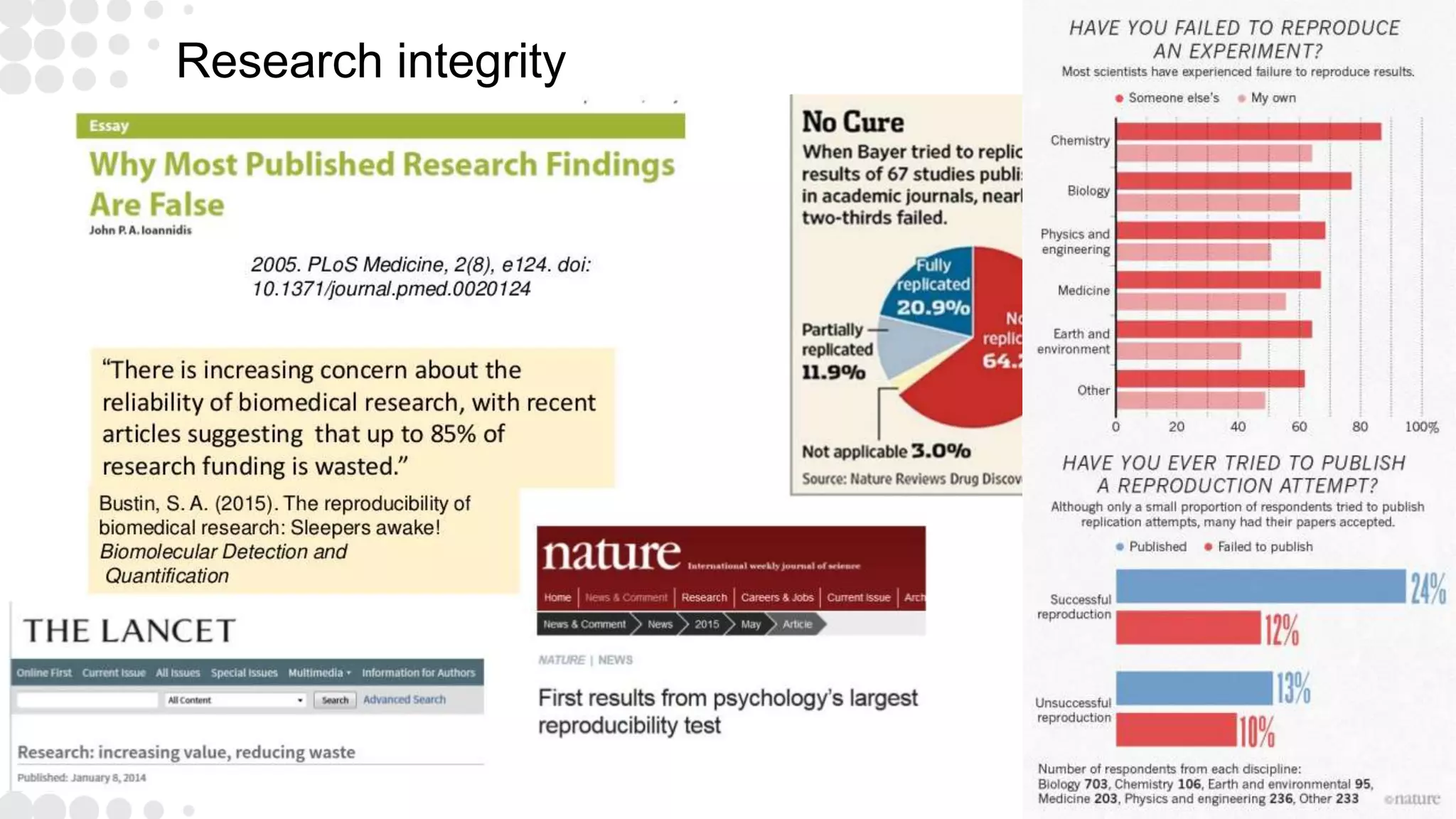

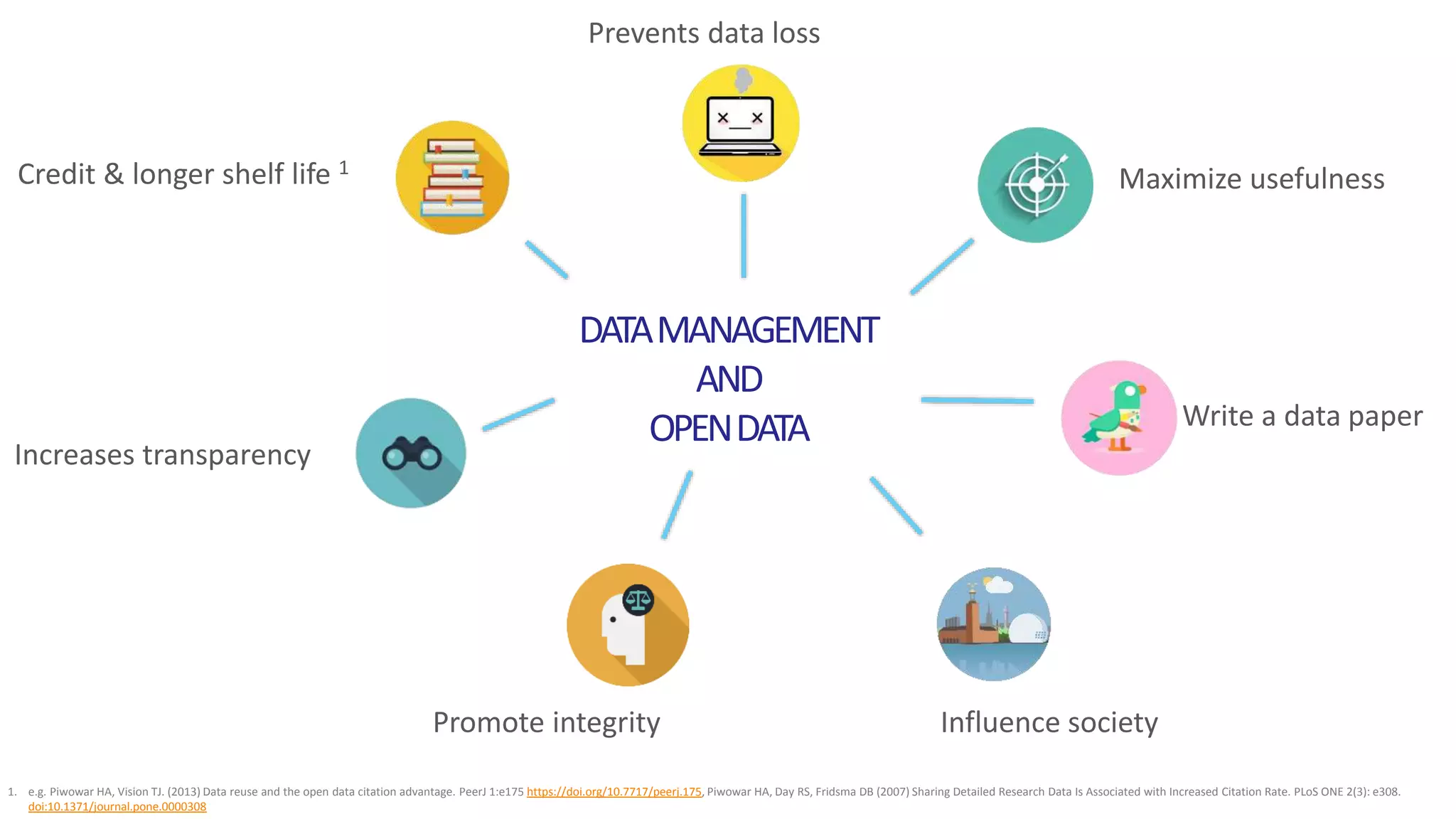




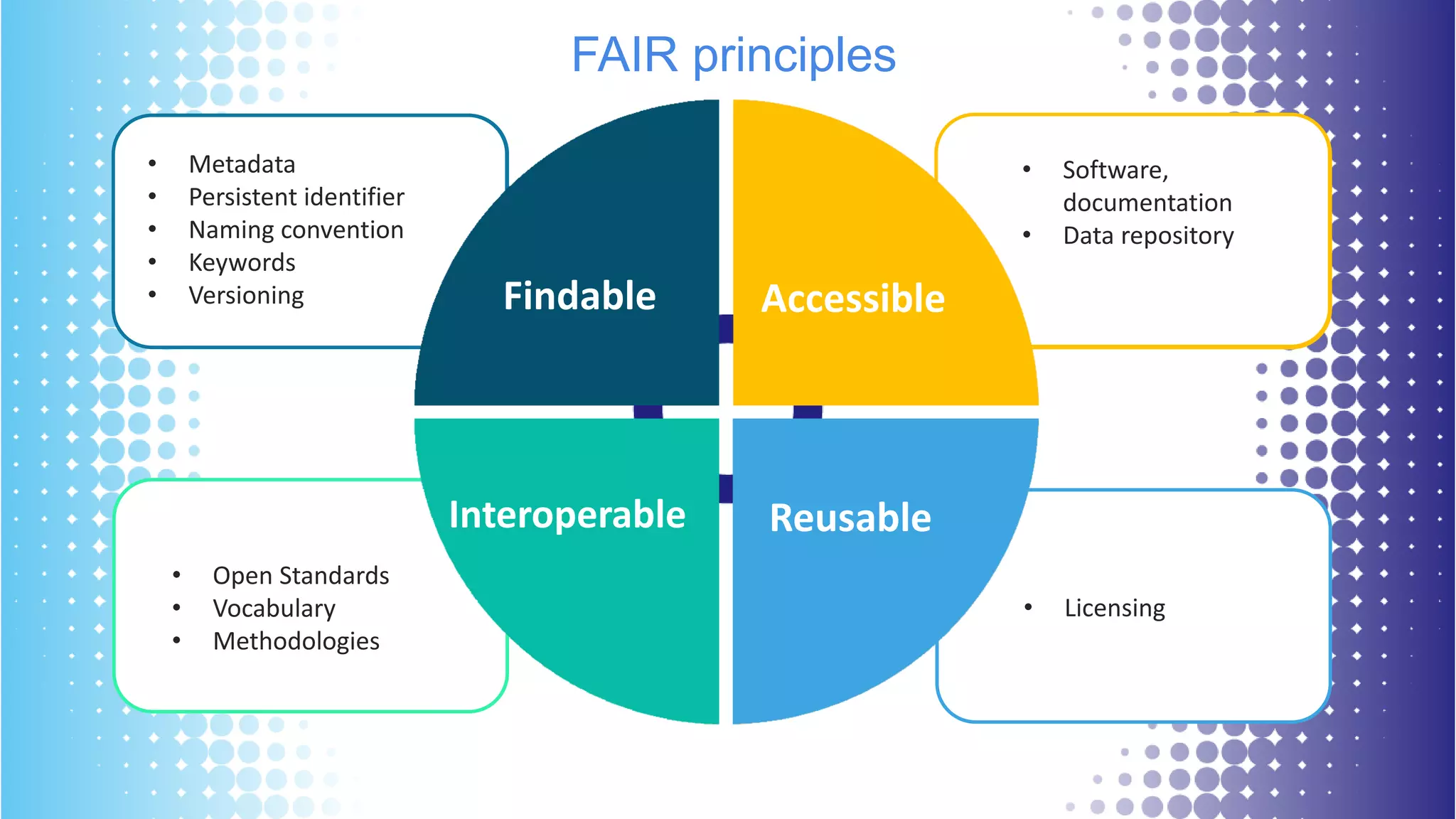

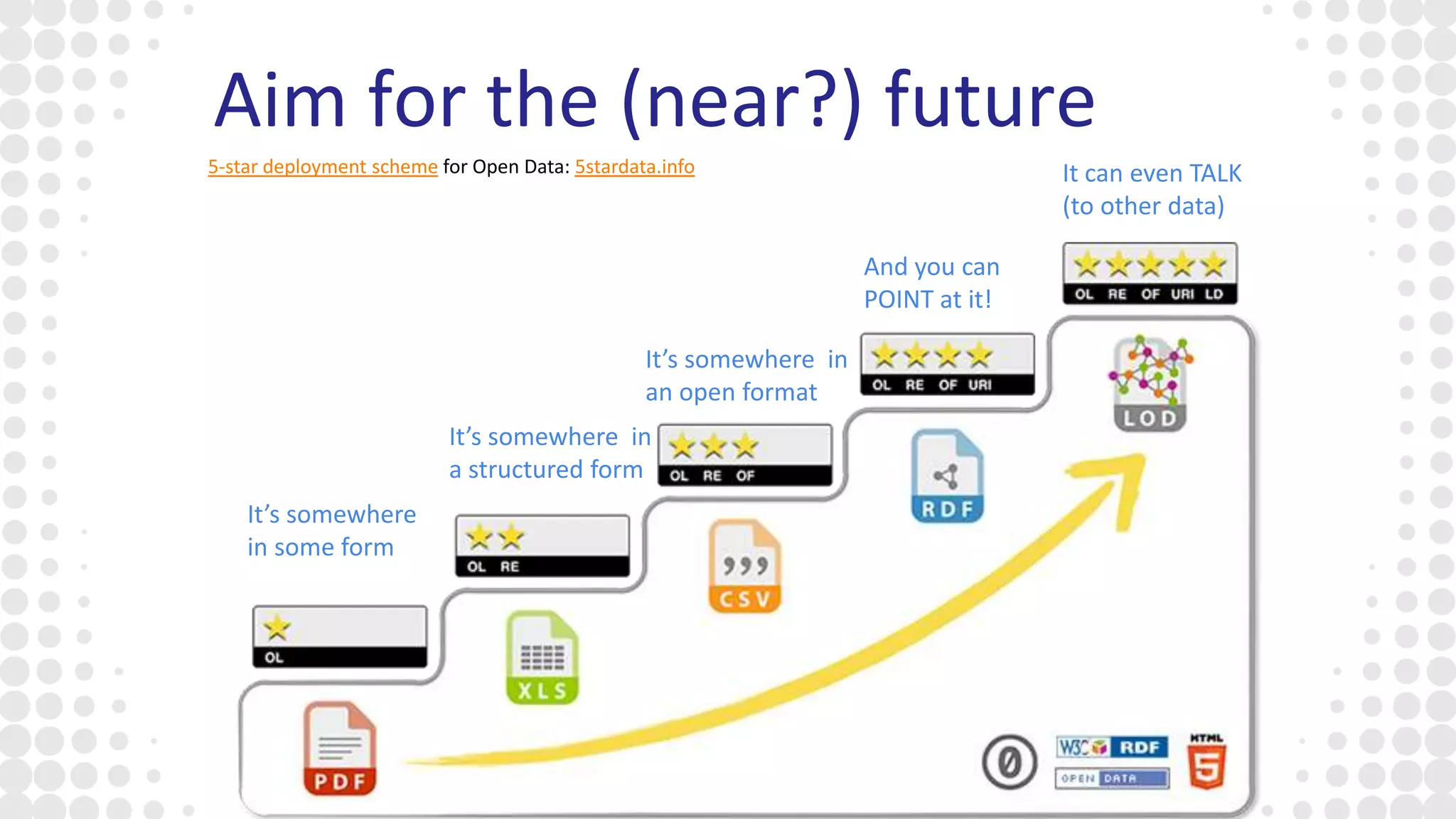




The document discusses the state of open research data, emphasizing the importance of data accessibility, sharing, and integrity in research. It highlights the transition from data management processes to the research data lifecycle and offers insights on best practices, including adherence to FAIR principles. The author advocates for mandatory data sharing, improved training, and the crucial role of data in maintaining research transparency and progress.























































































