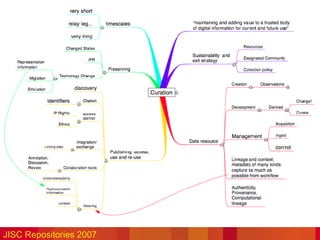
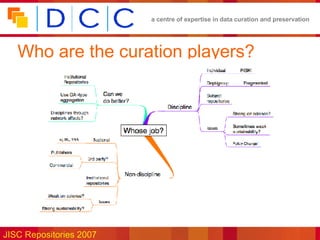
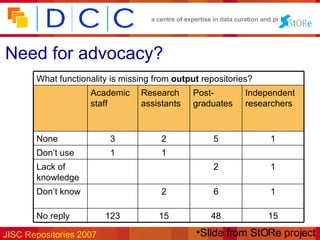
The document discusses the challenges of curating scientific data, emphasizing the importance of data for scholarly records and the need for effective repository management to ensure data accessibility and usability. It highlights the significance of metadata, proper storage practices, and the need for collaboration between researchers and repository managers. Additionally, the text addresses the cultural changes necessary for successful data curation and the various players involved in this process.





























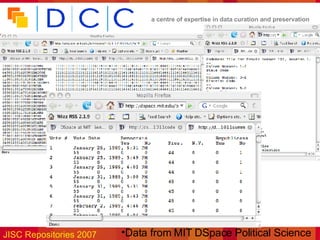
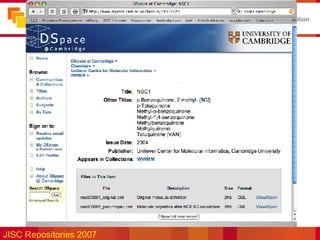
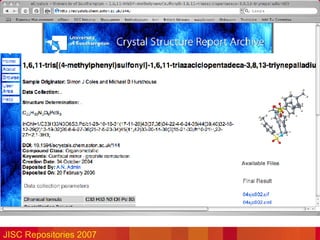

![Disciplinary repositories… >900 Nucleic Acids datasets! ESDS/UKDA and NERC data centres, but… “ AHRC Council has decided to cease funding the Arts and Humanities Data Service (AHDS) from March 2008. […] Grant holders must make materials they had planned to deposit with the AHDS available in an accessible depository for at least three years after the end of their grant” AHRC Press Release 14/05/2007 (Note petition at http://petitions.pm.gov.uk/AHDSfunding/) Does not apply to Archaeology: ADS still funded?](https://image.slidesharecdn.com/data-curation-issues-for-repositories-27591/85/Data-curation-issues-for-repositories-35-320.jpg)




![Thank you [email_address]](https://image.slidesharecdn.com/data-curation-issues-for-repositories-27591/85/Data-curation-issues-for-repositories-41-320.jpg)





















































































