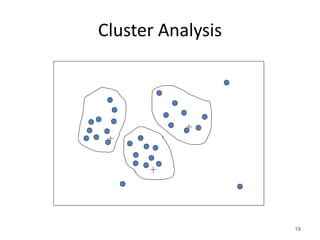
This document discusses data preprocessing techniques. It begins by defining data and its key components - objects and attributes. It then provides an overview of common data preprocessing tasks including data cleaning (handling missing values, noise and outliers), data transformation (aggregation, type conversion, normalization), and data reduction (sampling, dimensionality reduction). Specific techniques are described for each task, such as binning values, imputation methods, and feature selection algorithms like ranking, forward selection and backward elimination. The document emphasizes that high quality data preprocessing is important and can improve predictive model performance.
























![Normalization
716.00)00.1(
000,12000,98
000,12600,73
26
Scale the attribute values to a small specified range
• Min-max normalization: to [new_minA, new_maxA]
– E.g., Let income range $12,000 to $98,000 normalized to [0.0, 1.0].
Then $73,000 is mapped to
• Z-score normalization (μ: mean, σ: standard deviation):
• ……
AAA
AA
A
minnewminnewmaxnew
minmax
minv
v _)__('
](https://image.slidesharecdn.com/datapreprocessing-170507203851/85/Data-preprocessing-in-Data-Mining-27-320.jpg)