

![PROPRIETARY & CONFIDENTIAL
Demo Example
Load Log Files from S3 to
HDFS and perform
aggregations/analysis
•Start with web access logs stored in
Amazon S3
•Store the raw logs into HDFS Avro Files
•Parse the access log lines into individual
fields
•Calculate the total number of requests by
IP and status code
•Find out IPs which received maximum
successful status code and error codes
69.181.160.120 - - [08/Feb/2015:04:36:40 +0000] "GET /ajax/planStatusHistory HTTP/1.1" 200 508 "http://builds.cask.co/log" "Mozilla/5.0
(Macintosh; Intel Mac OS X 10_10_1) AppleWebKit Chrome/38.0.2125.122 Safari/537.36"
Fields: IP Address, Timestamp, Http Method, URI, Http Status, Response Size, URI, Client Info
Sample Web access log (Combined Log Format):](https://image.slidesharecdn.com/h61zbhsgrc2am274hst0-signature-cd258da1f9f37c1fdbc454765d5c9ecfac41d0835b94978b1363c44621f42b66-poli-160812201454/75/Big-Data-Day-LA-2016-Use-Case-Driven-track-Hydrator-Open-Source-Code-Free-Data-Pipelines-Jon-Gray-CEO-Cask-Data-3-2048.jpg)



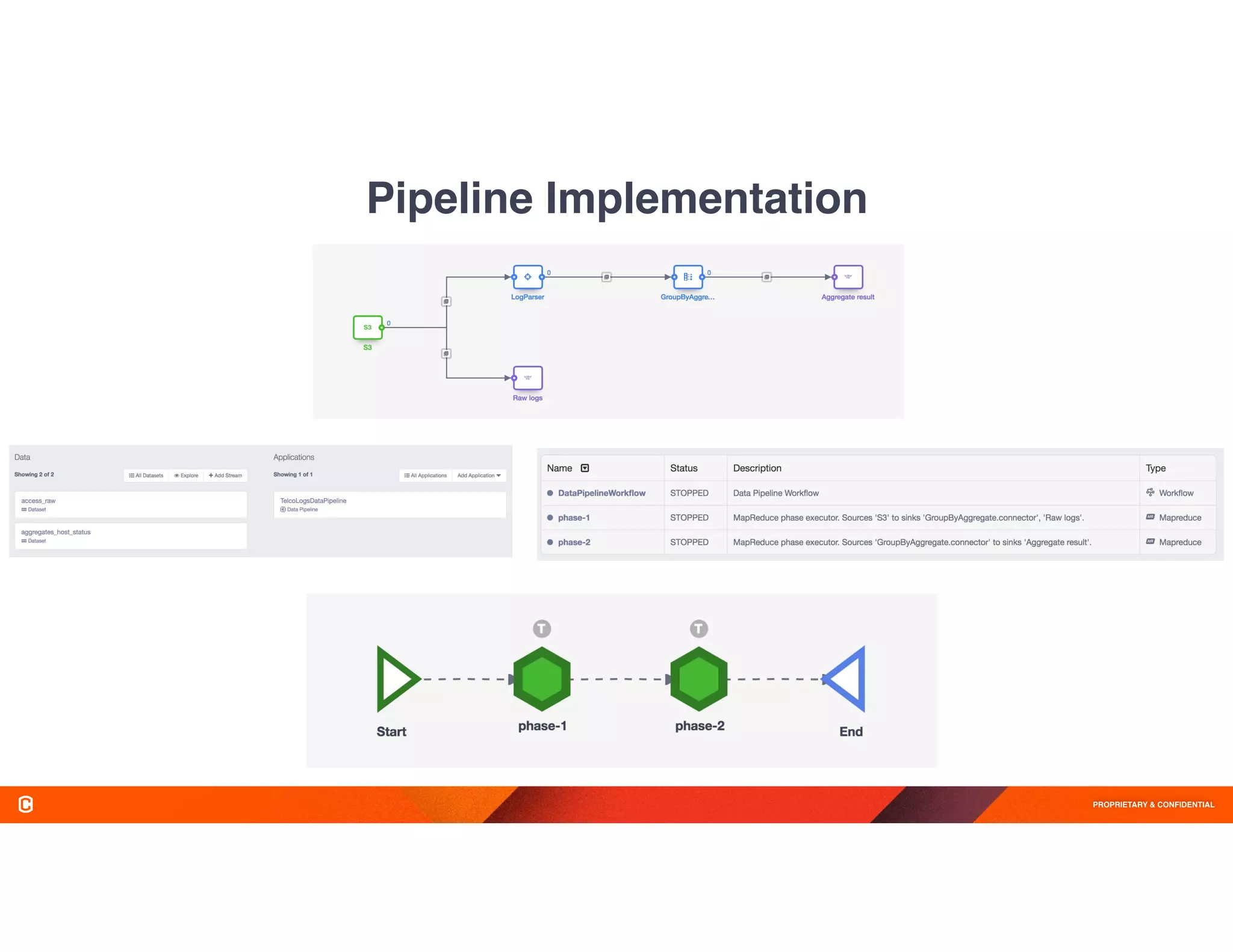


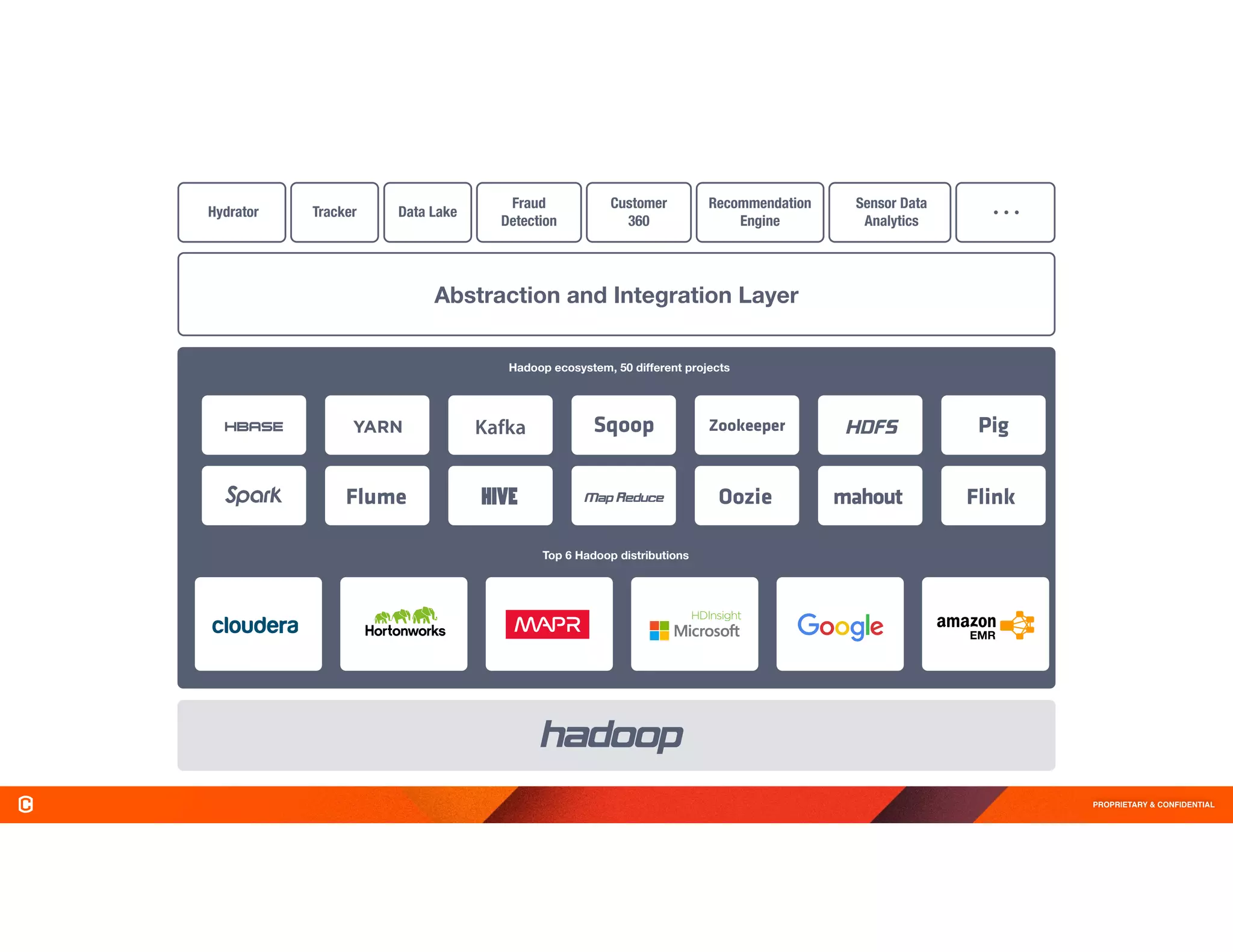
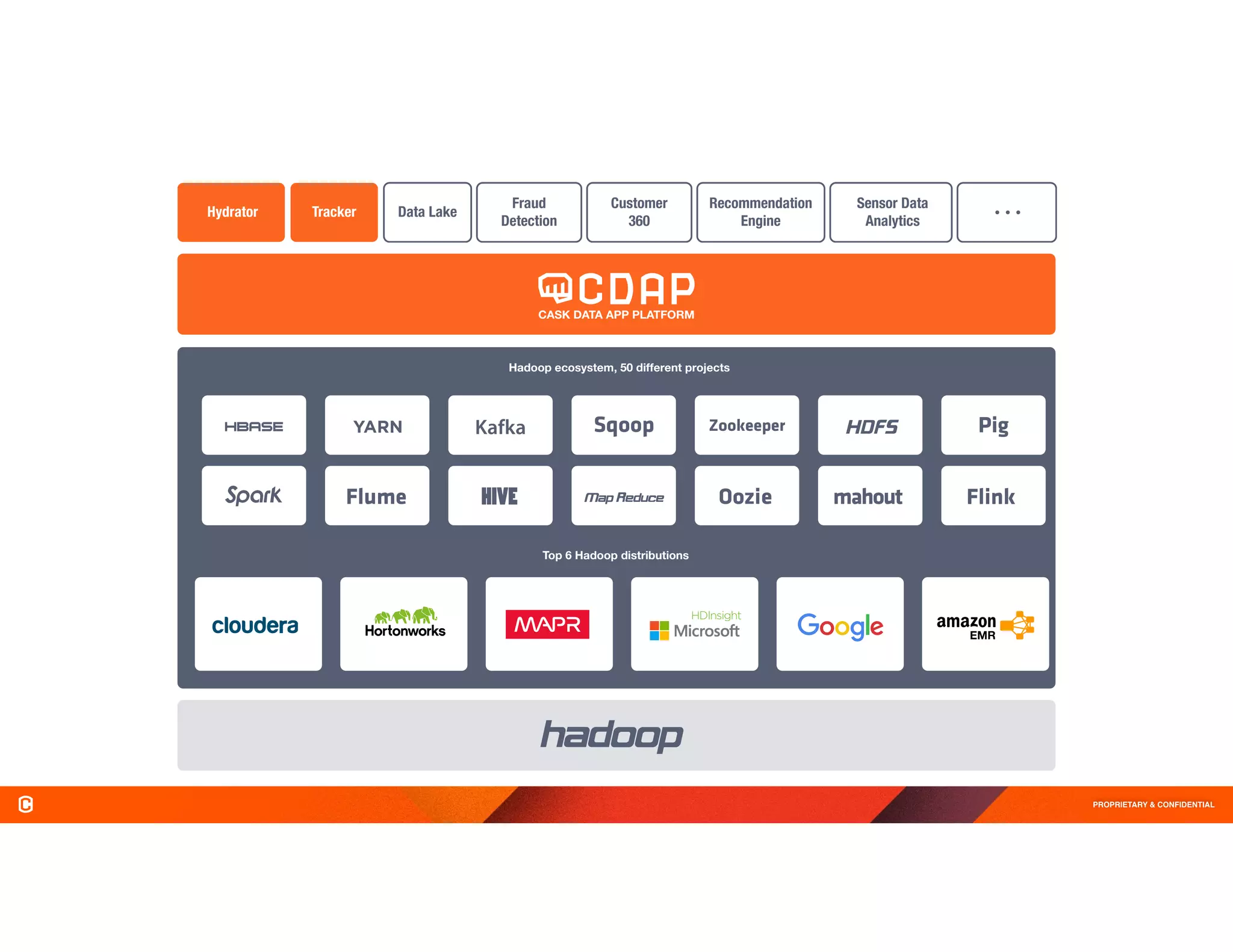







The document discusses Cask Hydrator, a framework for building and managing data pipelines on Hadoop, highlighting its capabilities in transforming and analyzing web log data. It details features like a drag-and-drop interface, real-time data ingestion, and the ability to integrate various data sources for ETL (Extract, Transform, Load) processes. Challenges in traditional data management approaches are also addressed, emphasizing the need for operational efficiency and compliance in data handling.

























































































![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)







![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)


