Downloaded 62 times




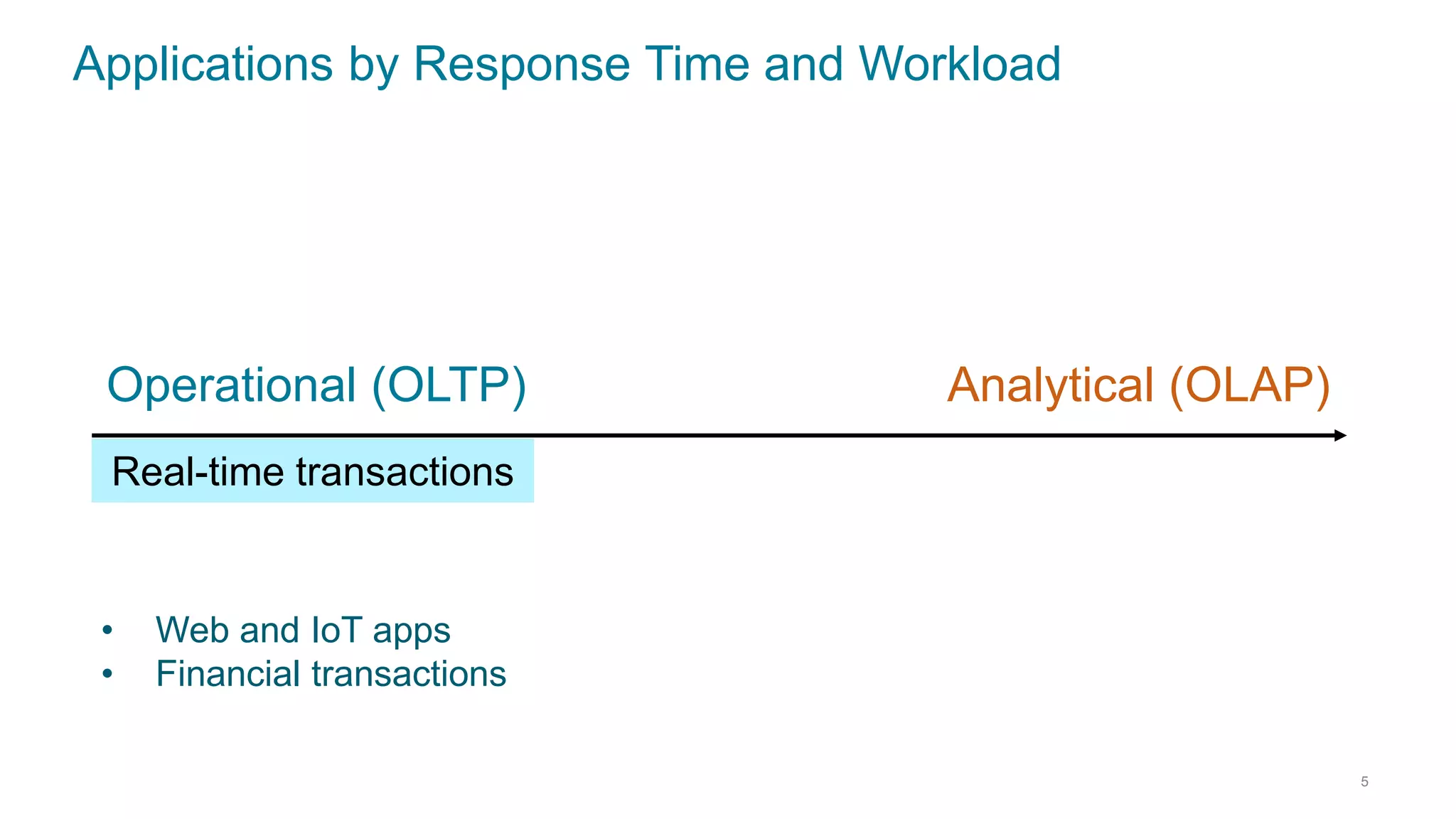
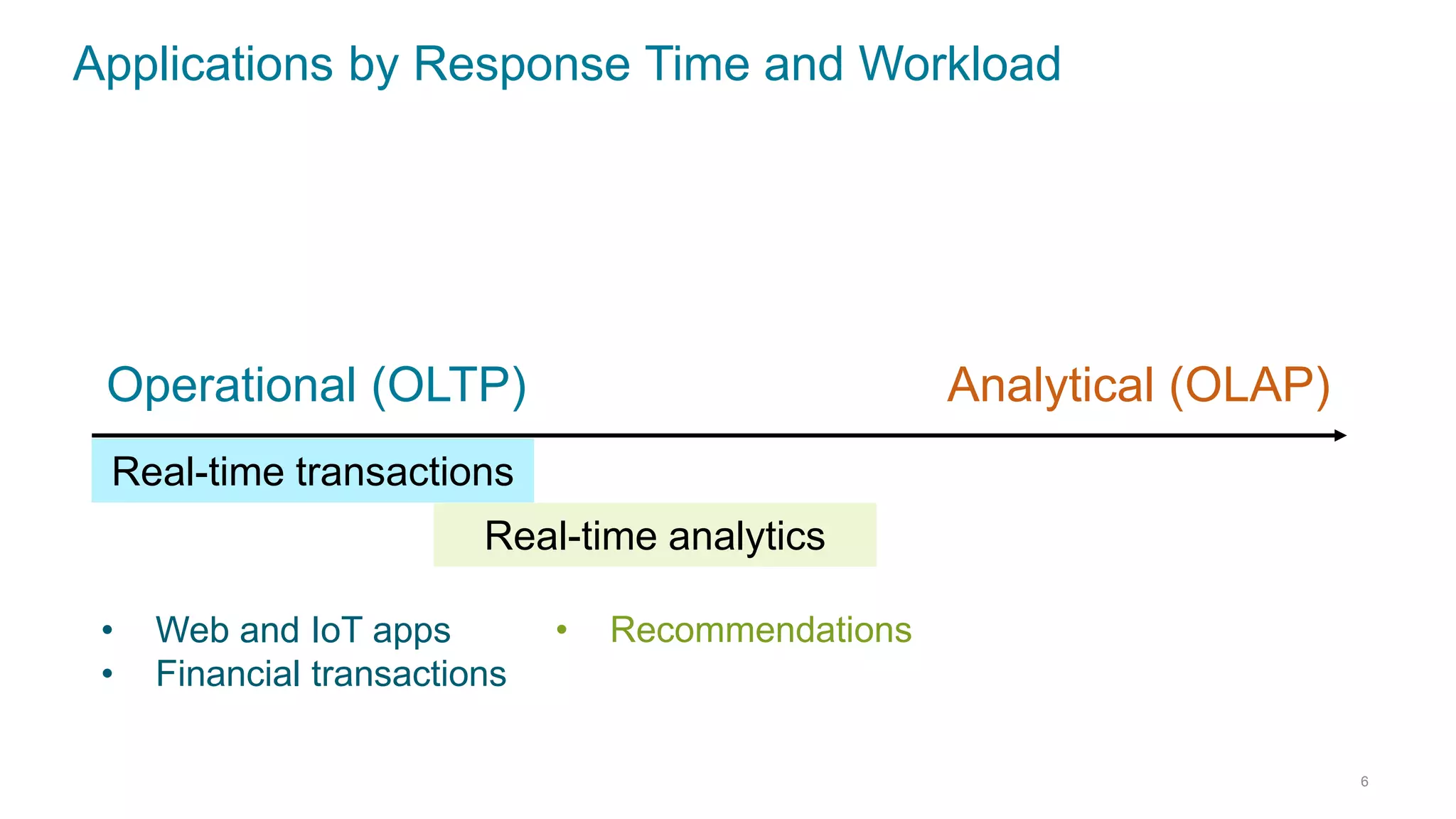
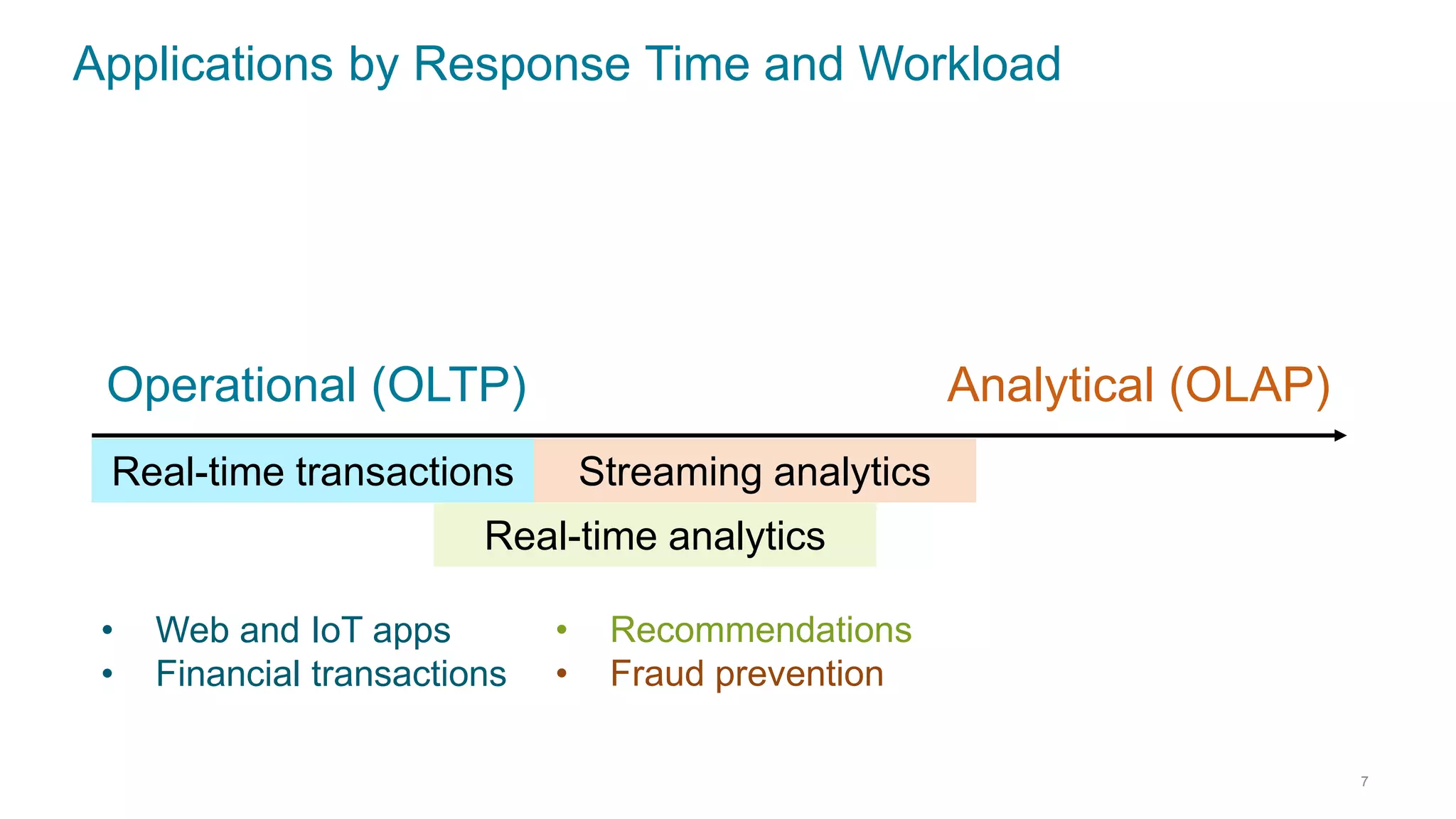
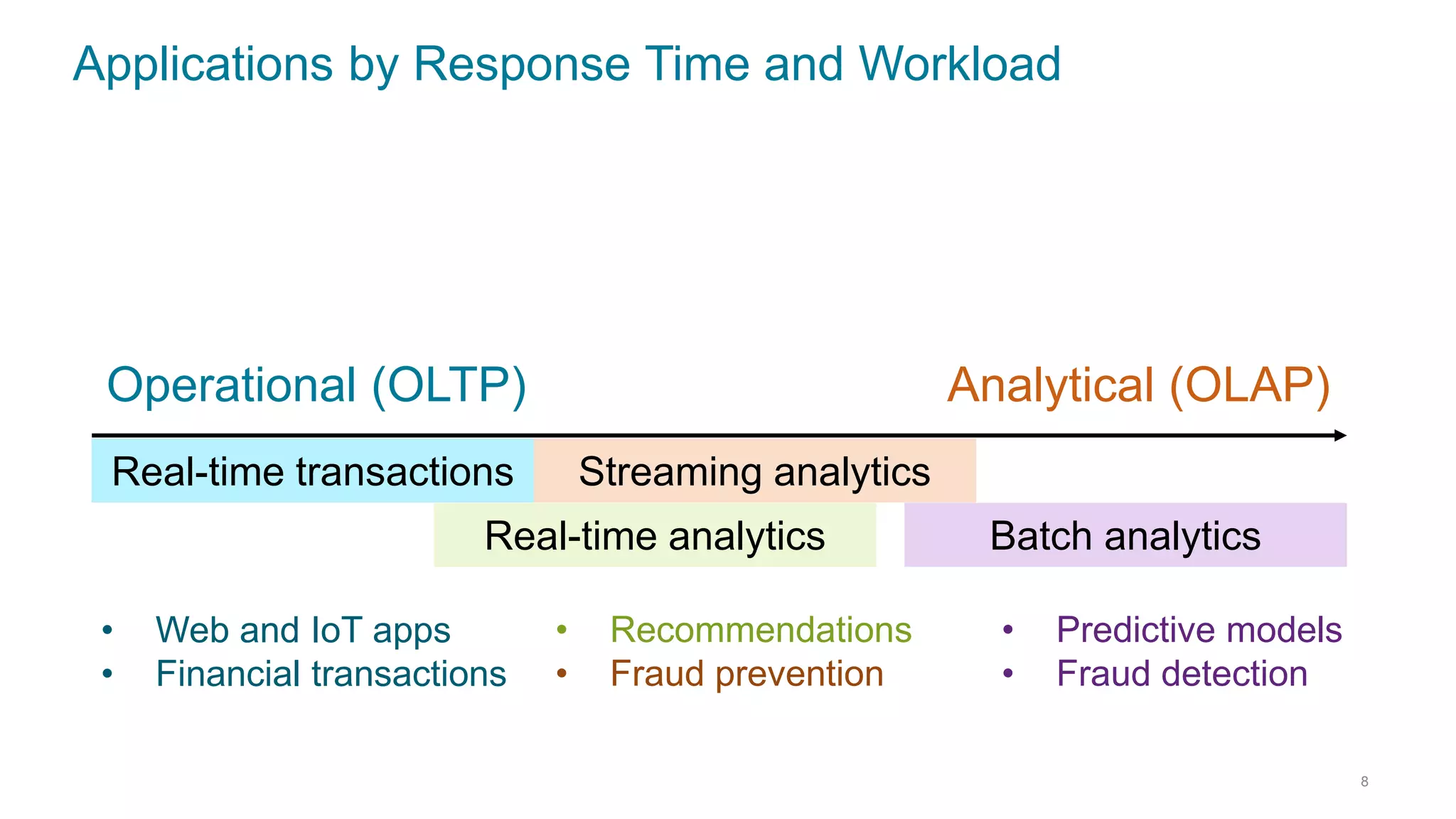
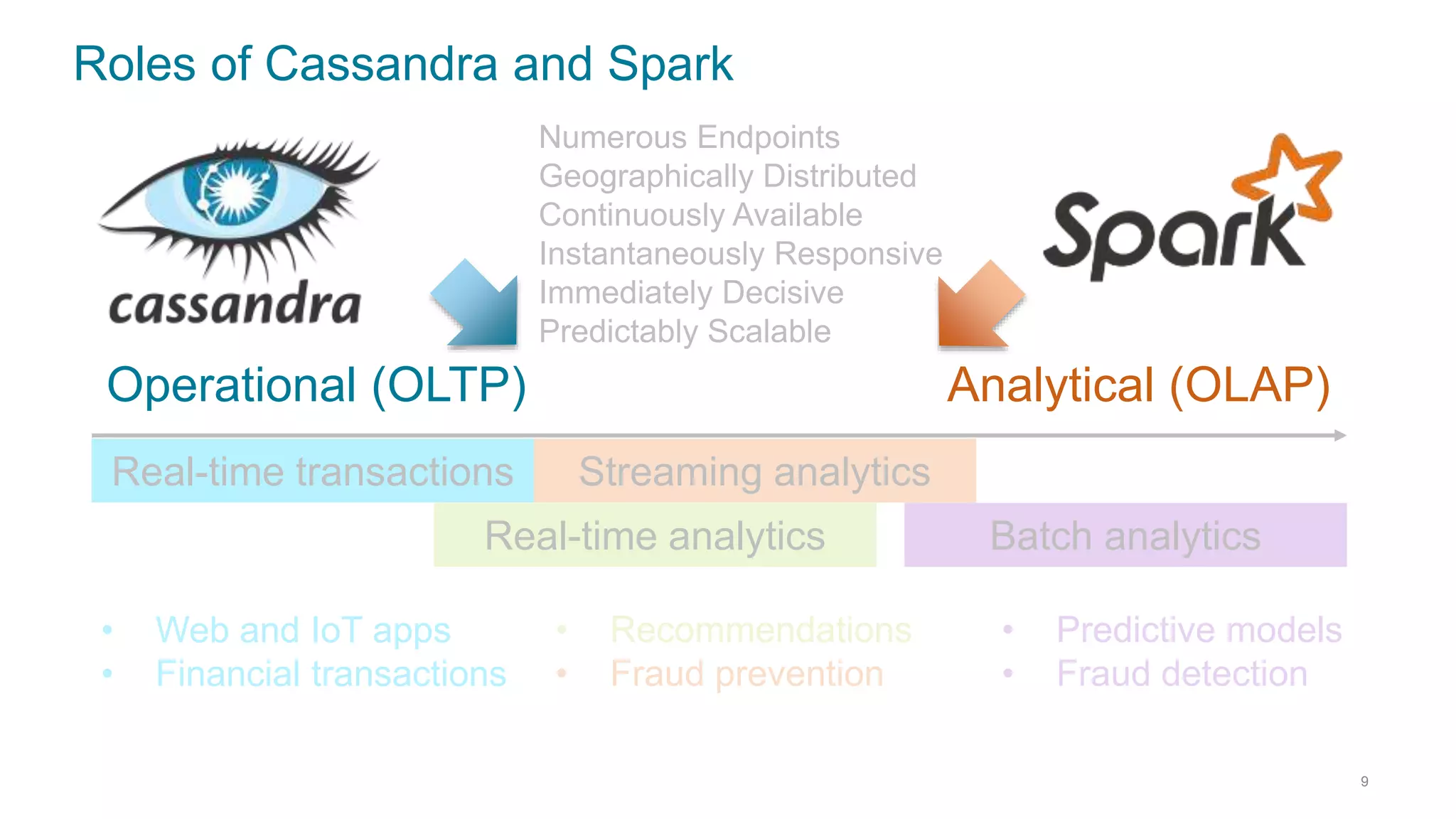




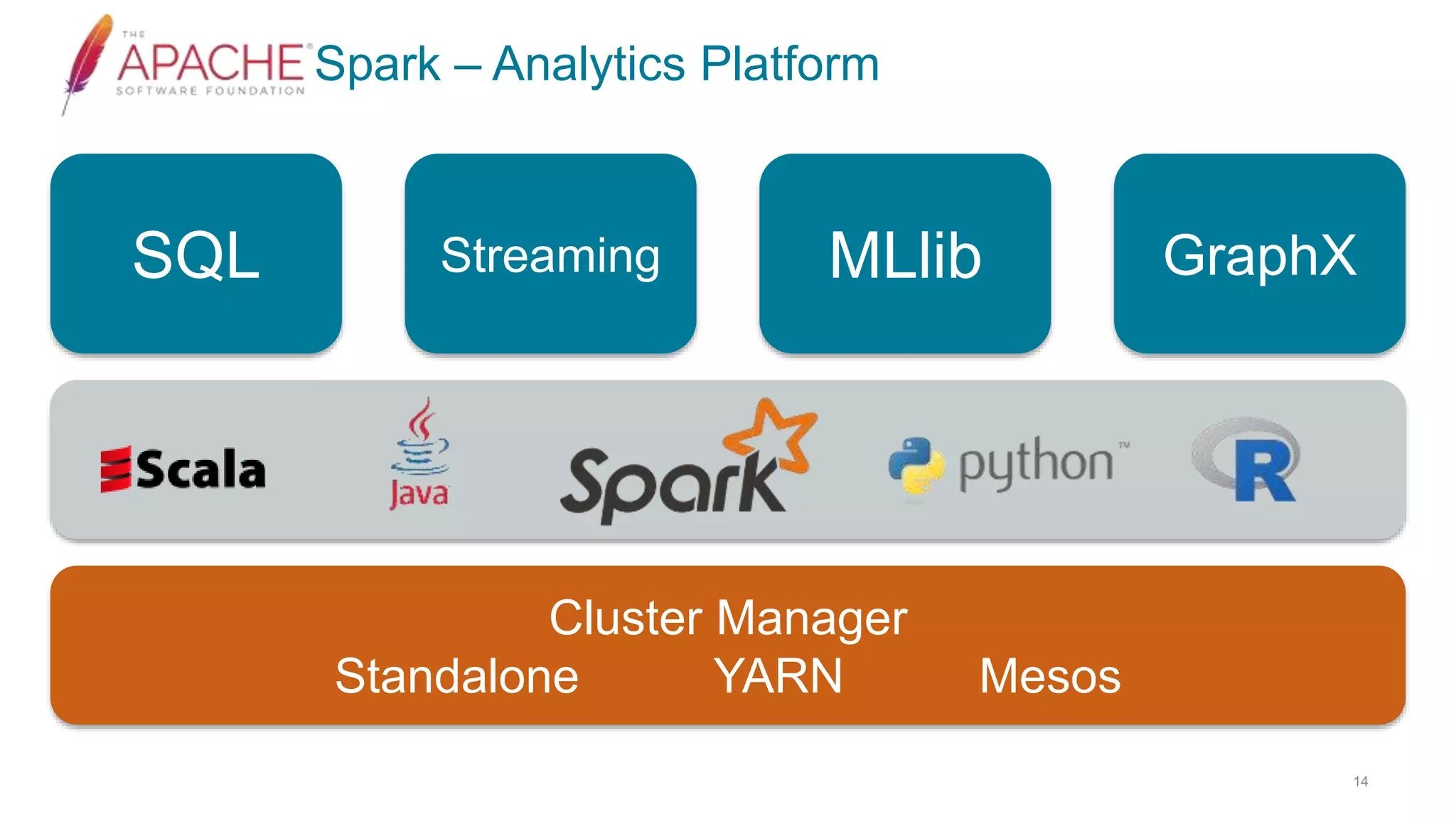


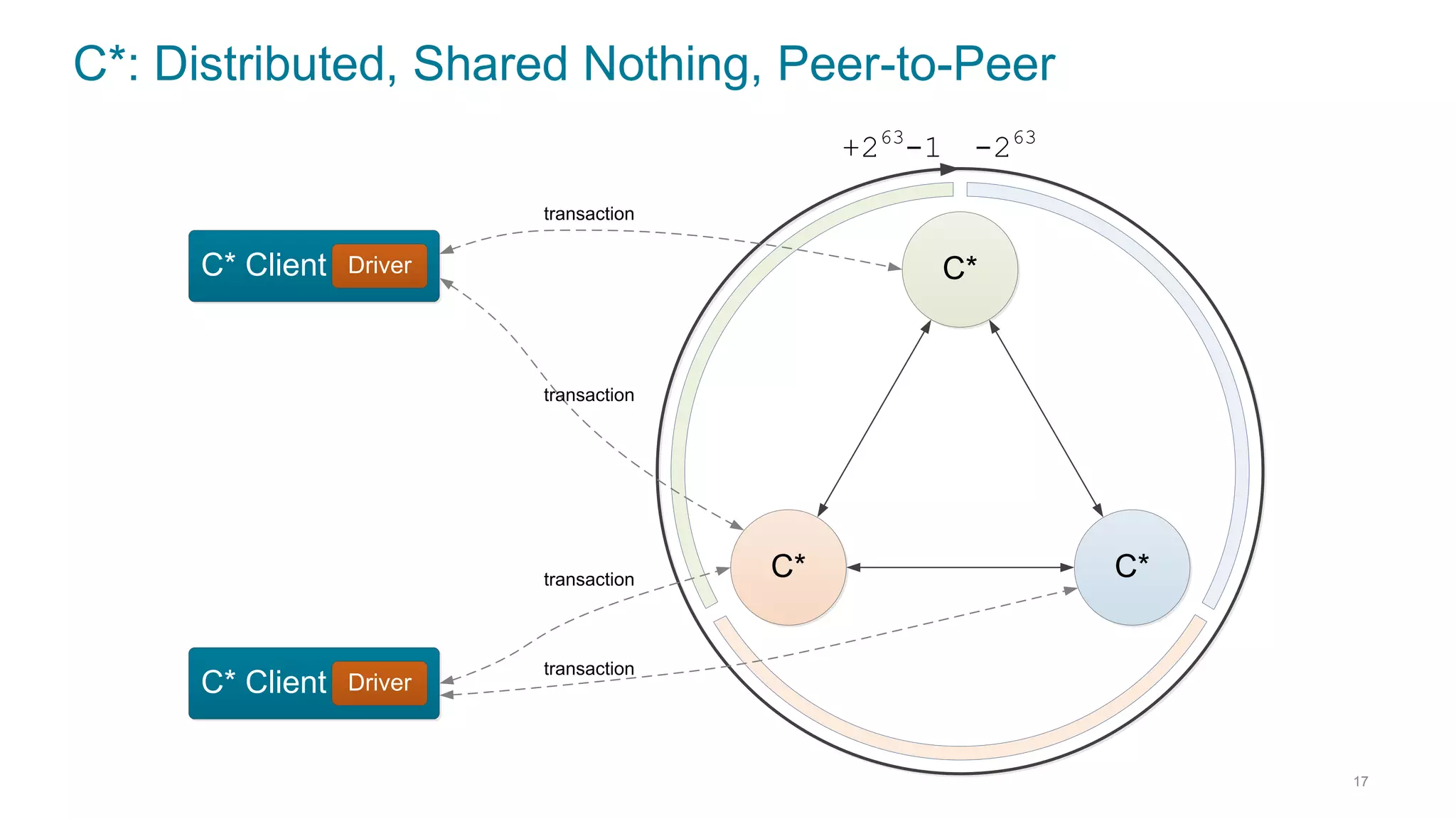
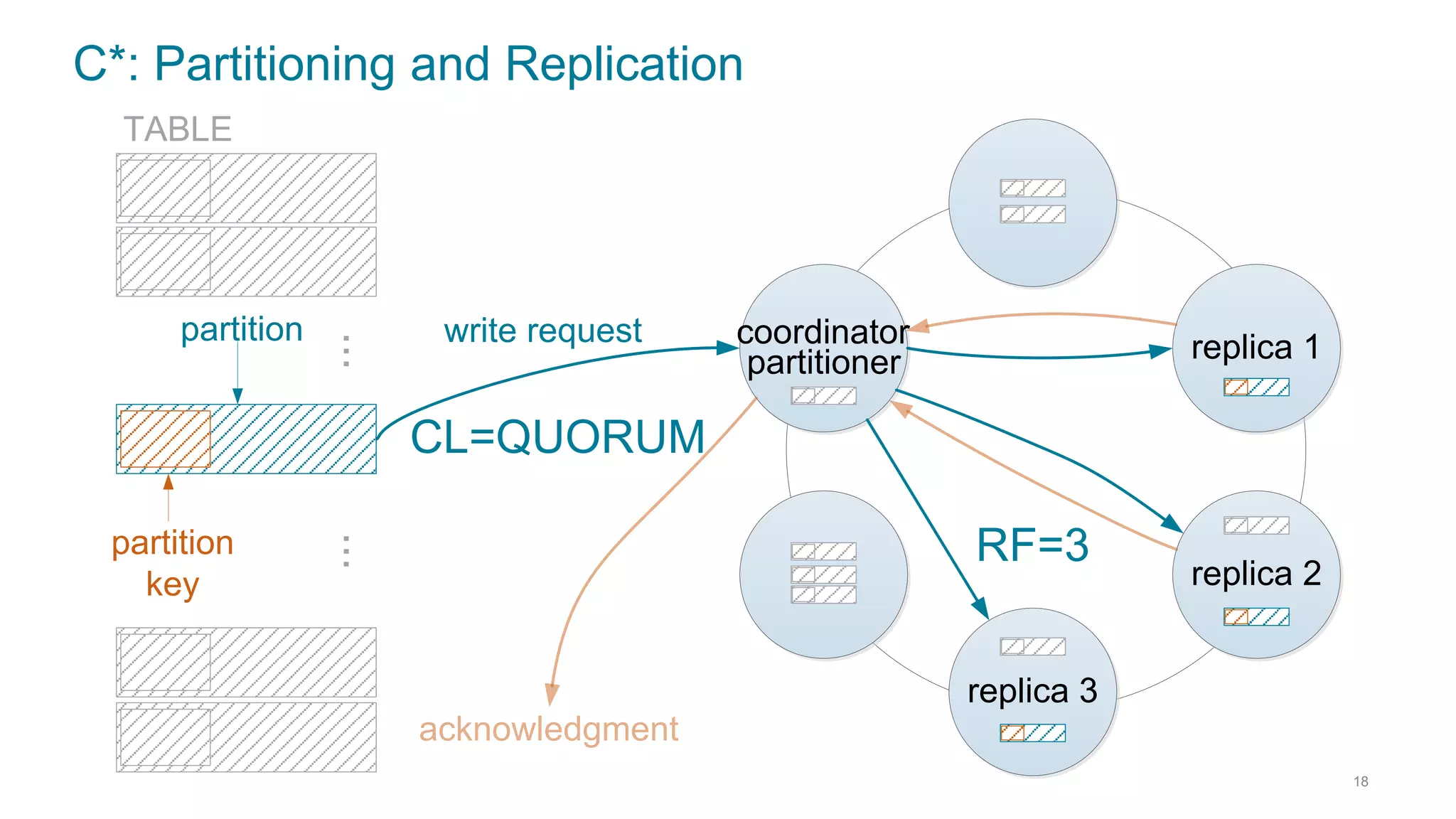
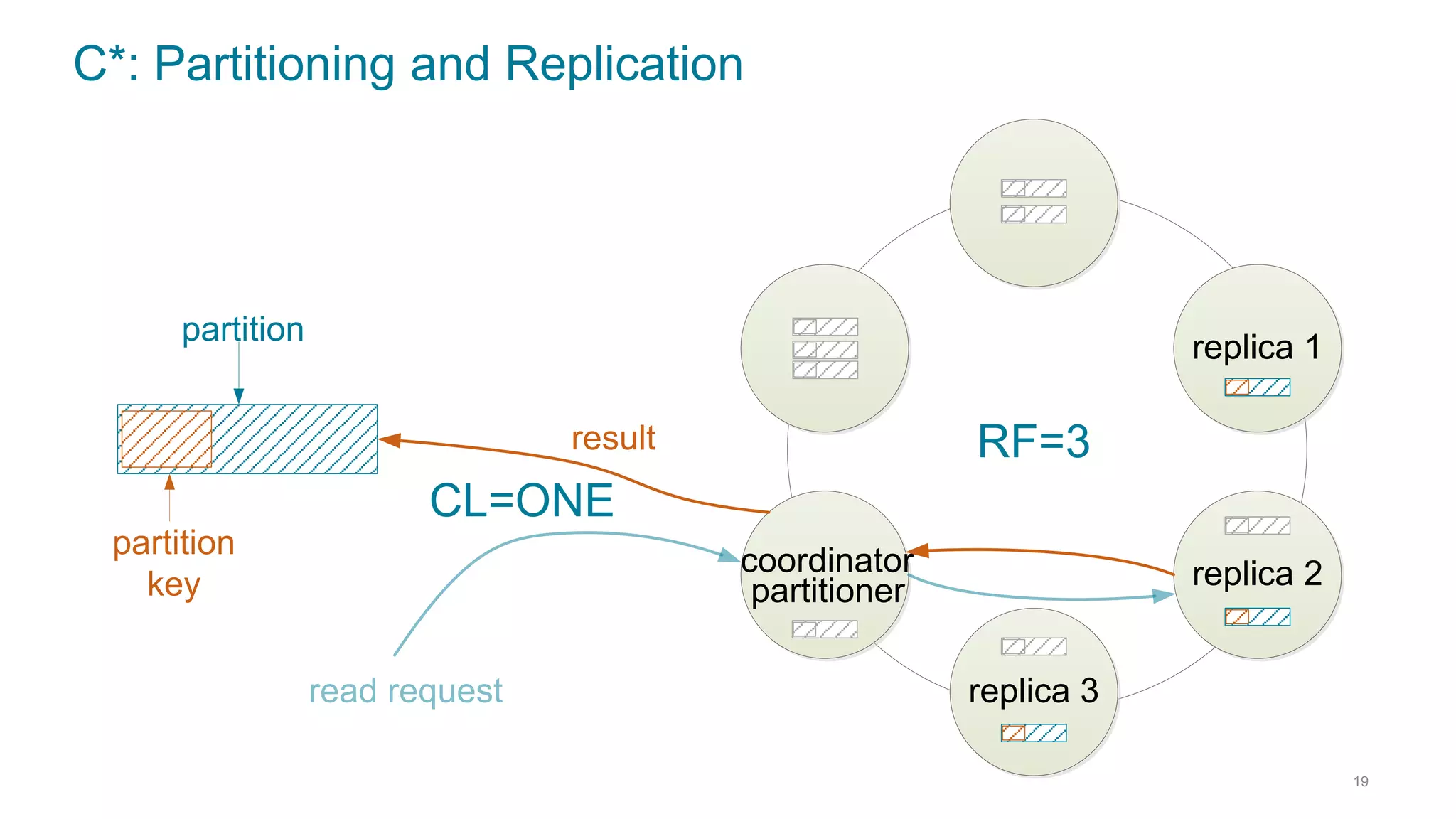
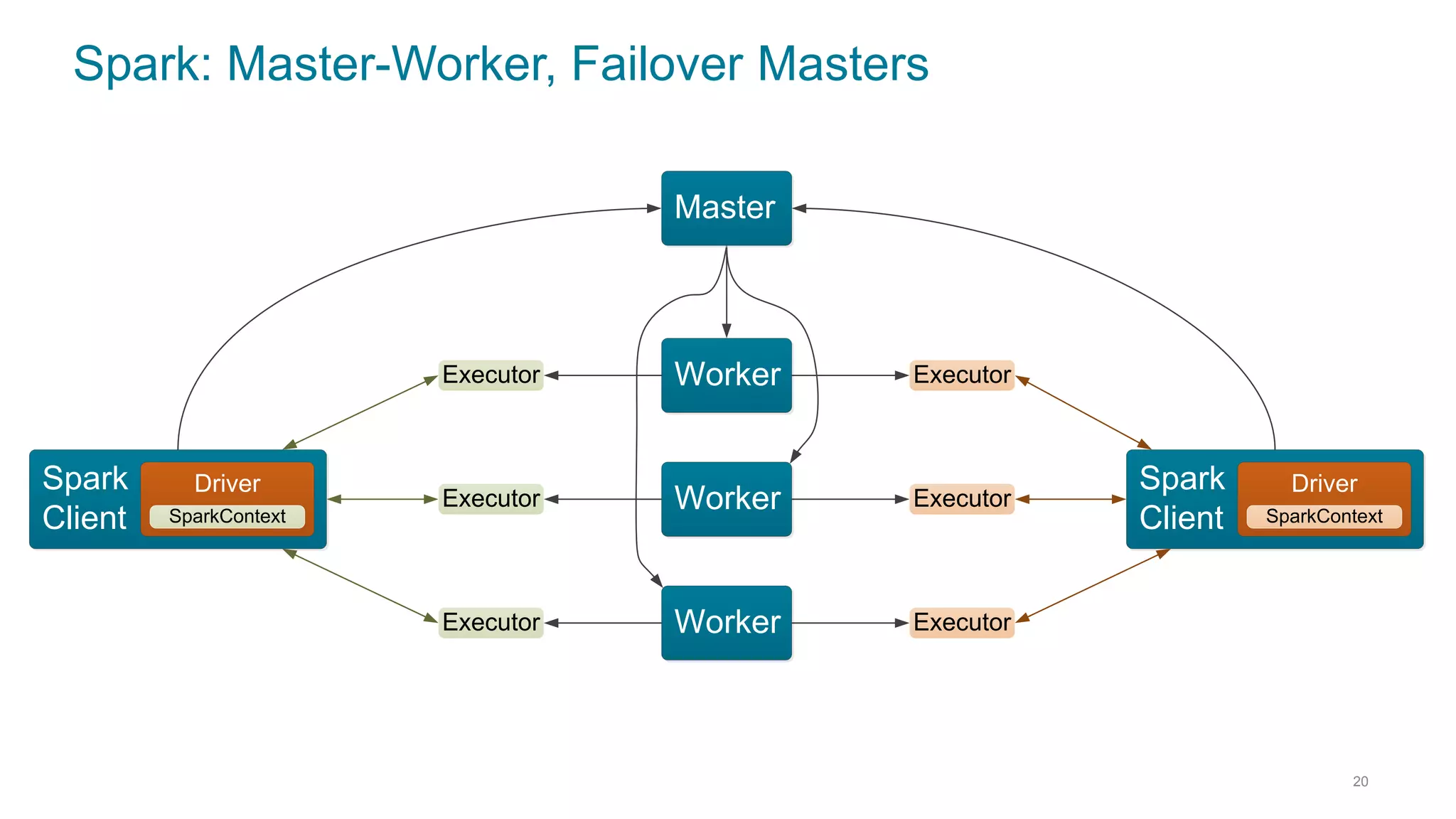
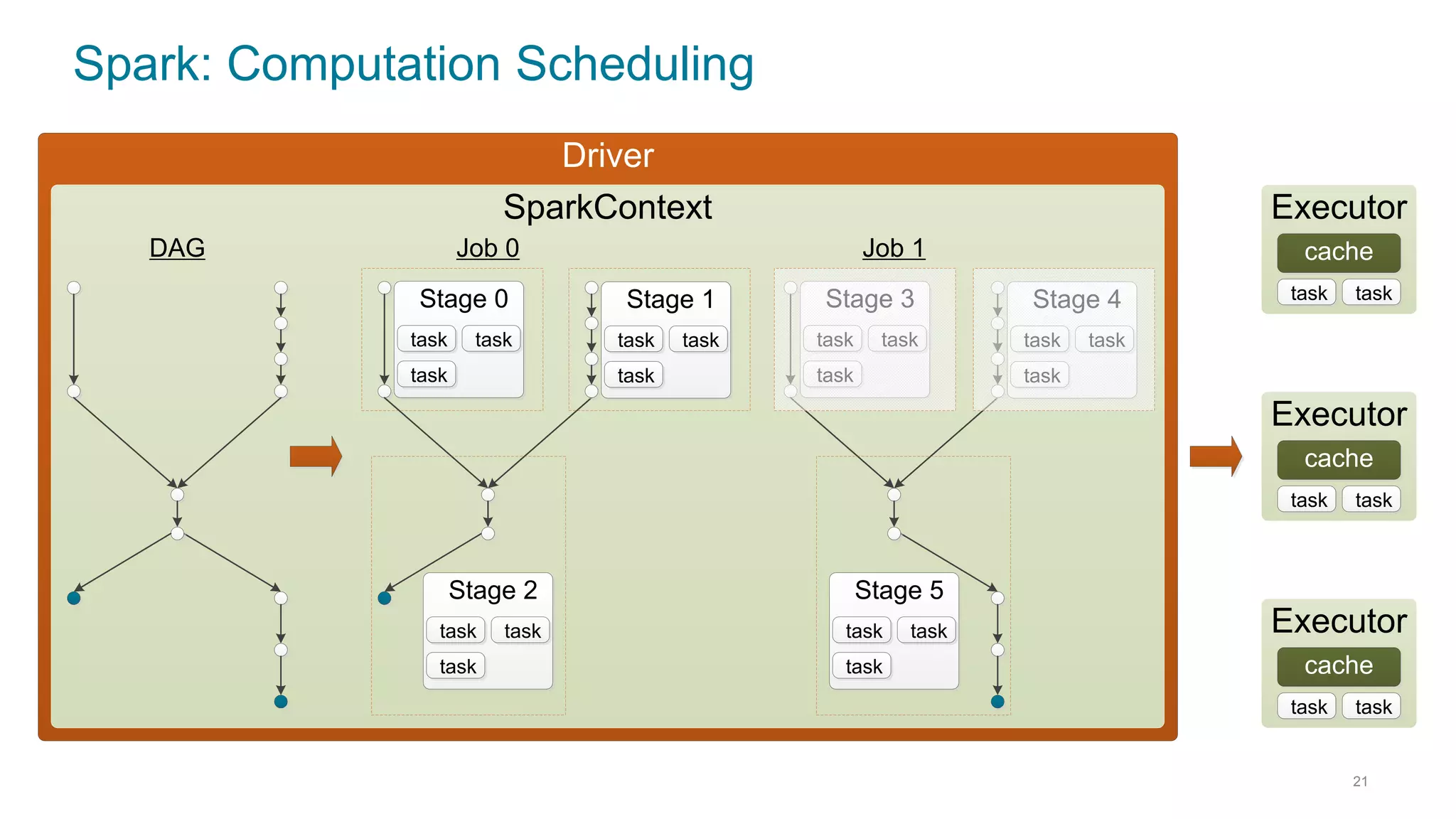
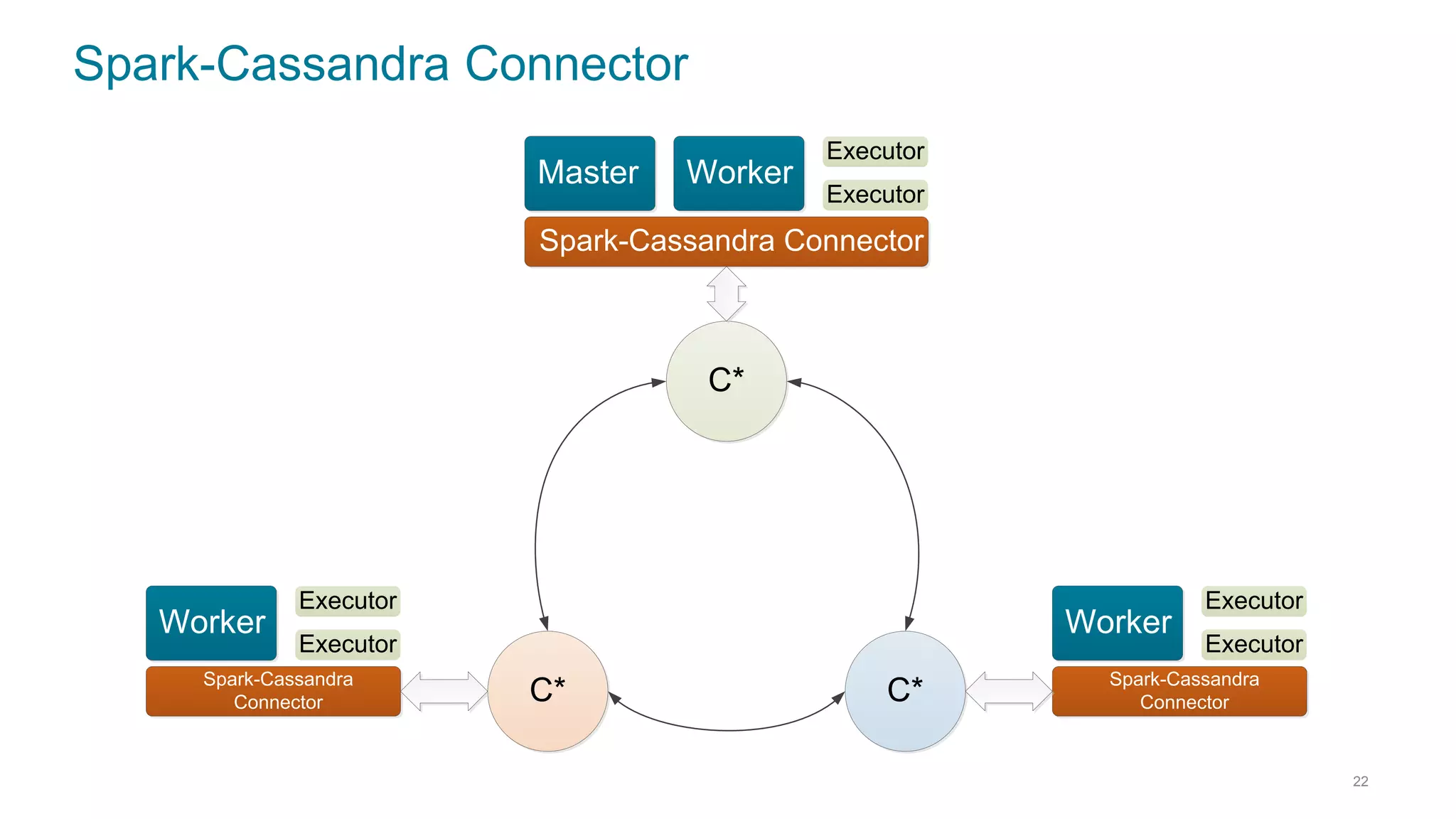
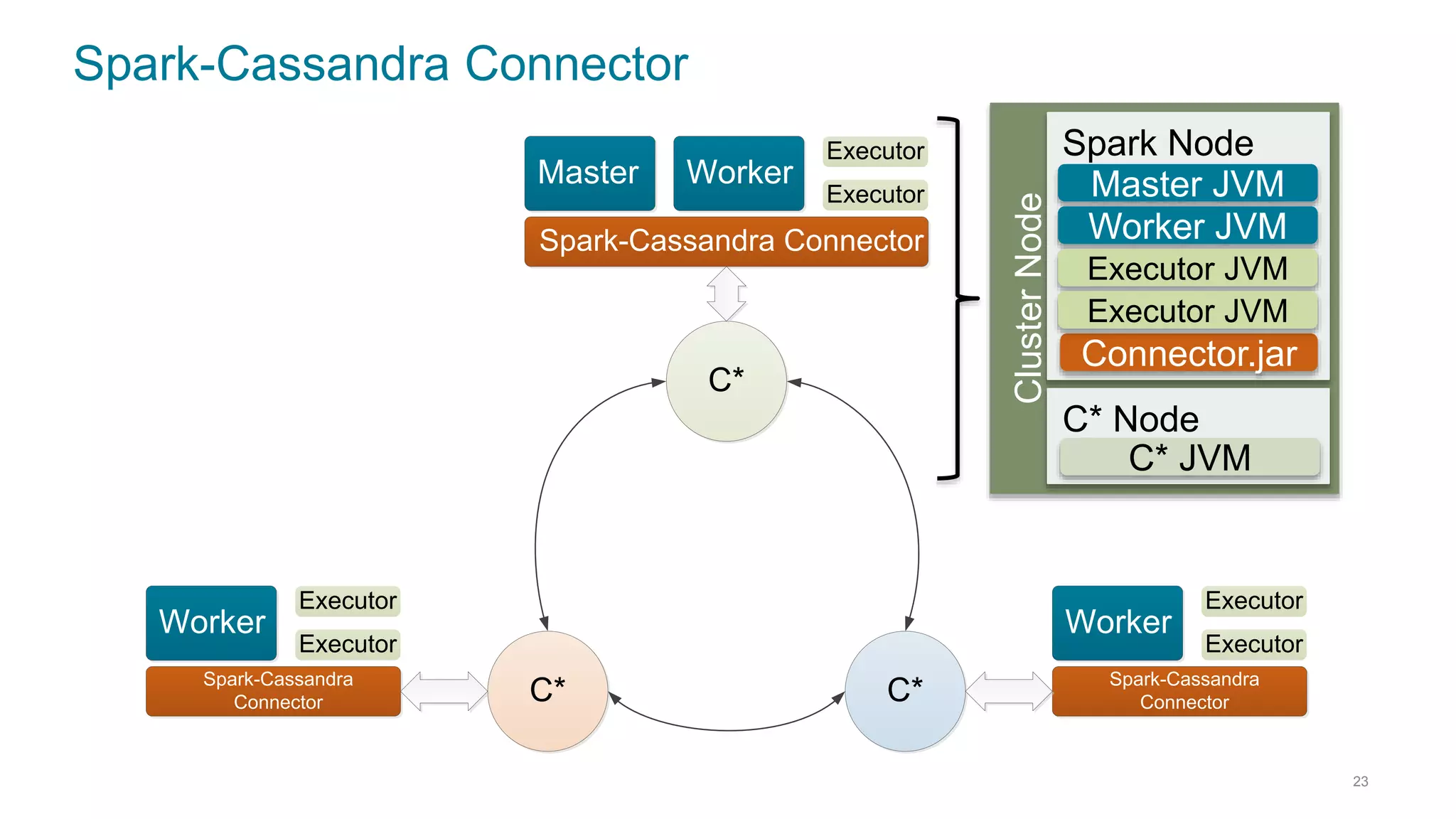
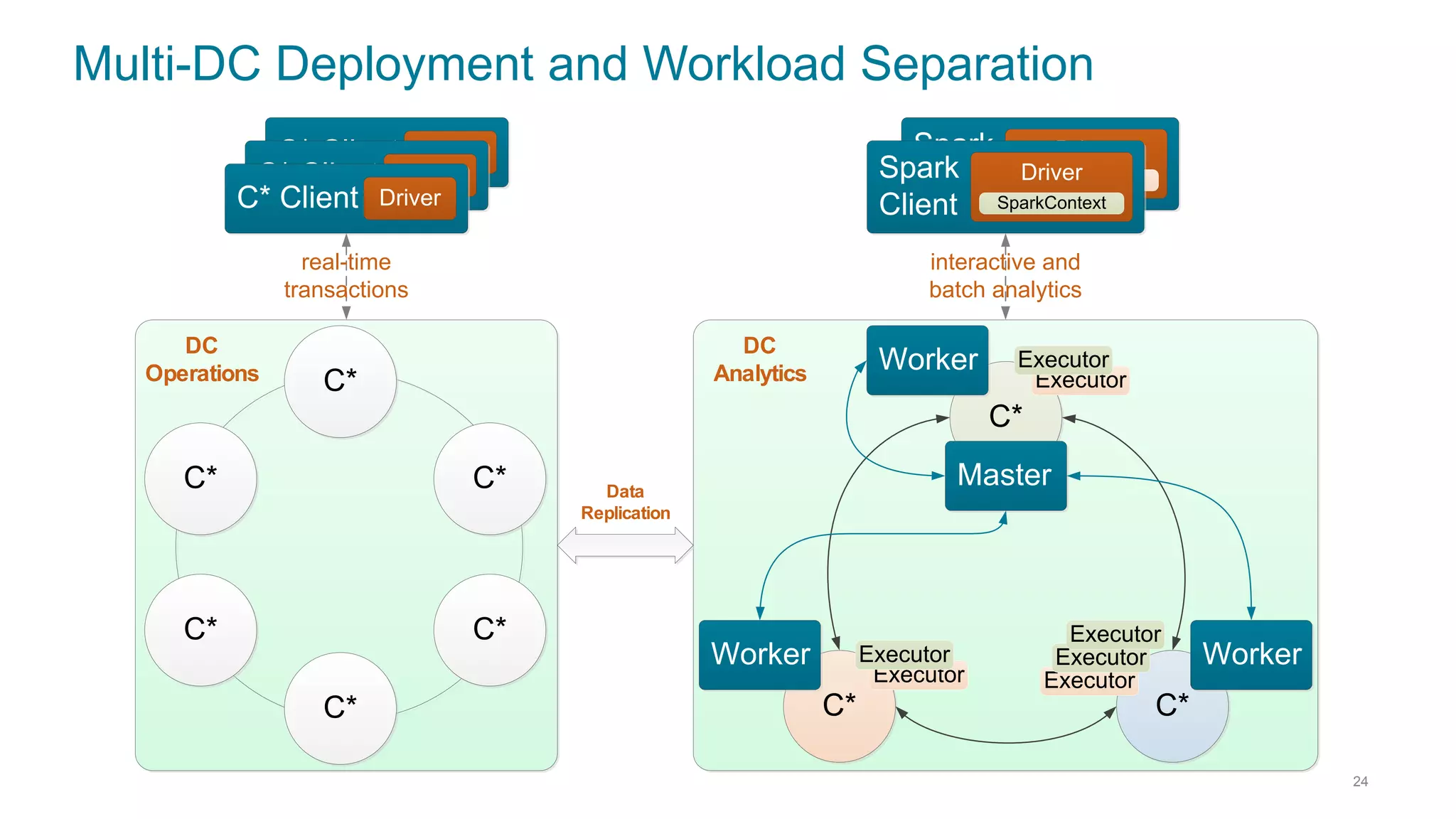










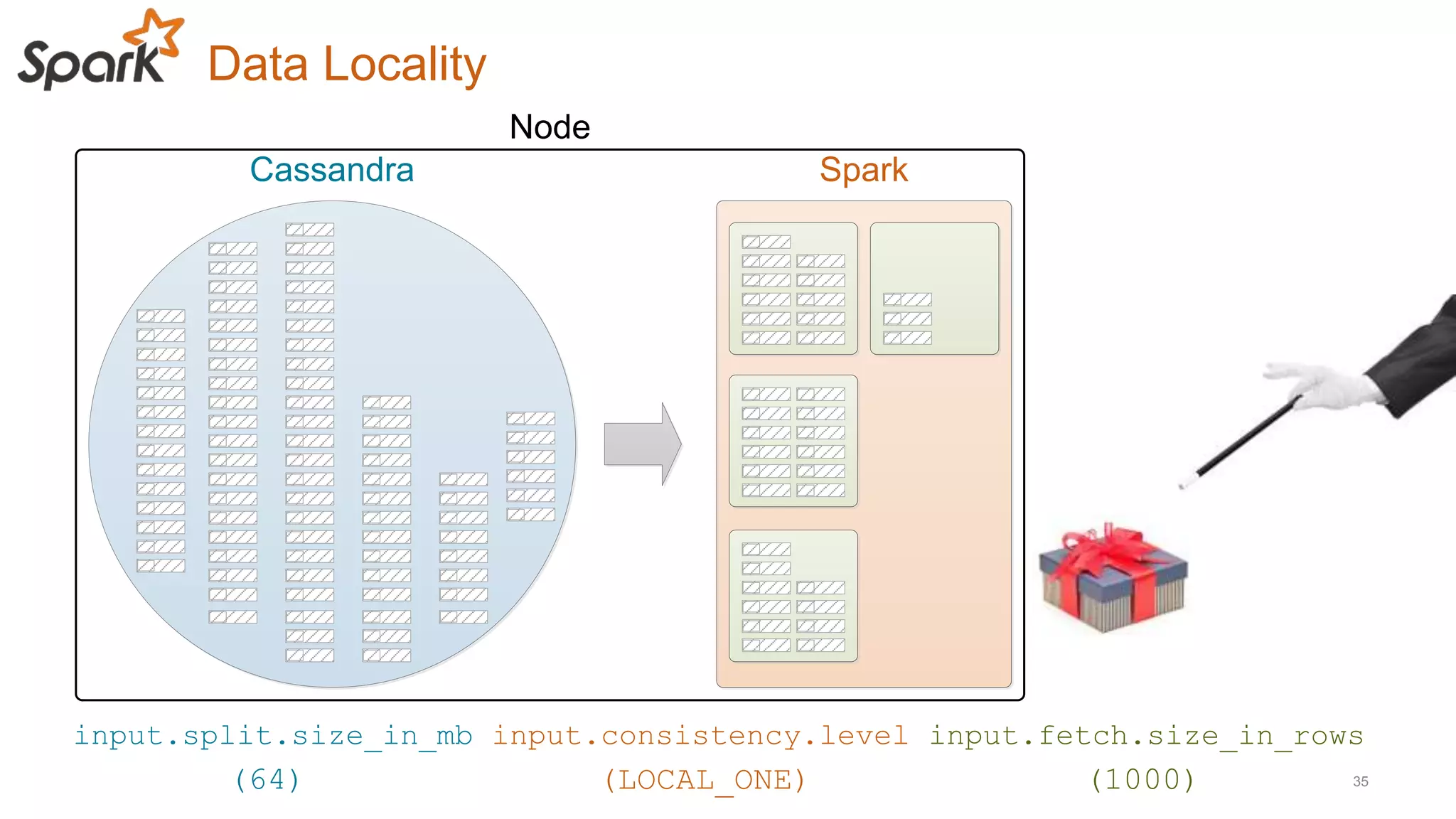

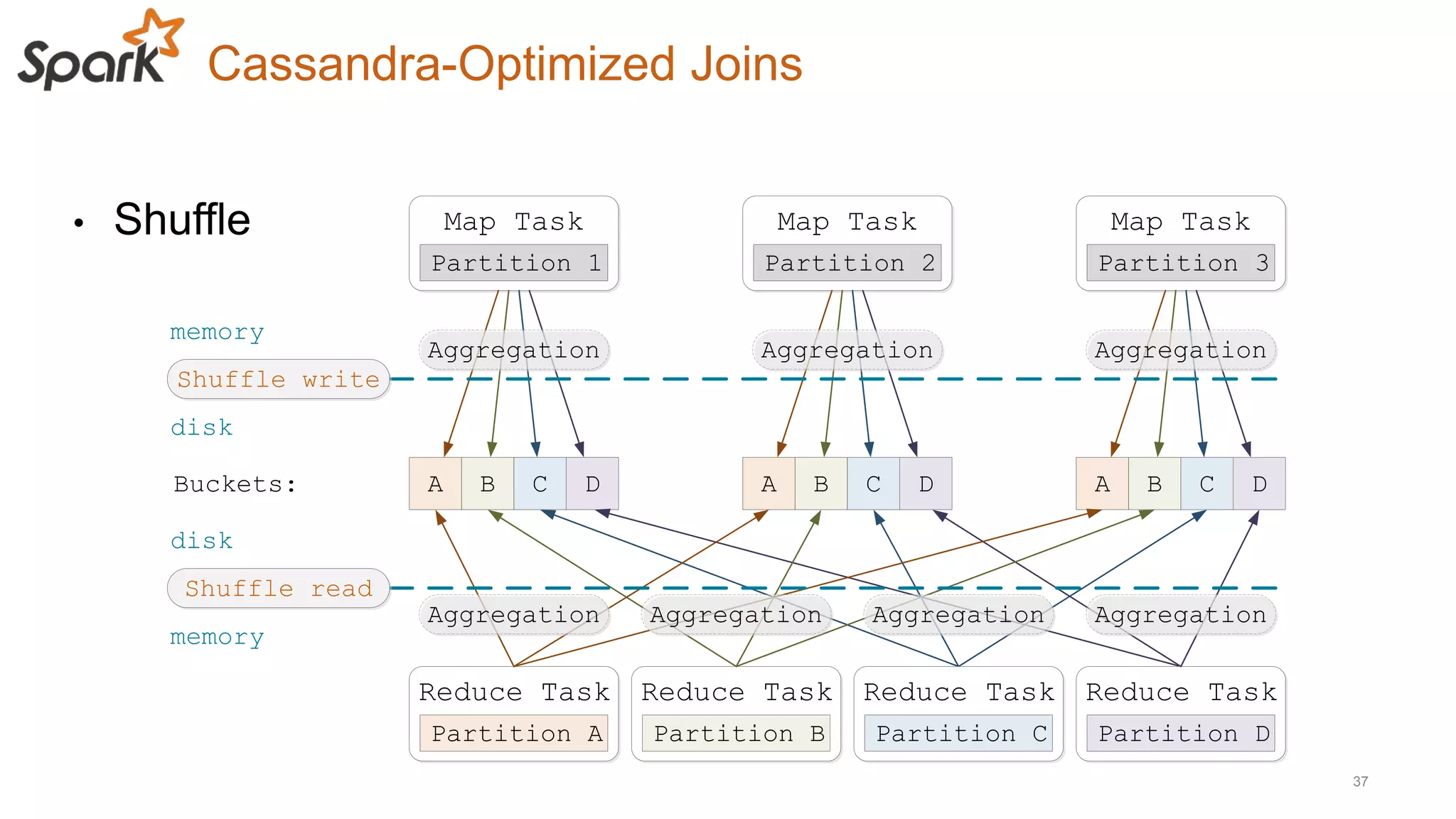

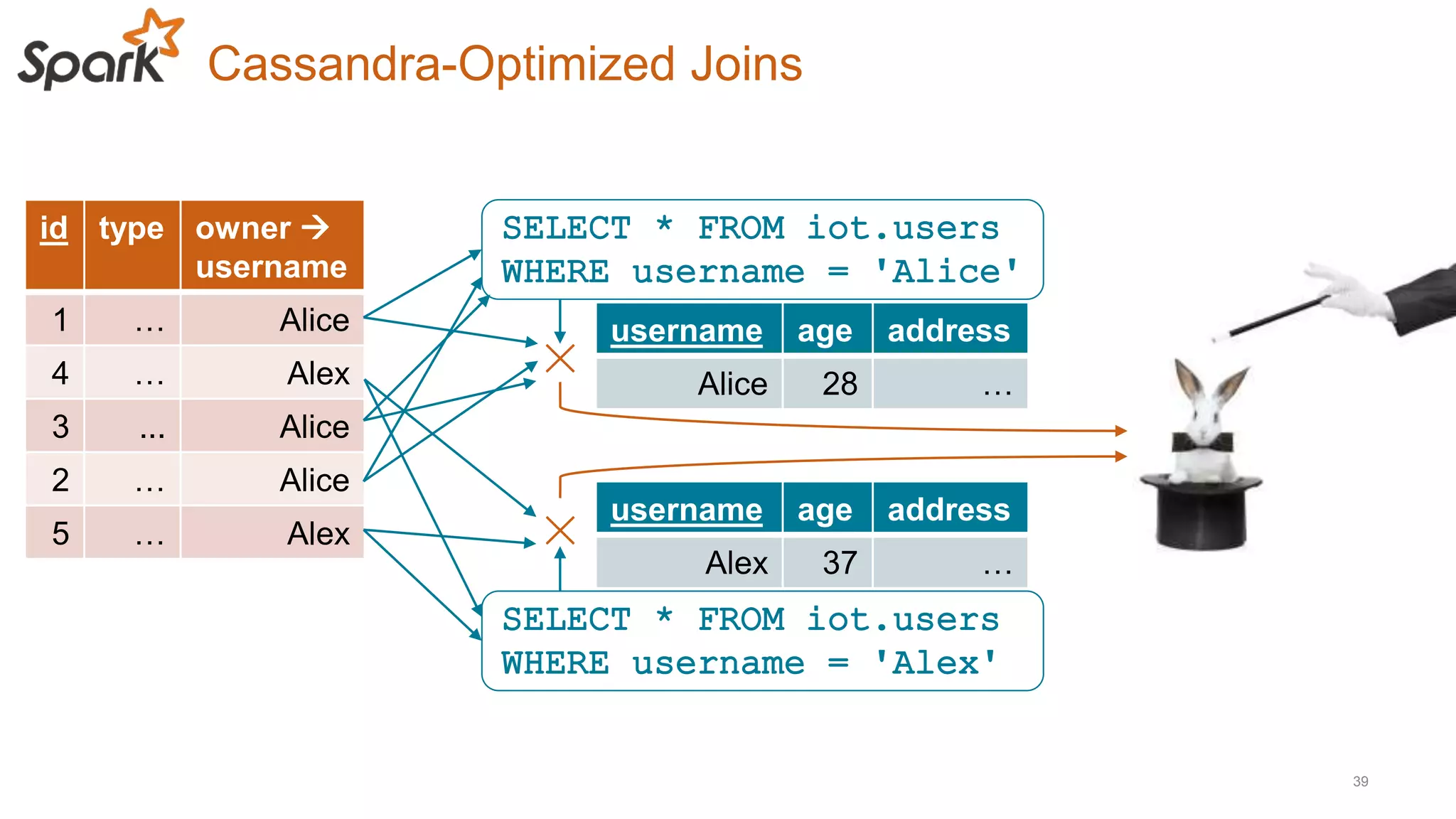

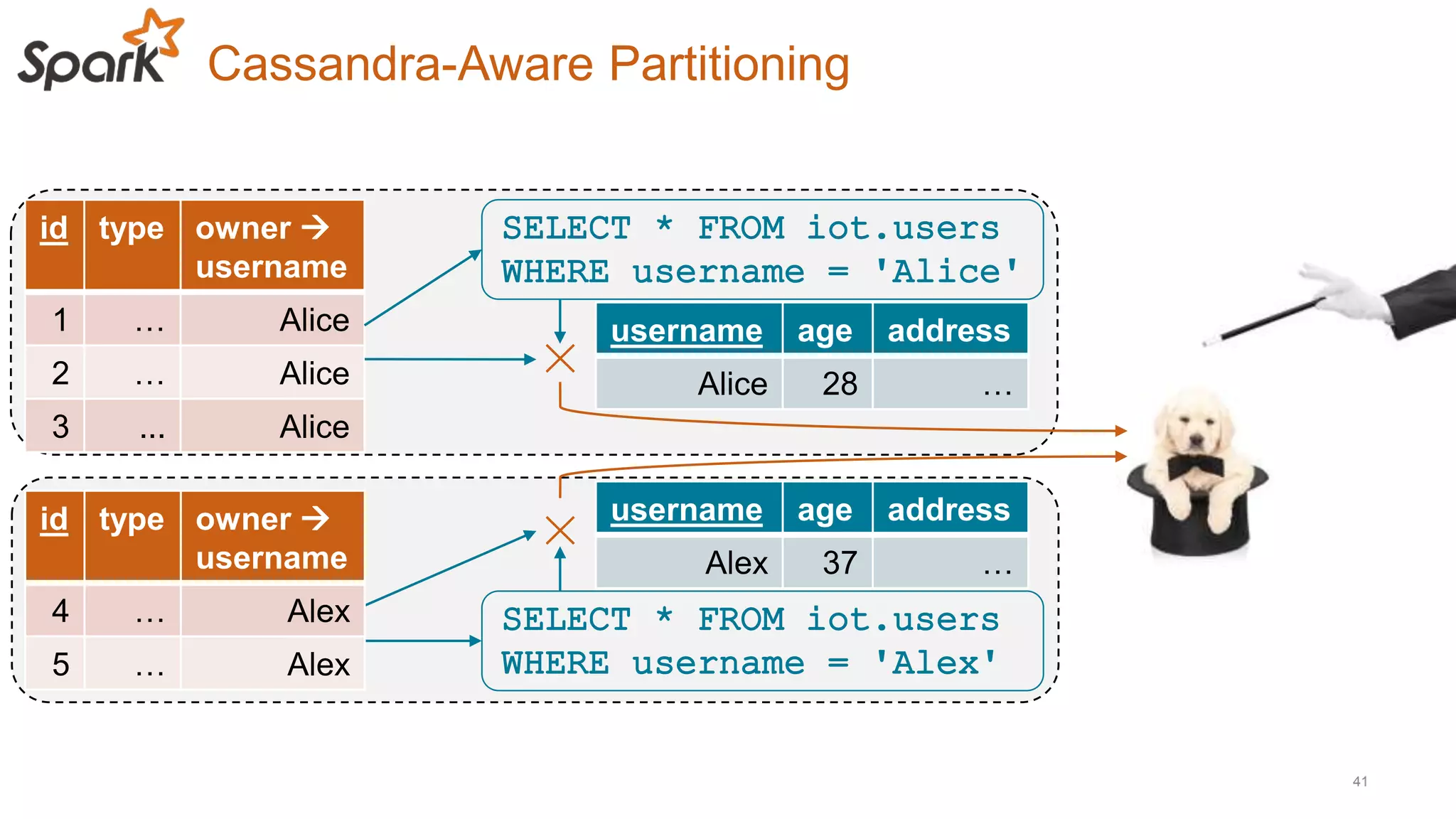






This document discusses using Cassandra and Spark for big data applications. It describes how Cassandra is well-suited for operational workloads with millisecond response times and linear scalability, while Spark can handle real-time, streaming and batch analytics up to 100x faster than Hadoop. The Spark-Cassandra connector allows Spark to efficiently read from and write into Cassandra by optimizing for predicate pushdown, data locality, joins and grouping. The document provides an architecture overview and examples of modeling data in Cassandra and interacting with it from Spark using the connector.



































































