Download to read offline












































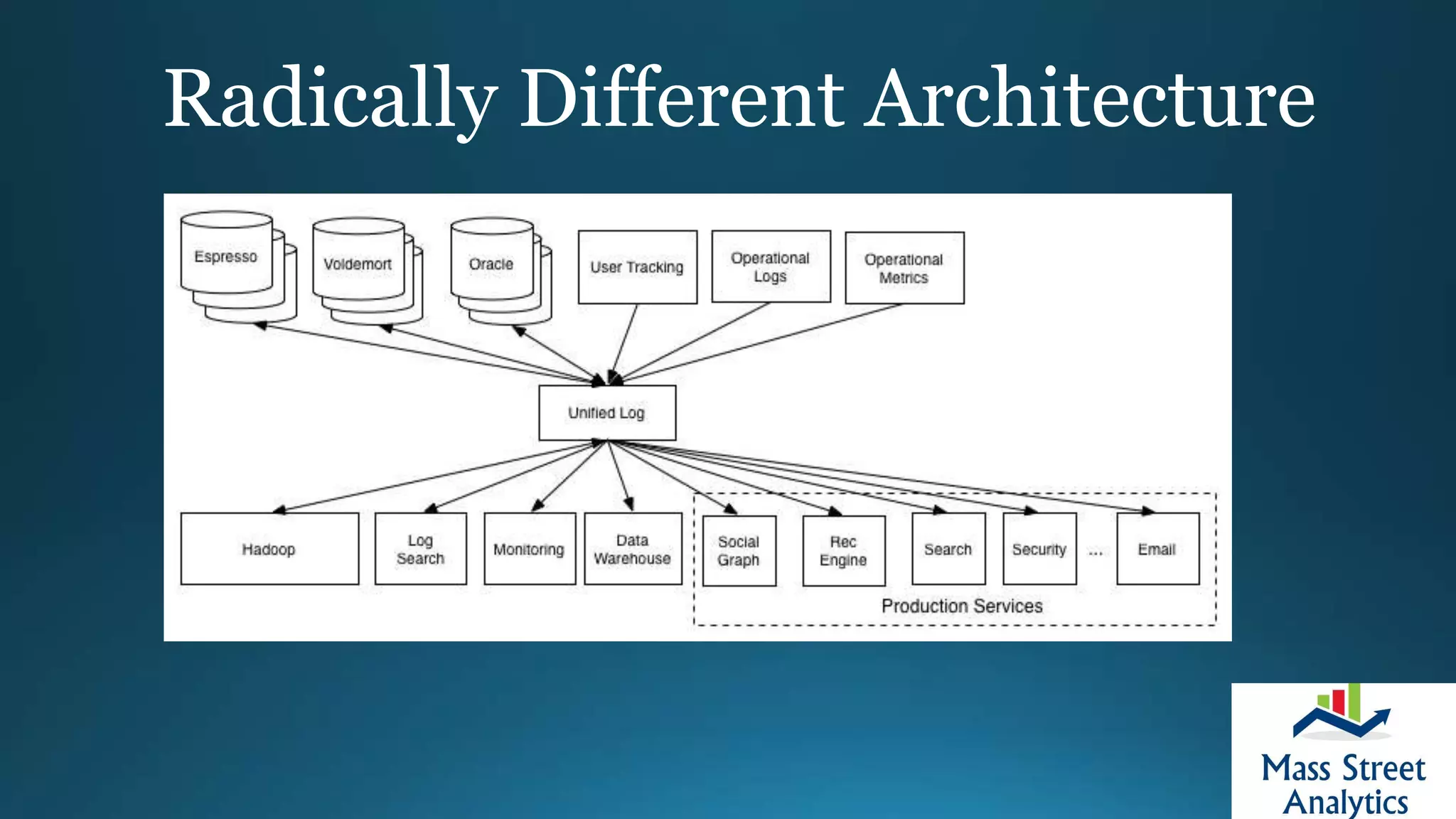


























This document provides an overview of architecting a first big data implementation. It defines key concepts like Hadoop, NoSQL databases, and real-time processing. It recommends asking questions about data, technology stack, and skills before starting a project. Distributed file systems, batch tools, and streaming systems like Kafka are important technologies for big data architectures. The document emphasizes moving from batch to real-time processing as a major opportunity.











































































