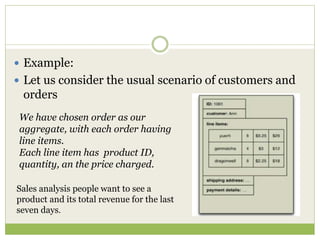
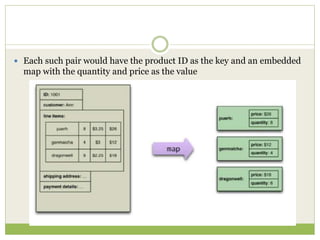
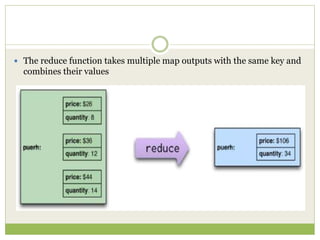
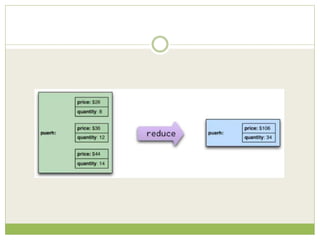
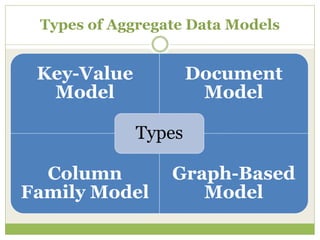
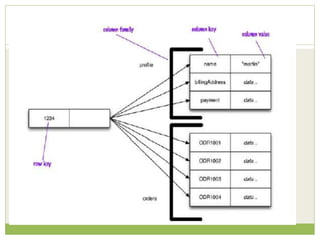
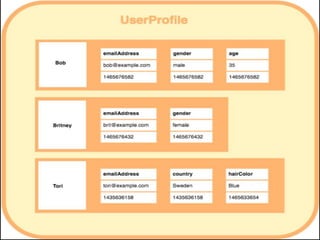
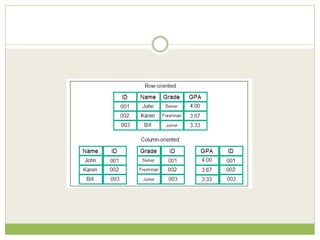
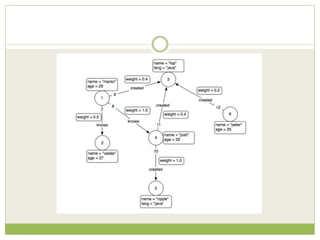
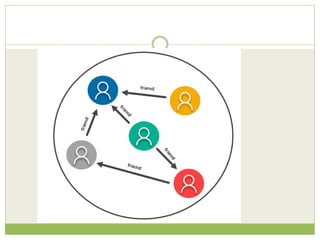
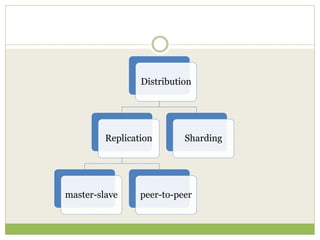
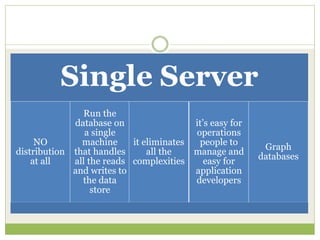
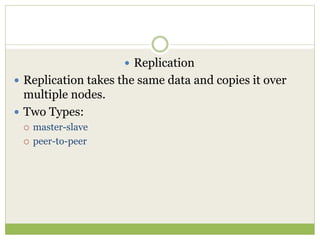
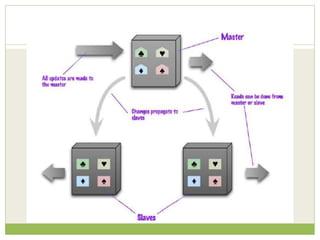
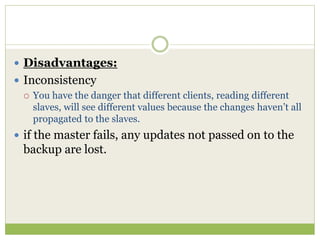
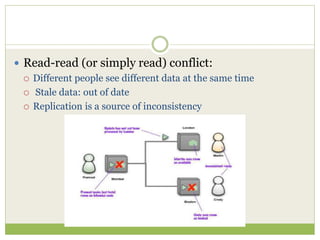
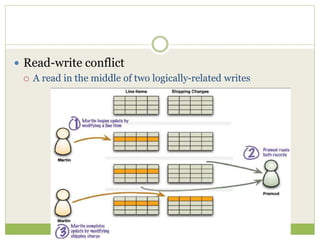
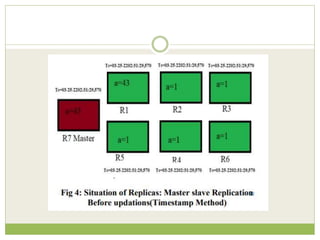
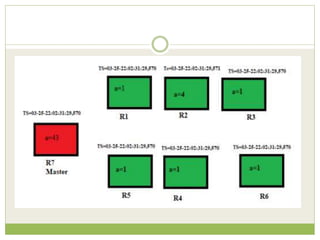
NoSQL databases are a type of DBMS designed to store large volumes of unstructured and semi-structured data with flexible data models, allowing for horizontal scalability and dynamic schema. They are utilized in various formats including key-value, document, column-family, and graph models, each offering unique advantages for specific use cases. Key benefits of NoSQL include high performance, flexibility, and often, eventual consistency, with trade-offs between consistency and availability as described by the CAP theorem.


























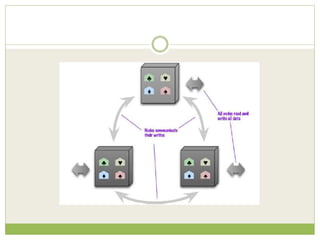



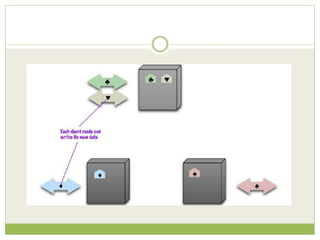





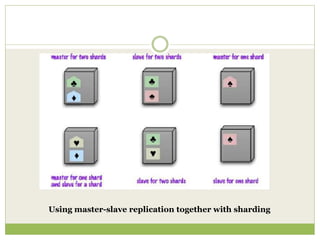

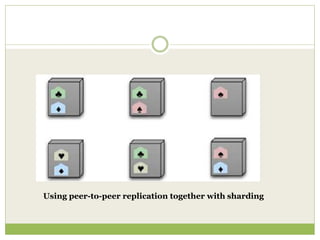







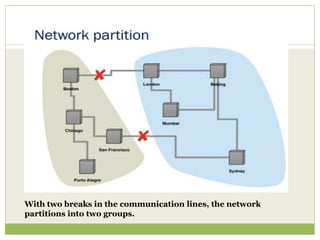
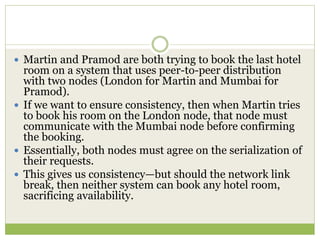
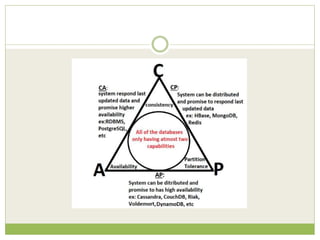
![The CAP Theorem
Proposed by Eric Brewer in 2000 and given a formal
proof by Seth Gilbert and Nancy Lynch [Lynch and
Gilbert] a couple of years later.
“Given the three properties of Consistency,
Availability, and Partition tolerance, you can only get
two.”](https://image.slidesharecdn.com/2-240304110203-98cb70c7/85/2-Introduction-to-NOSQL-Core-concepts-pptx-59-320.jpg)
















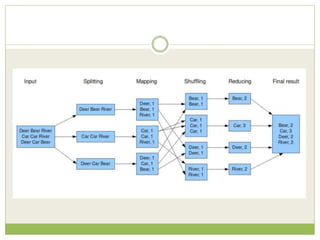
![ This programming model gained prominence with
Google’s MapReduce framework [Dean and
Ghemawat, OSDI-04].
A widely used open-source implementation is part of
the Apache Hadoop project.
The name “map-reduce” reveals its inspiration from
the map and reduce operations on collections in
functional programming languages](https://image.slidesharecdn.com/2-240304110203-98cb70c7/85/2-Introduction-to-NOSQL-Core-concepts-pptx-84-320.jpg)