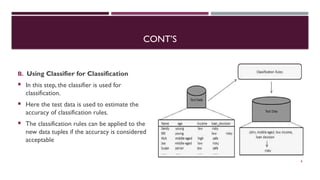
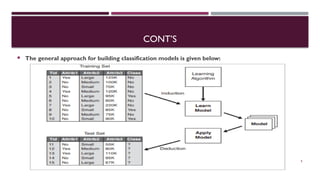
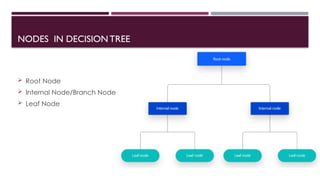
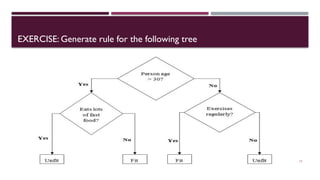
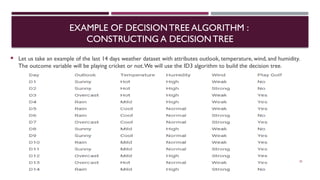
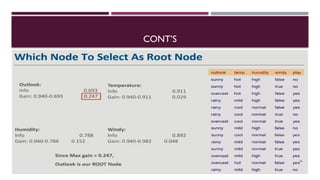
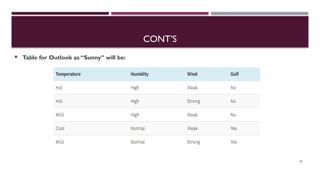
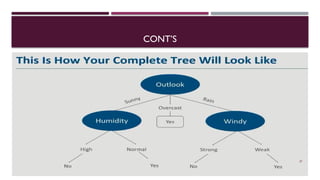
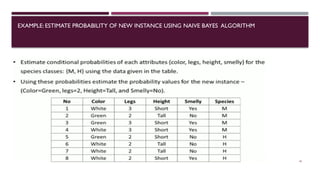
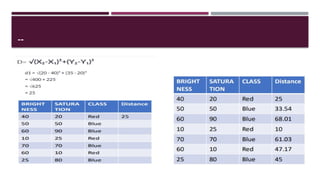
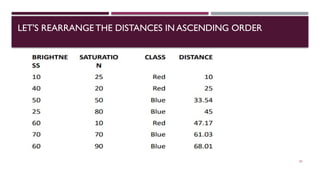
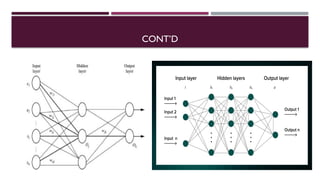
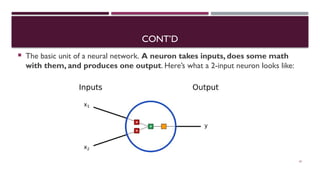
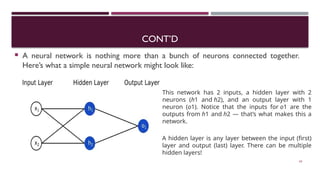
Chapter 3 discusses classification and prediction in machine learning, defining classification as the categorization of data into classes based on labeled data for training. It covers various classification methods including decision trees, Bayesian classification, and support vector machines, highlighting the importance of classifier accuracy and data preprocessing. The document also elaborates on the processes involved in building classifiers, the use of metrics like information gain and Gini index for attribute selection, and provides examples of practical applications of classification.