Download as PDF, PPTX



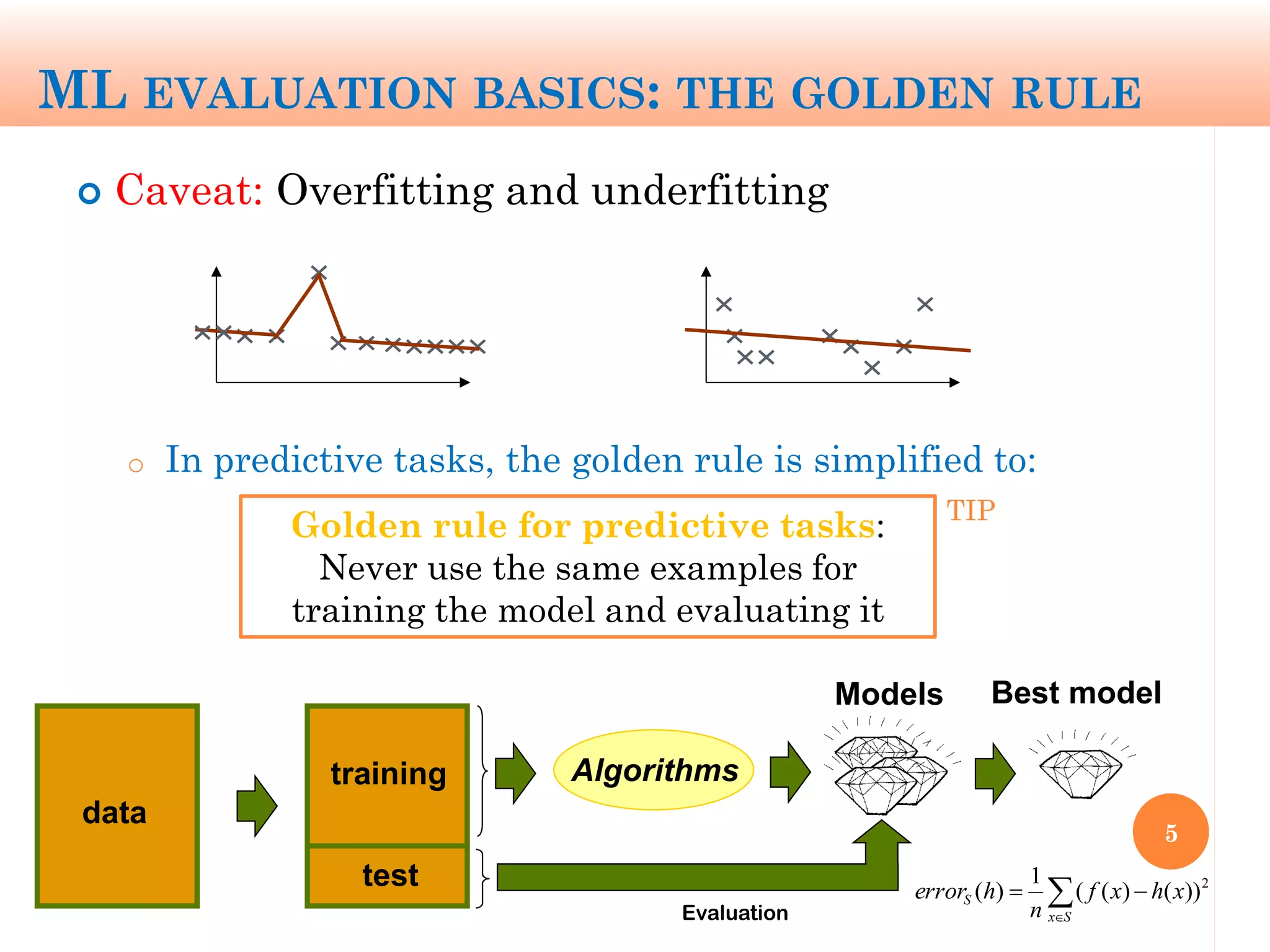
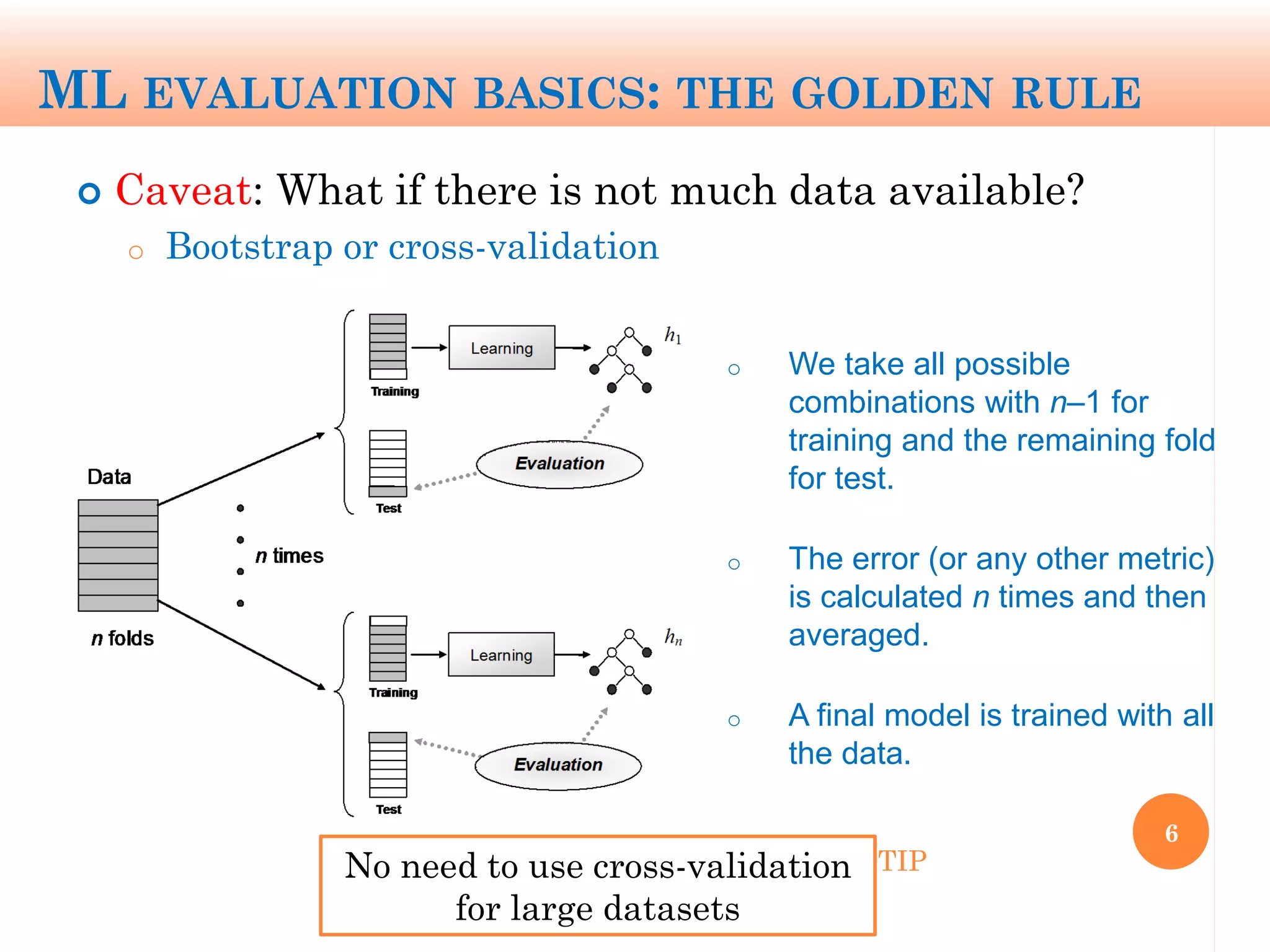

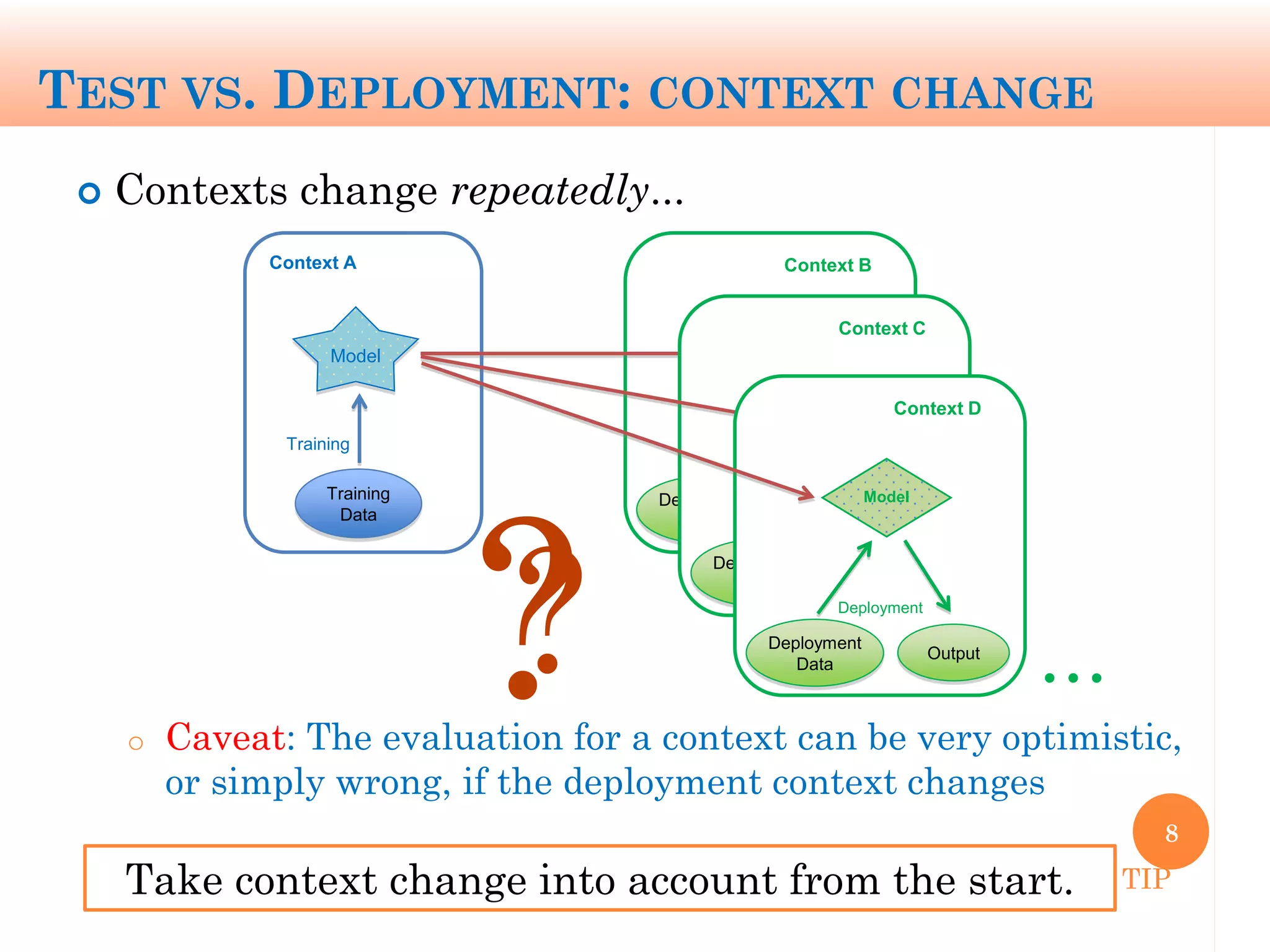



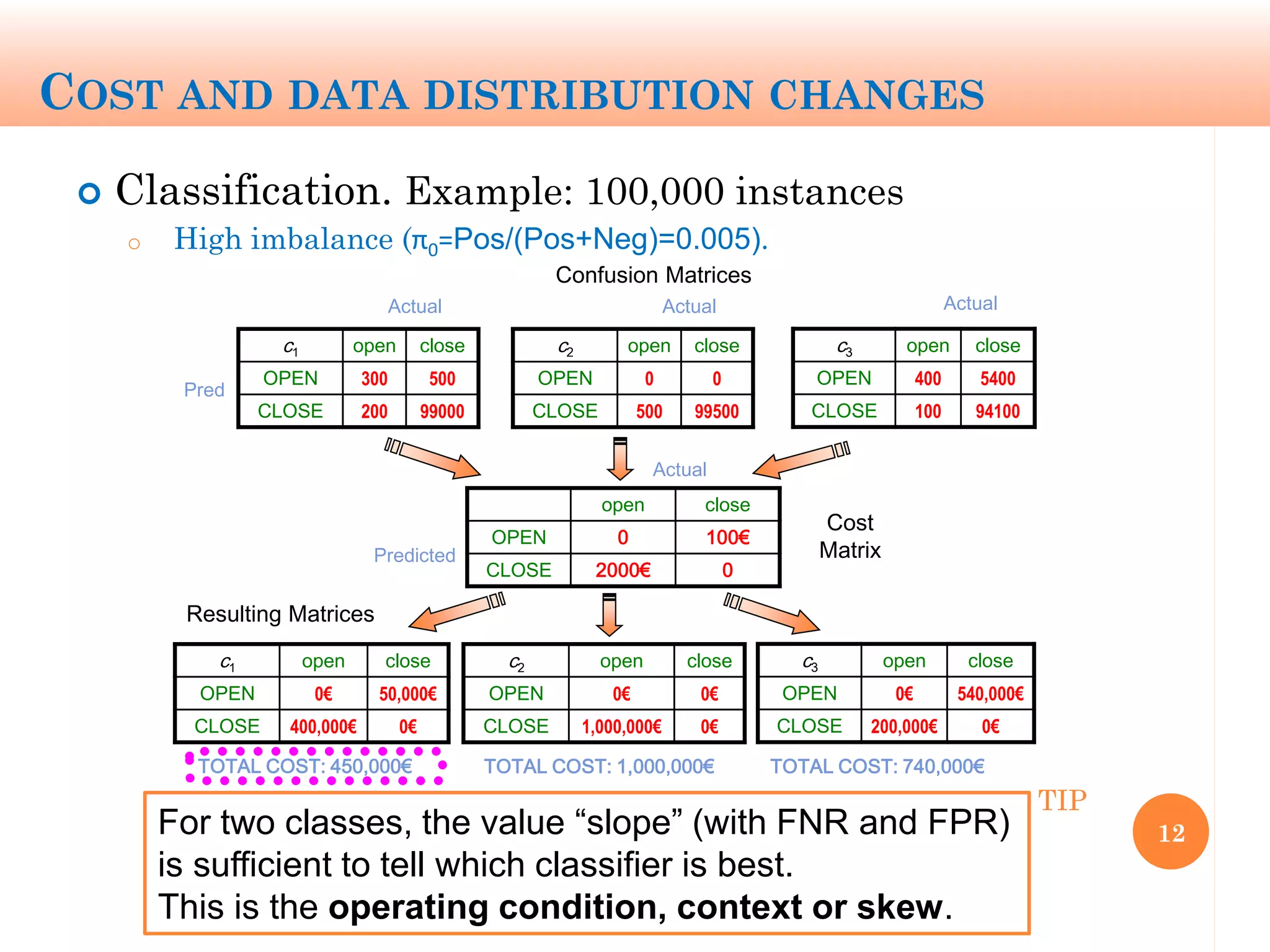

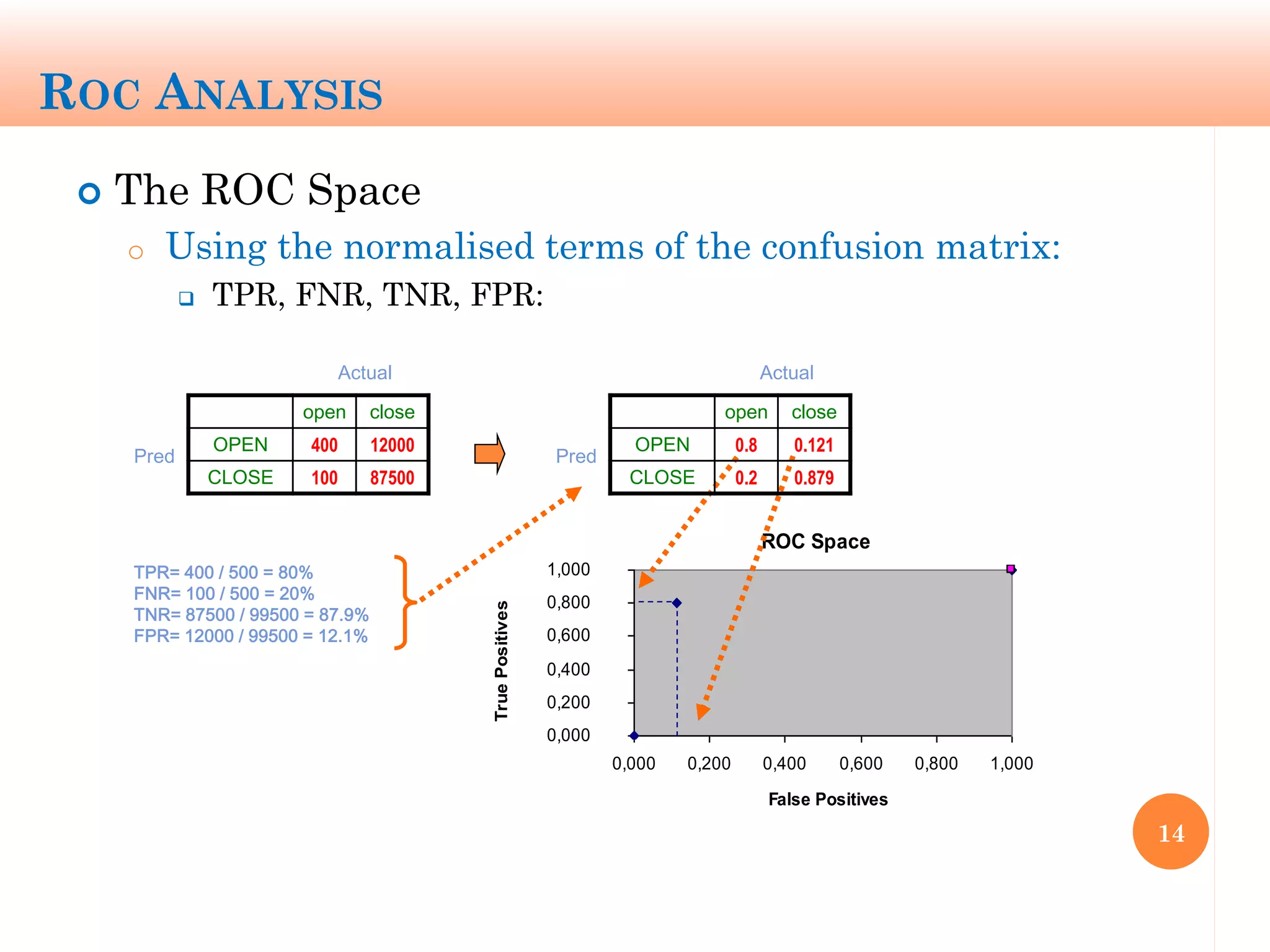
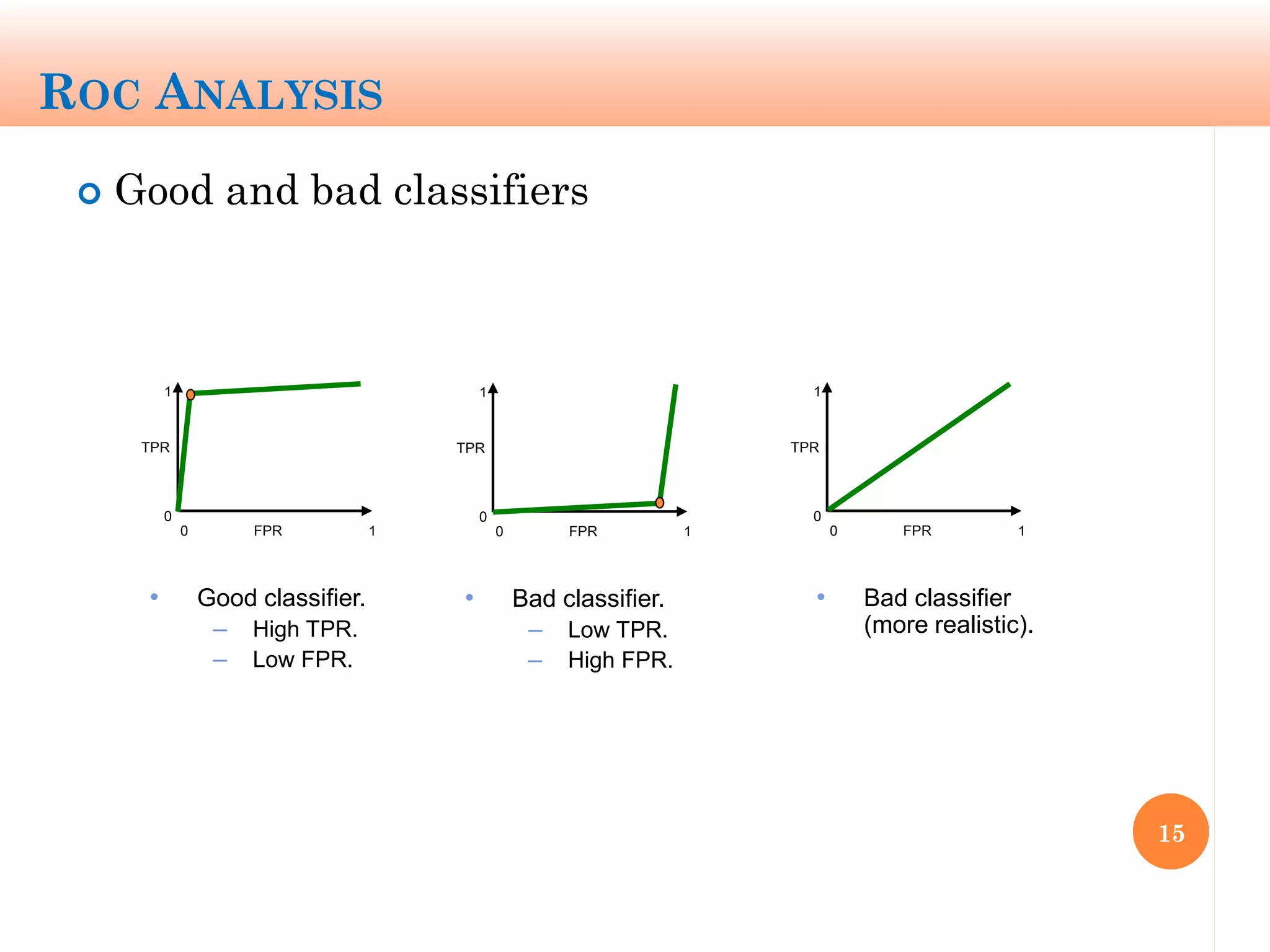
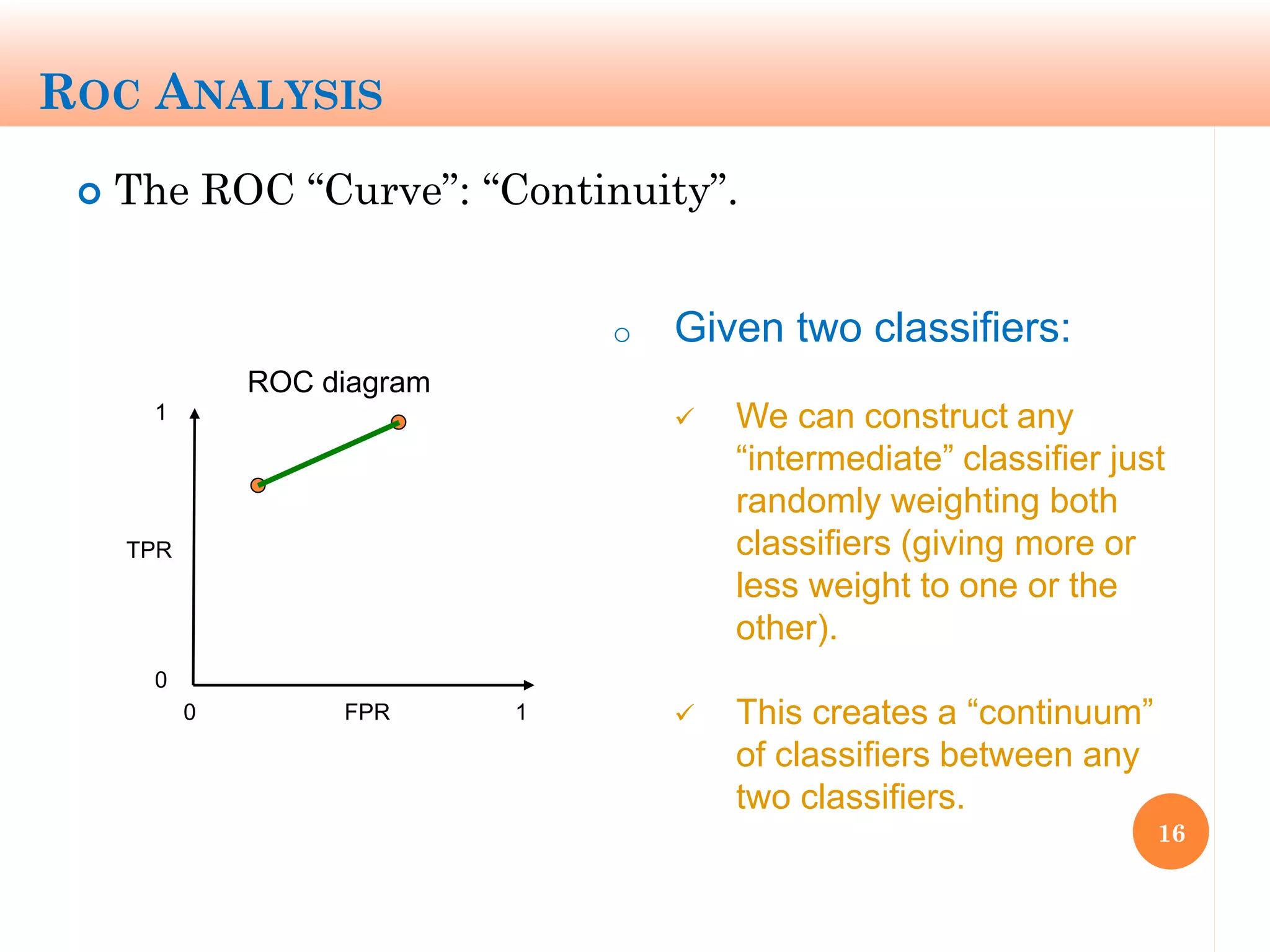
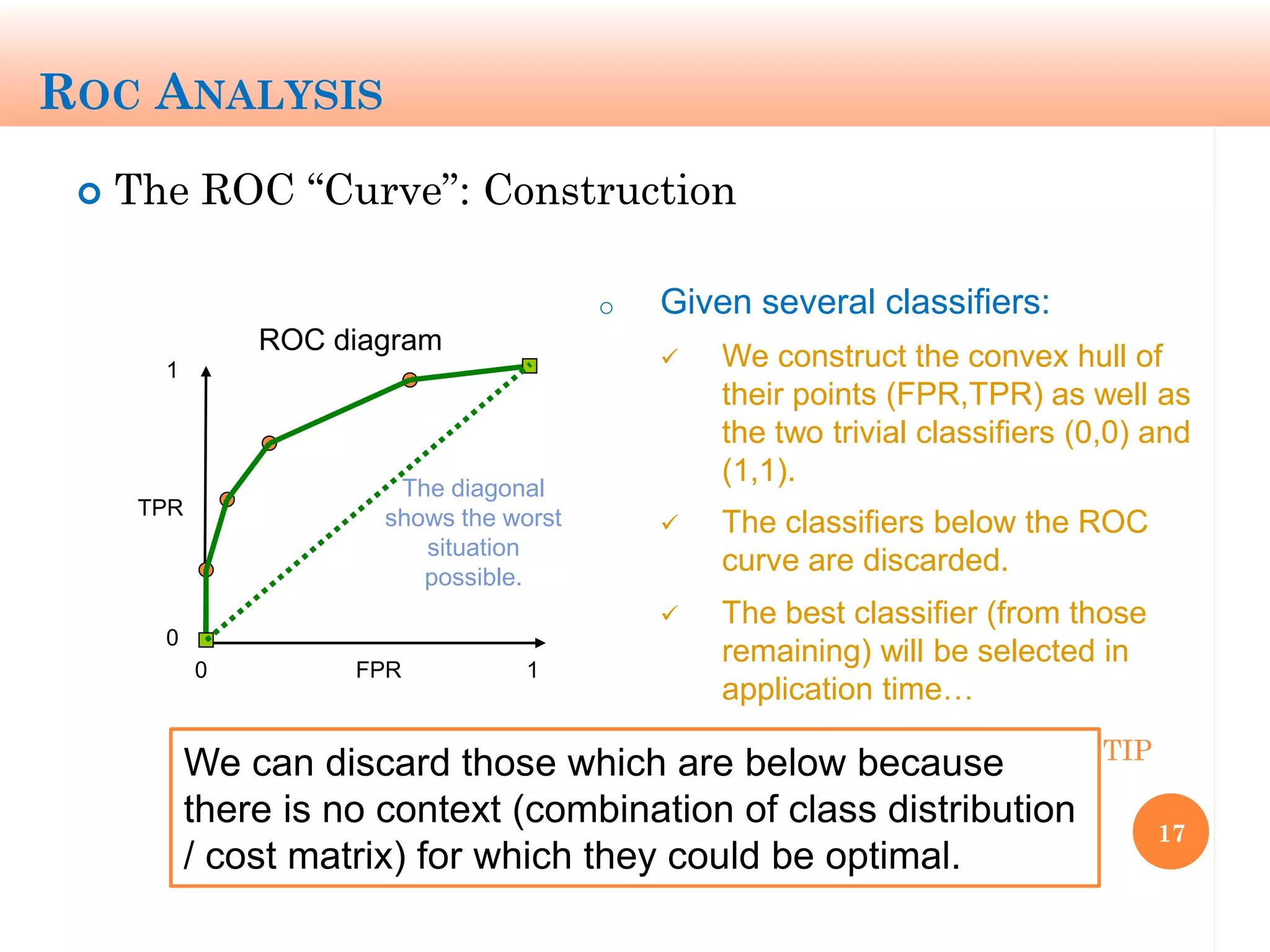
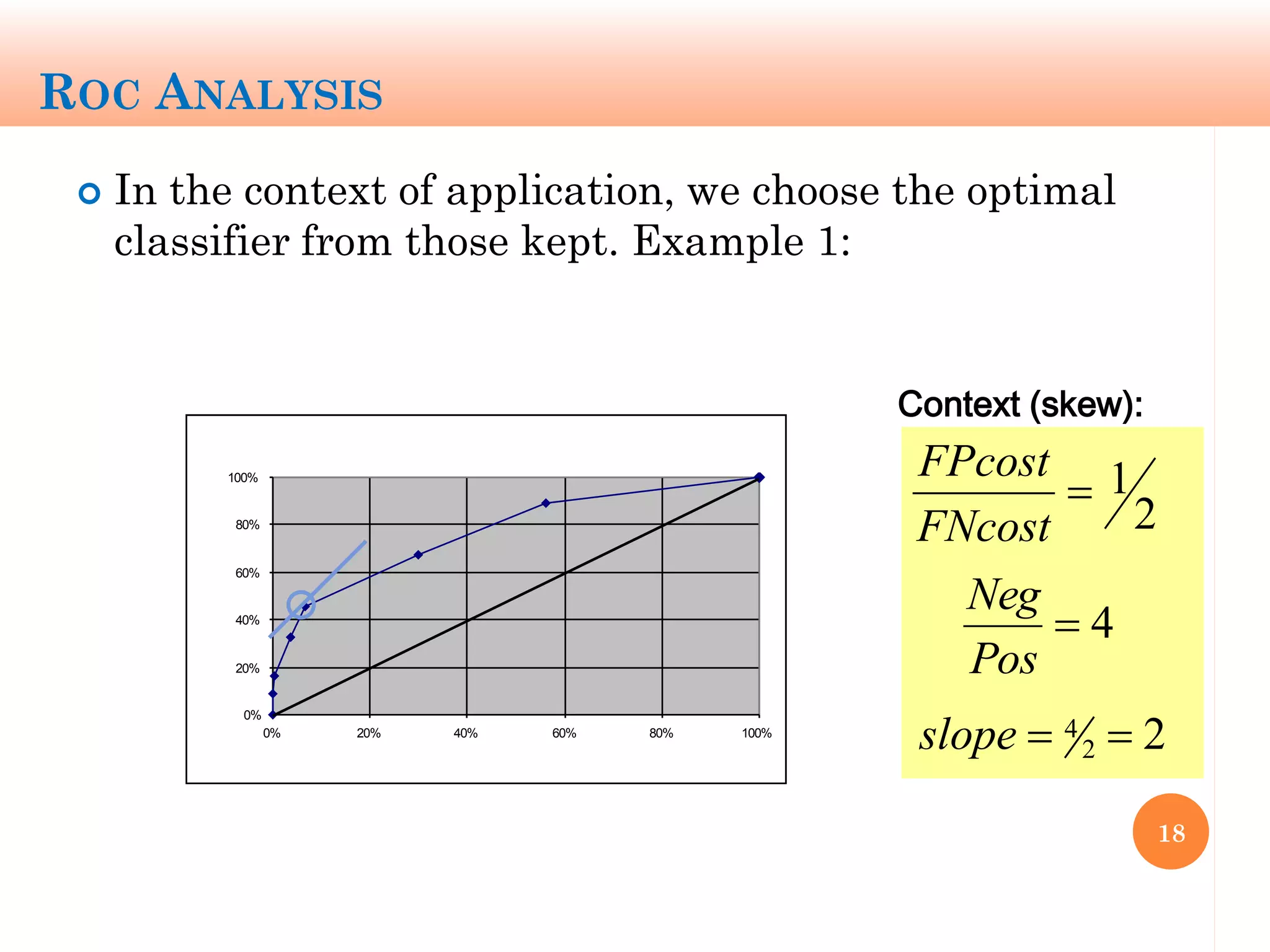
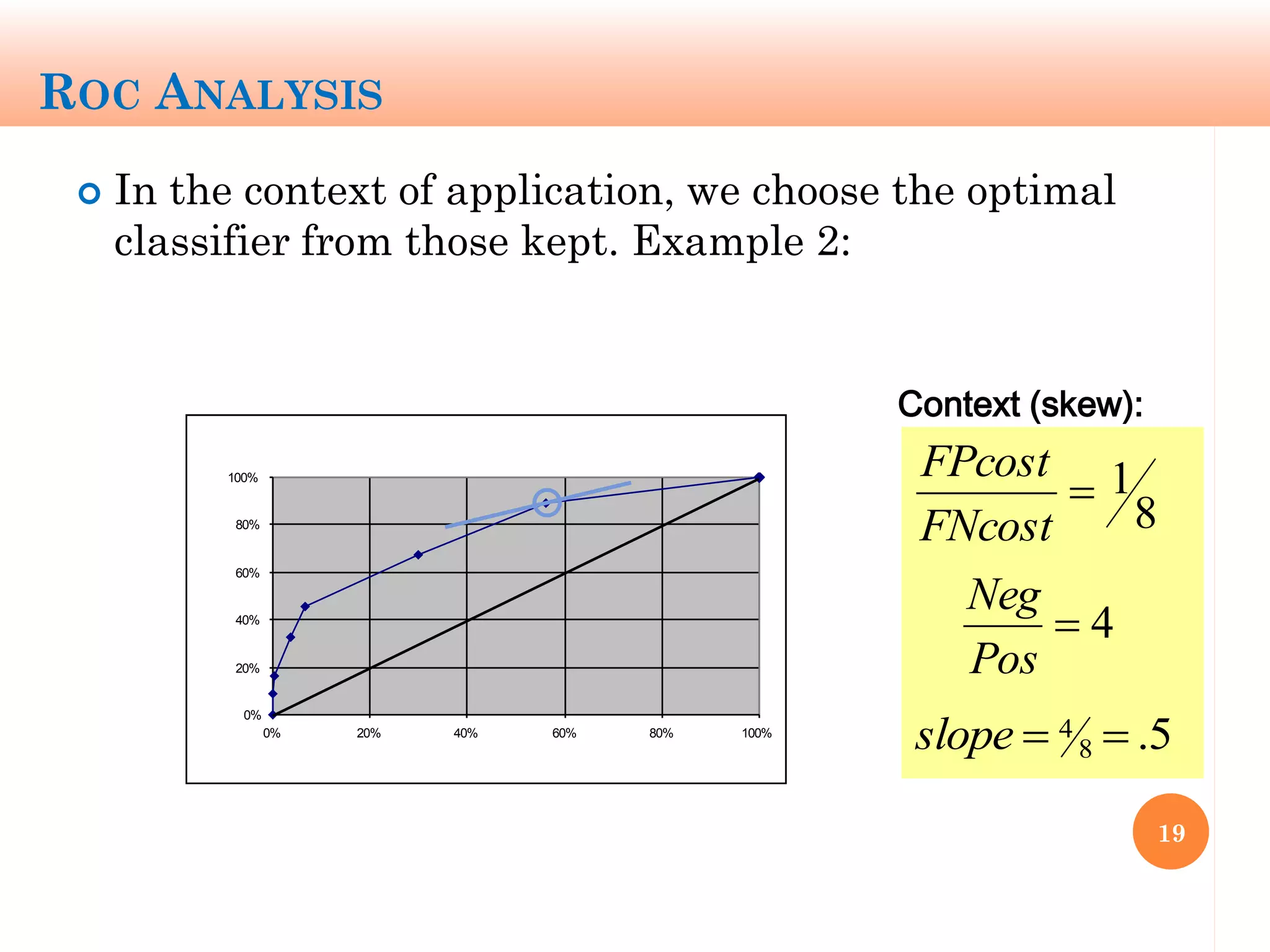

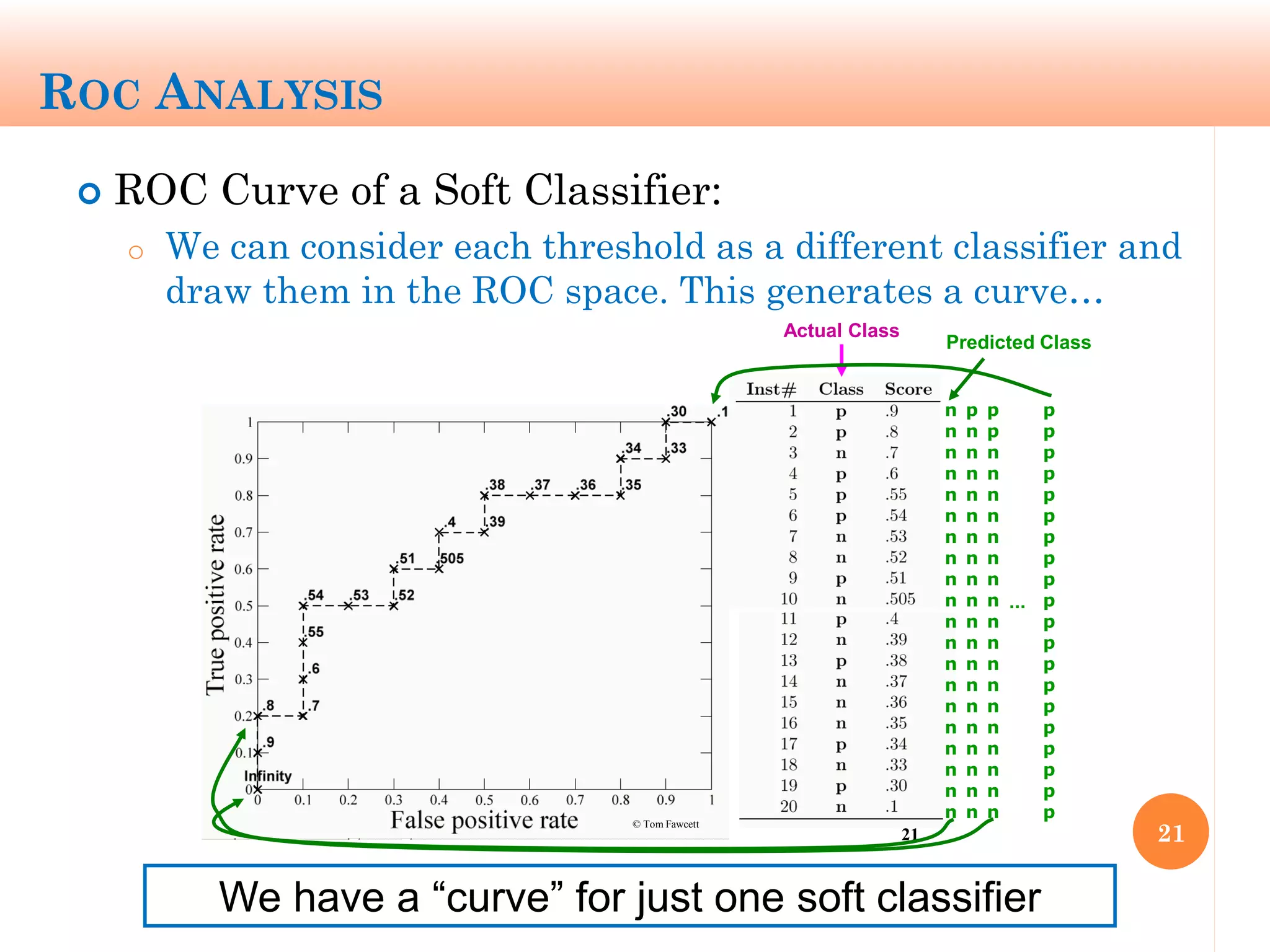
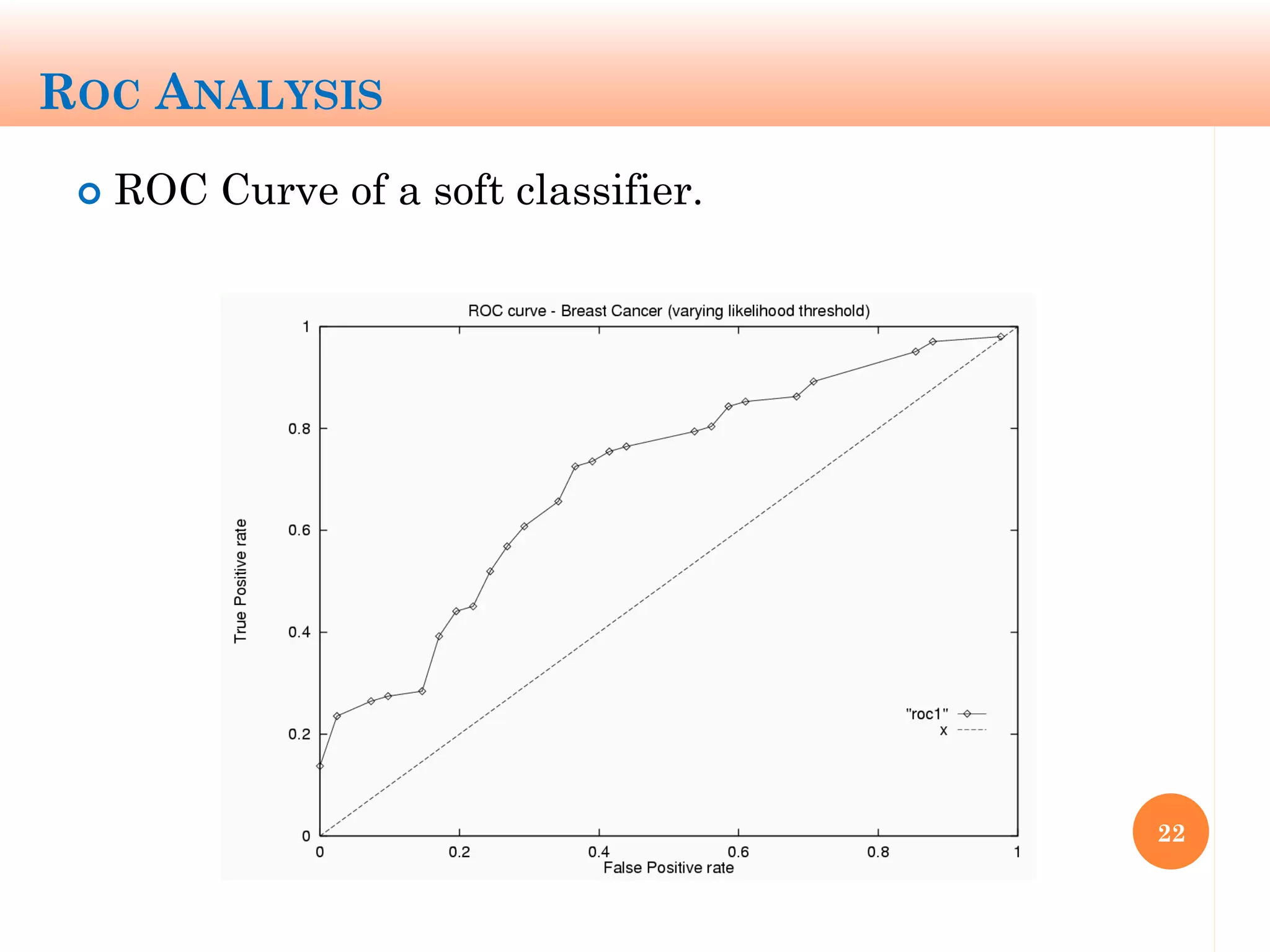
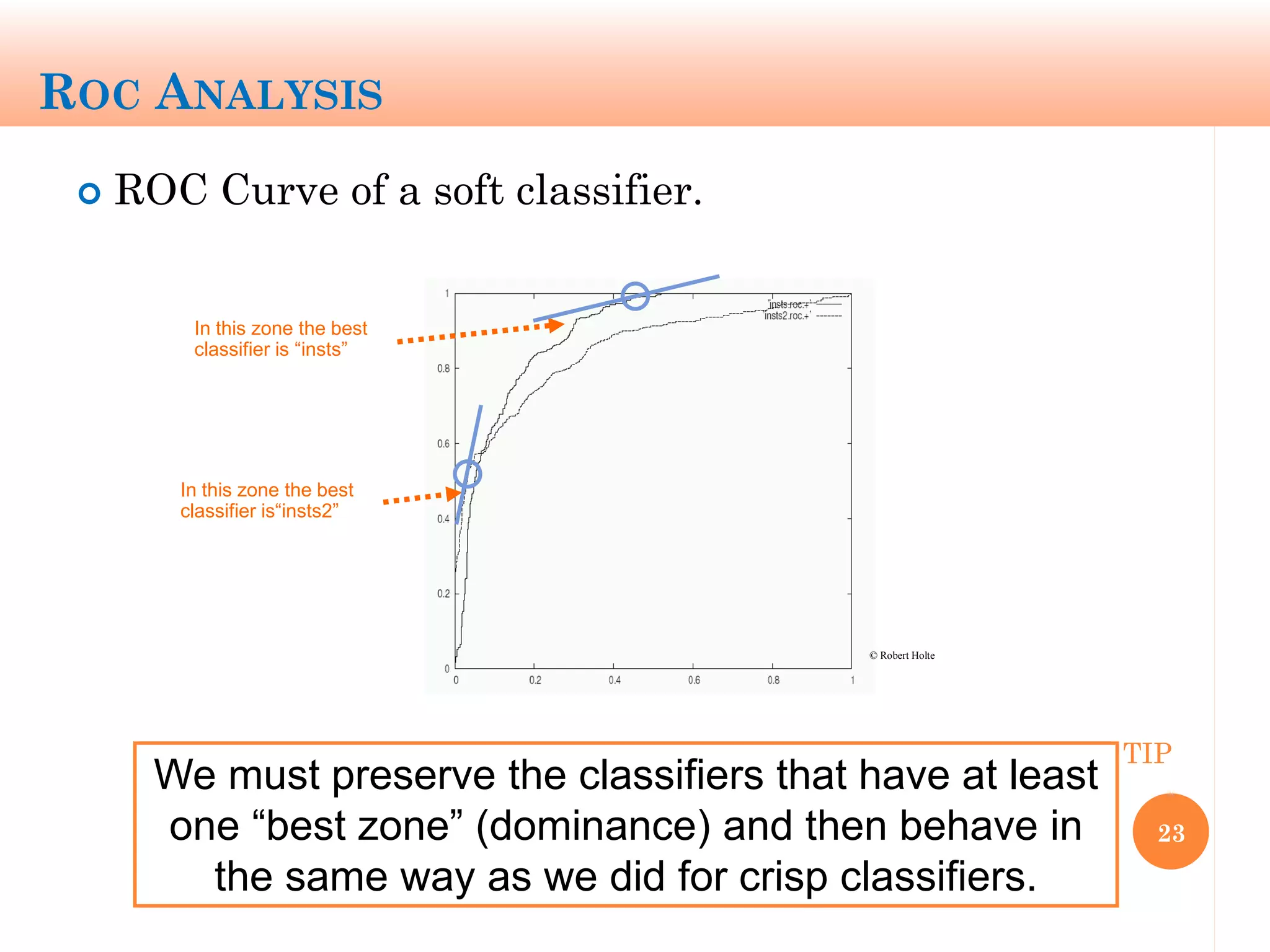






The document discusses machine learning performance evaluation, emphasizing the importance of context and proper measurement metrics for model effectiveness during deployment. It outlines key principles such as avoiding overstatement of model performance due to overfitting, the necessity of considering context changes, and using ROC analysis to assess classifier effectiveness across different conditions. Additionally, it highlights the significance of soft classifiers and the need for cost-sensitive evaluation in complex scenarios, including multiclass and regression problems.























































































