Downloaded 26 times



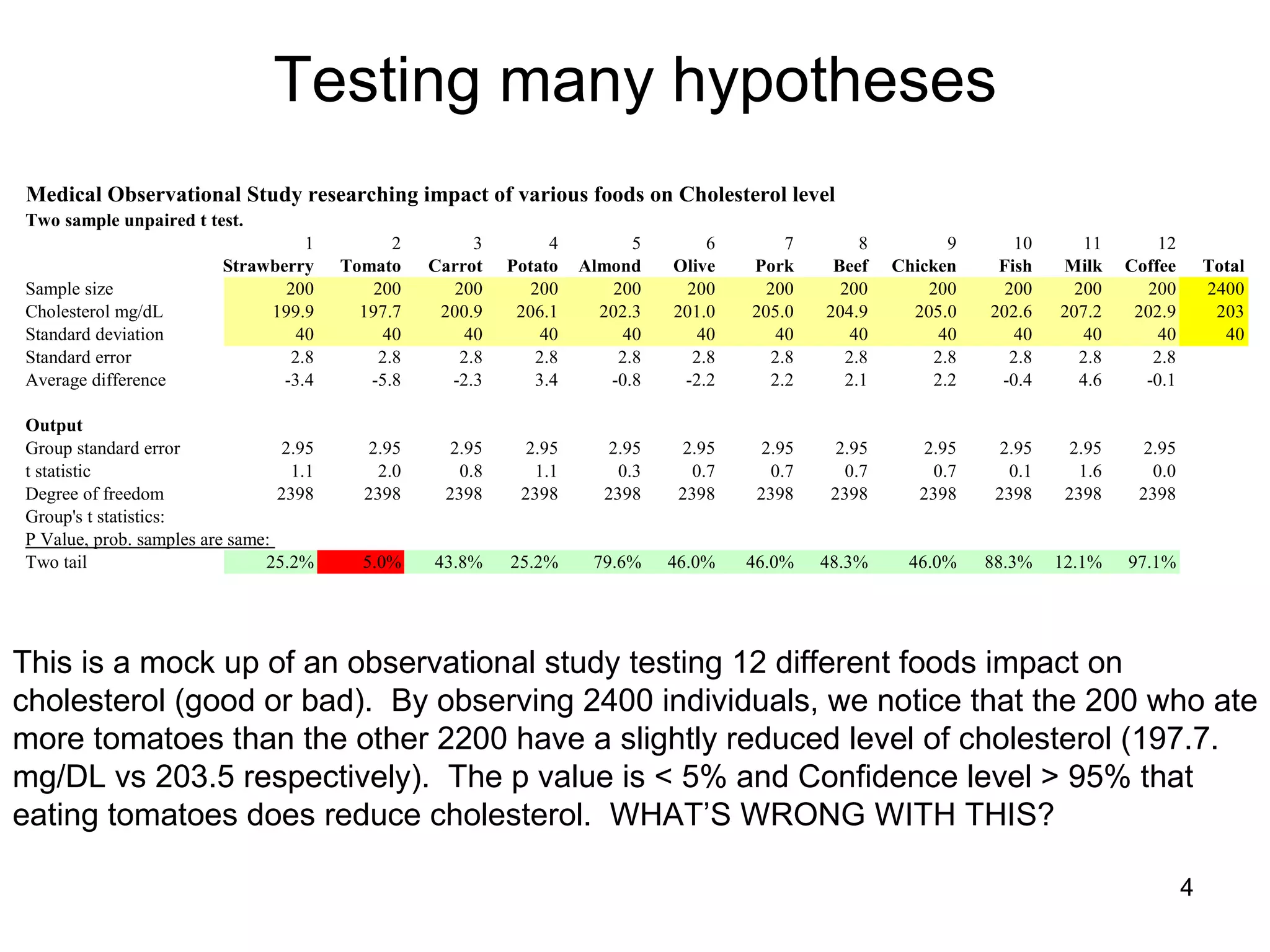
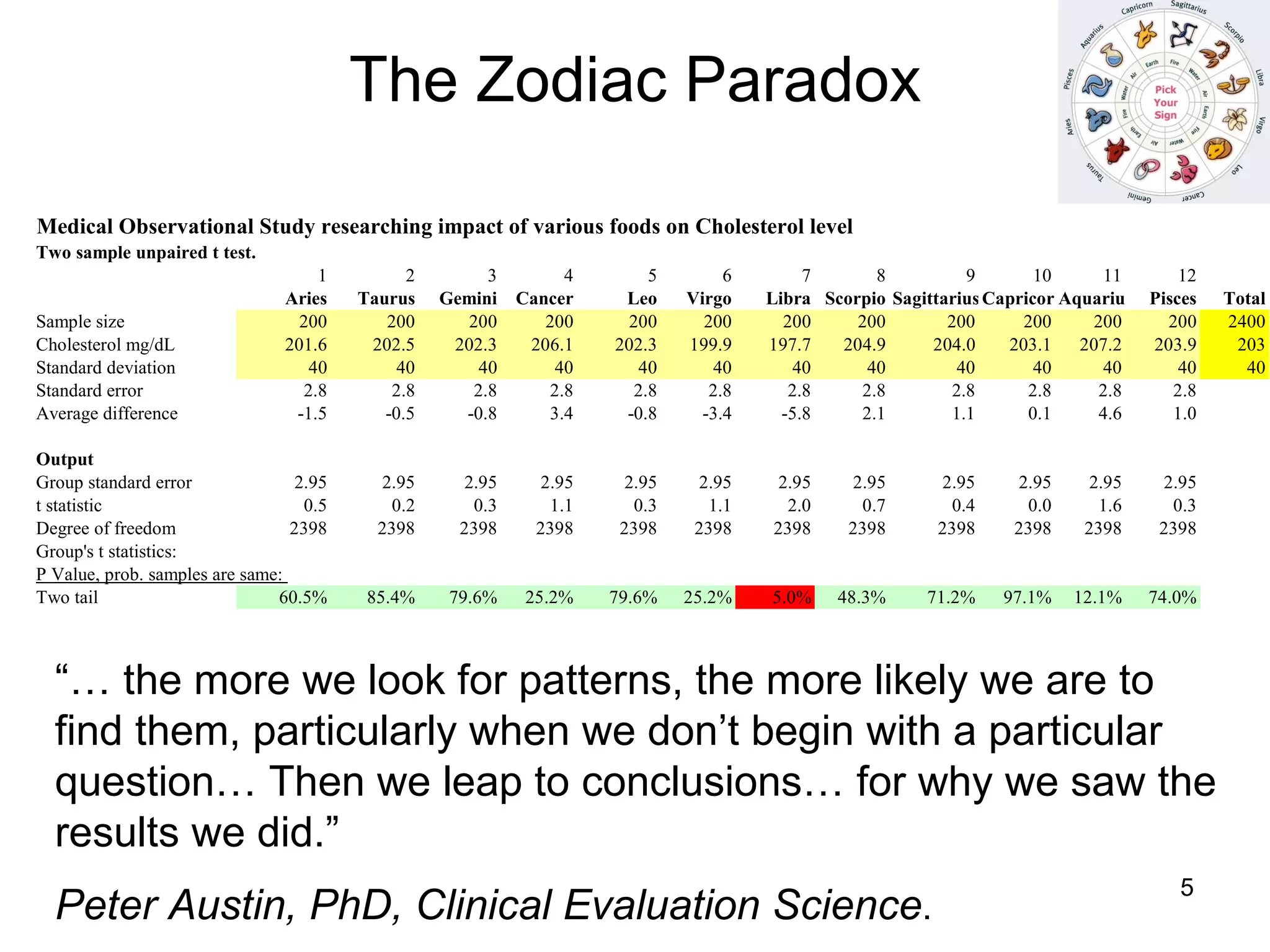

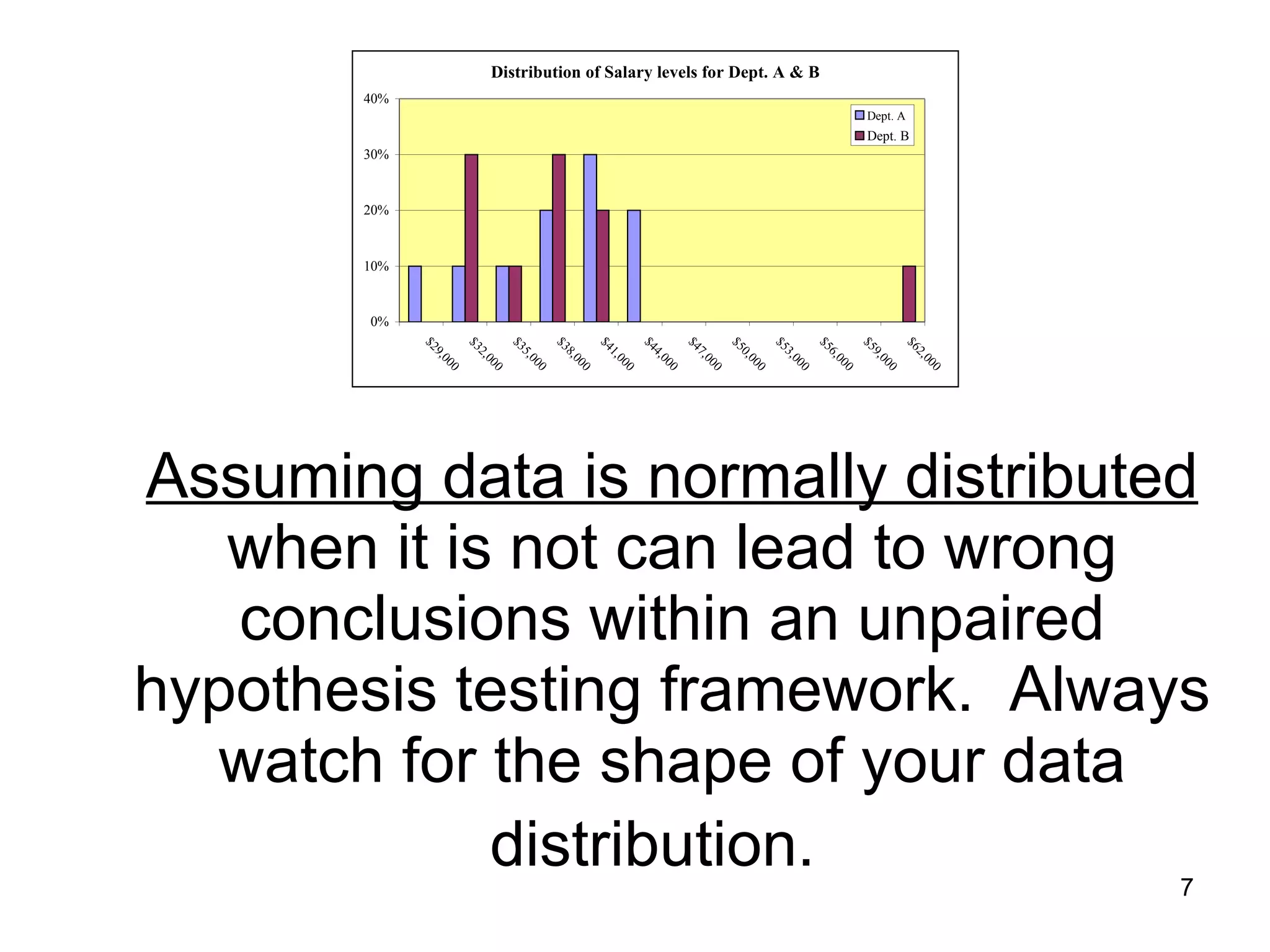
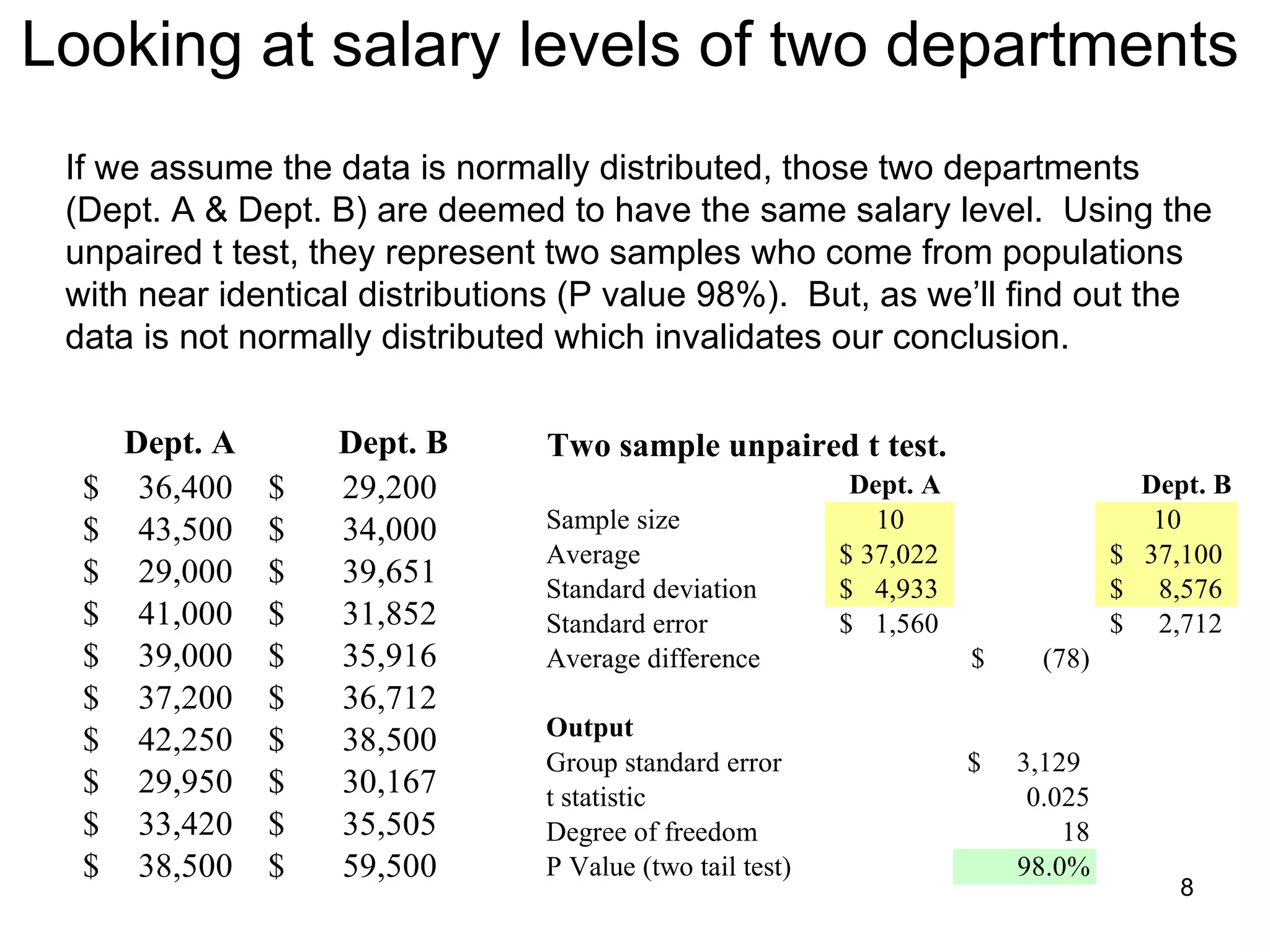
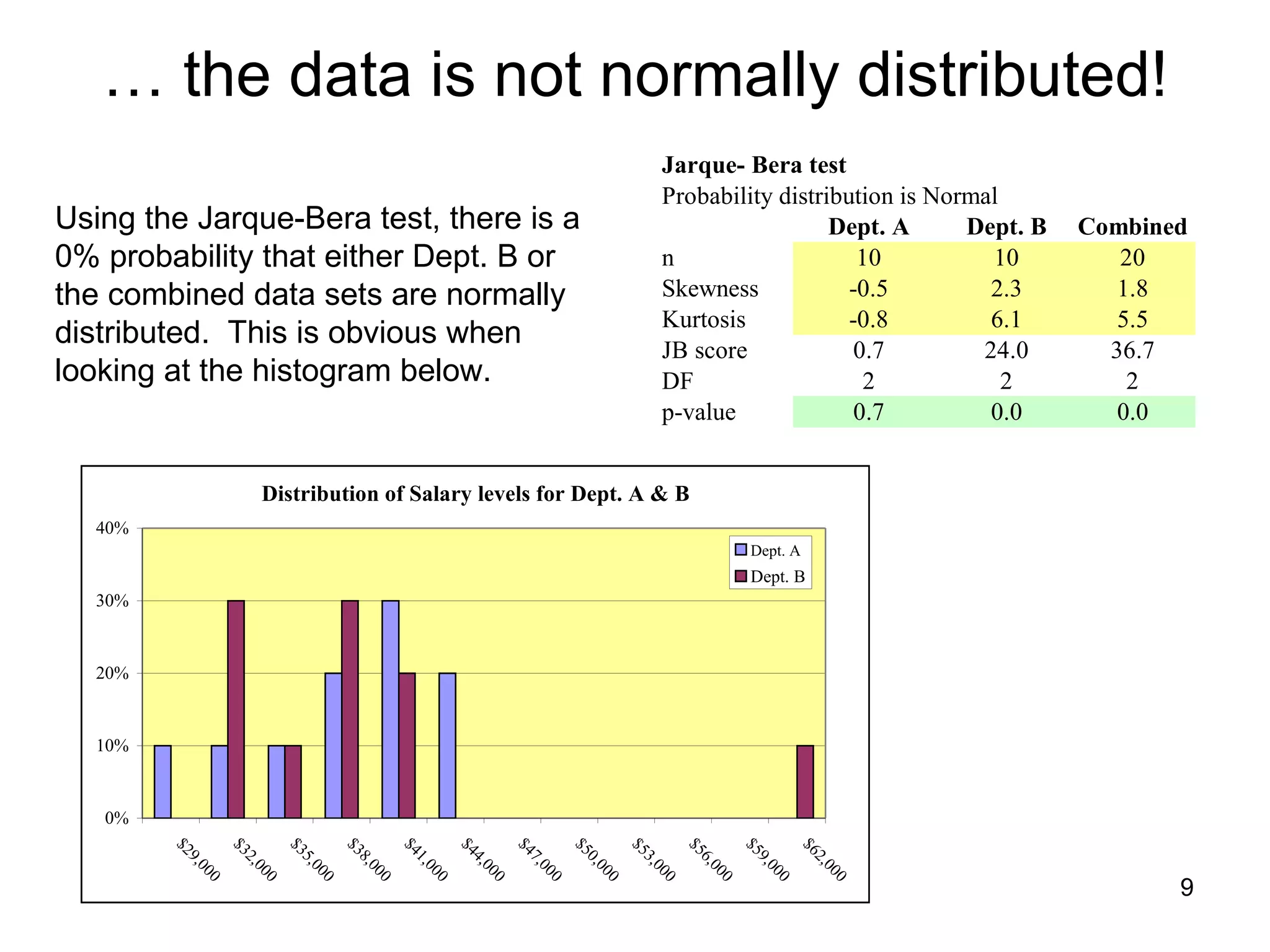
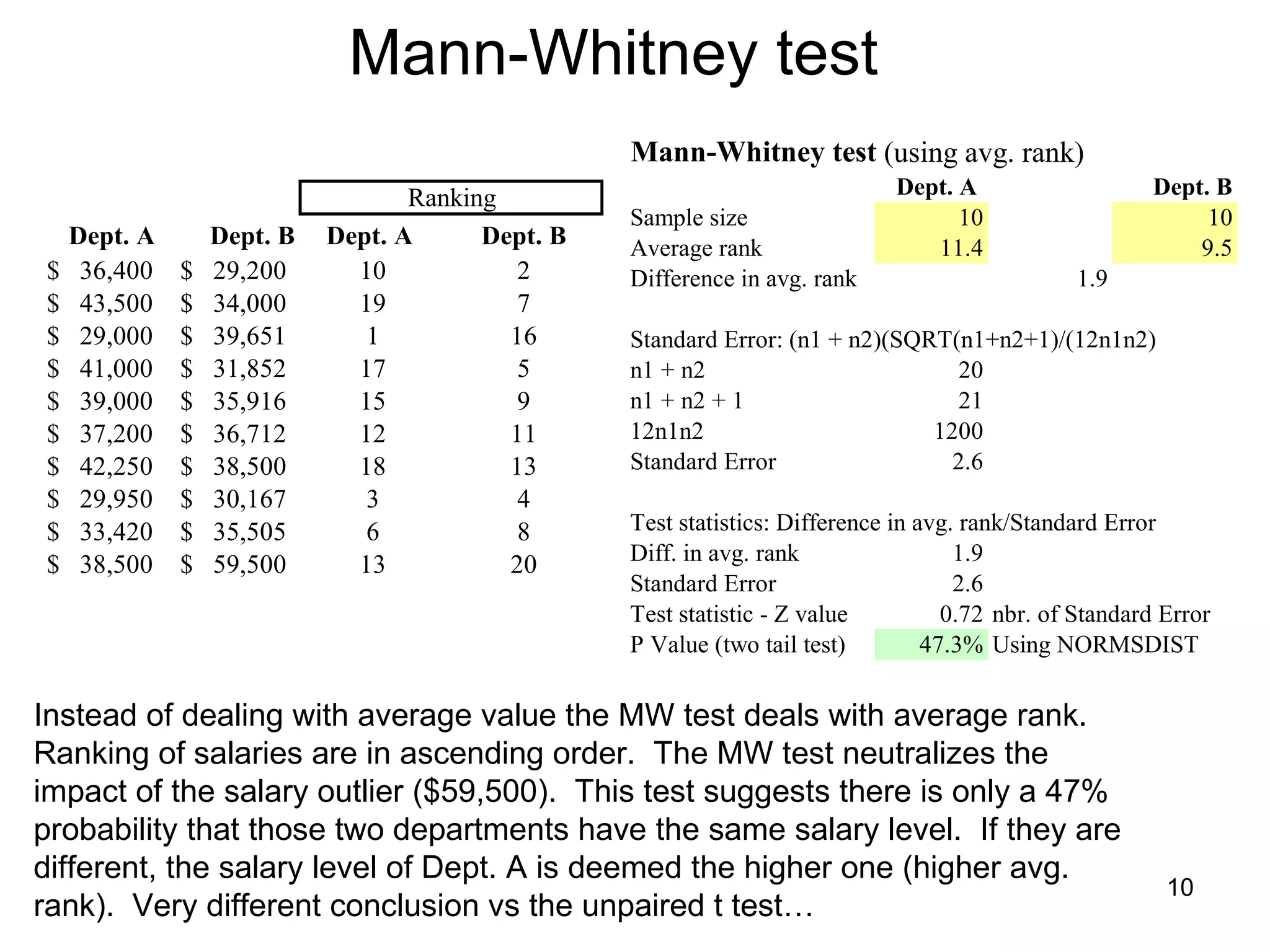

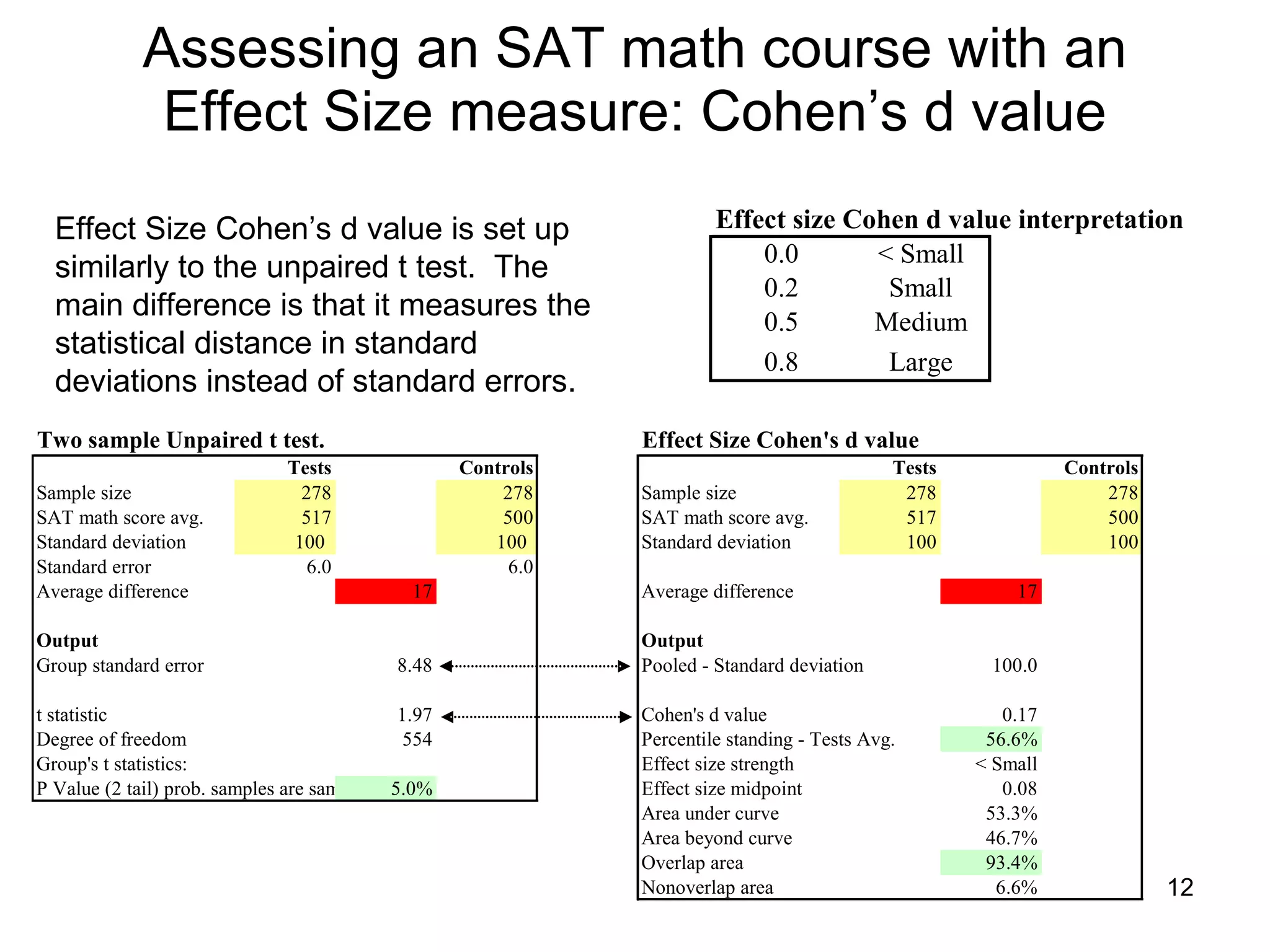
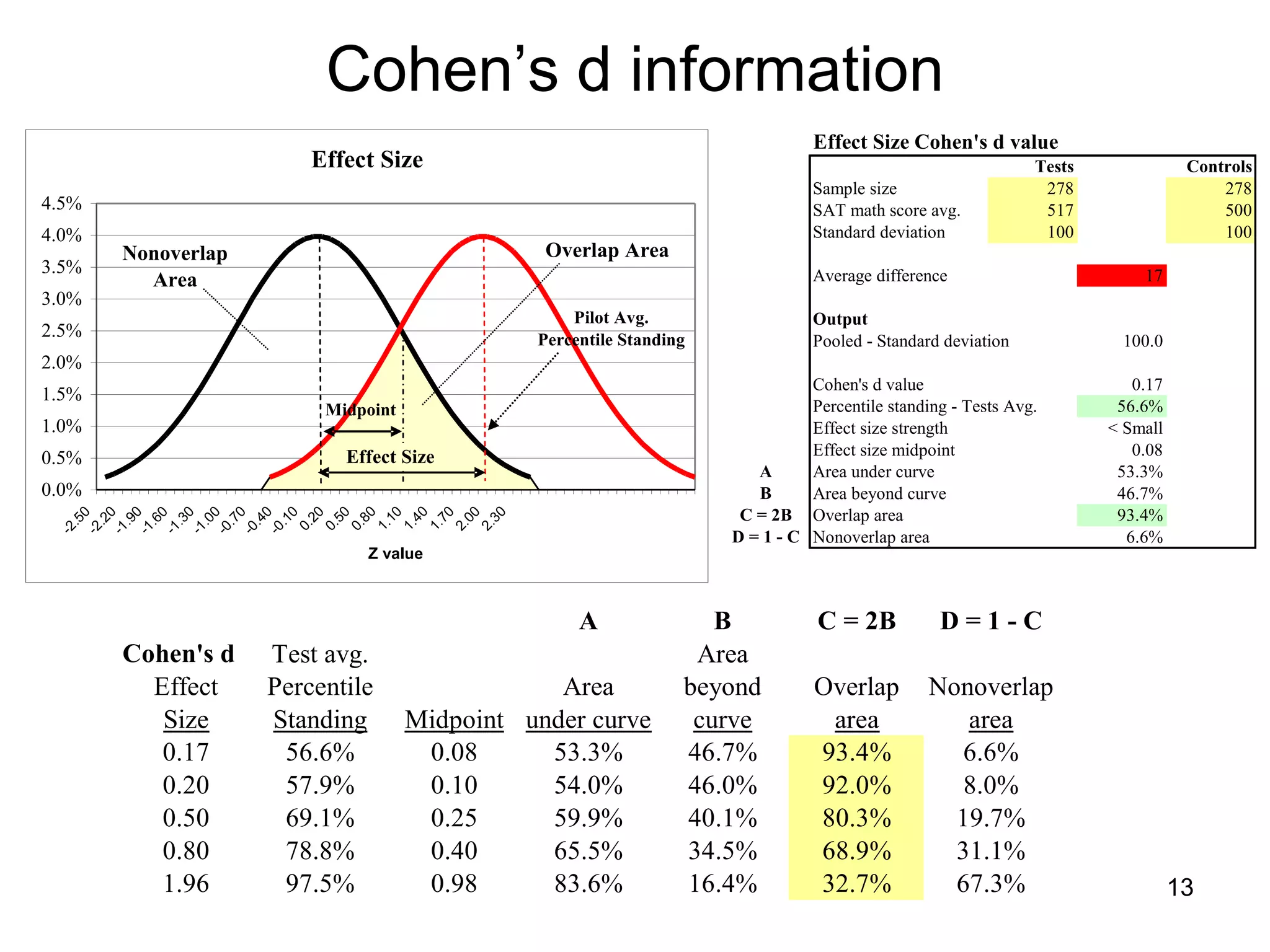




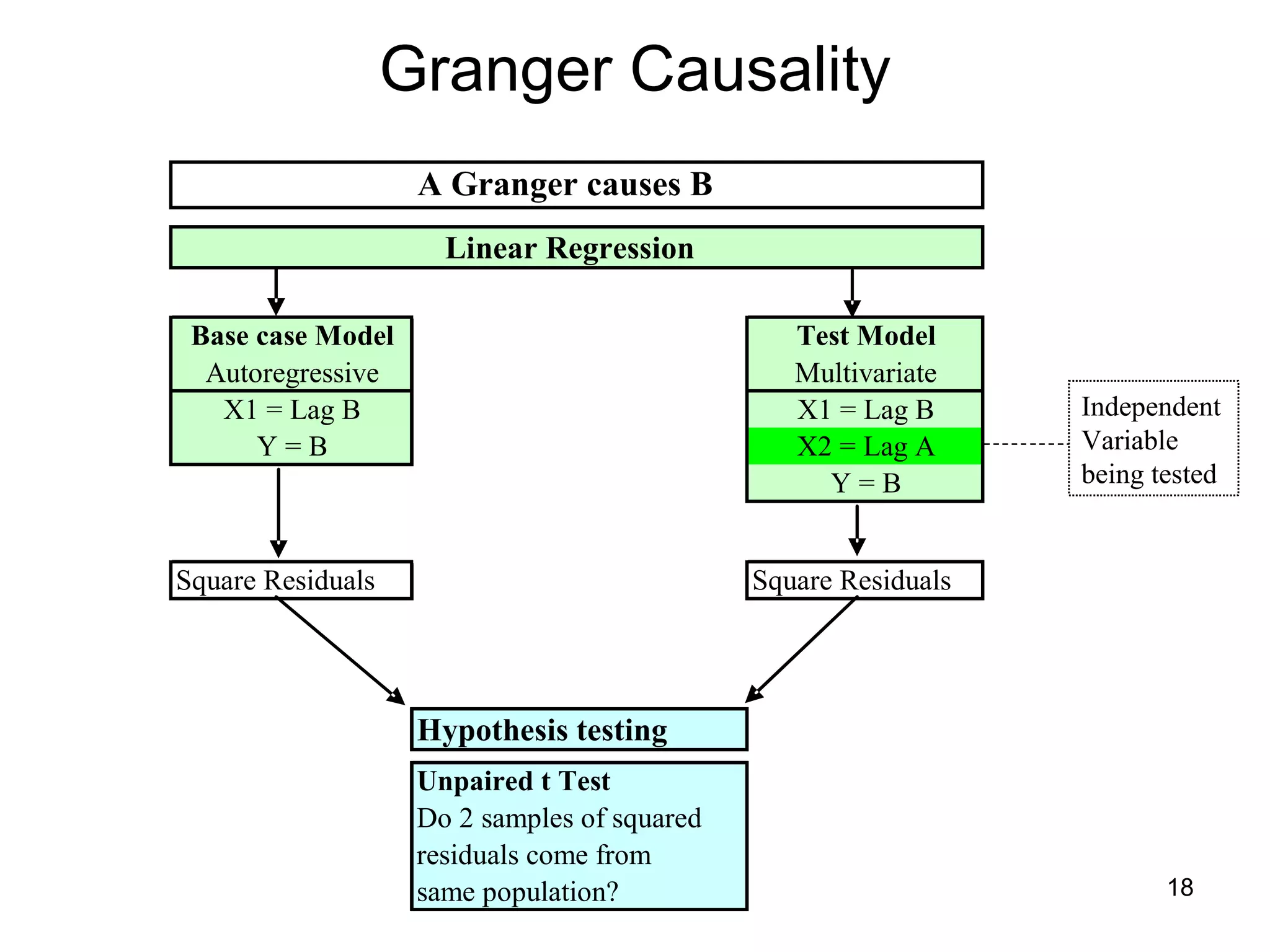
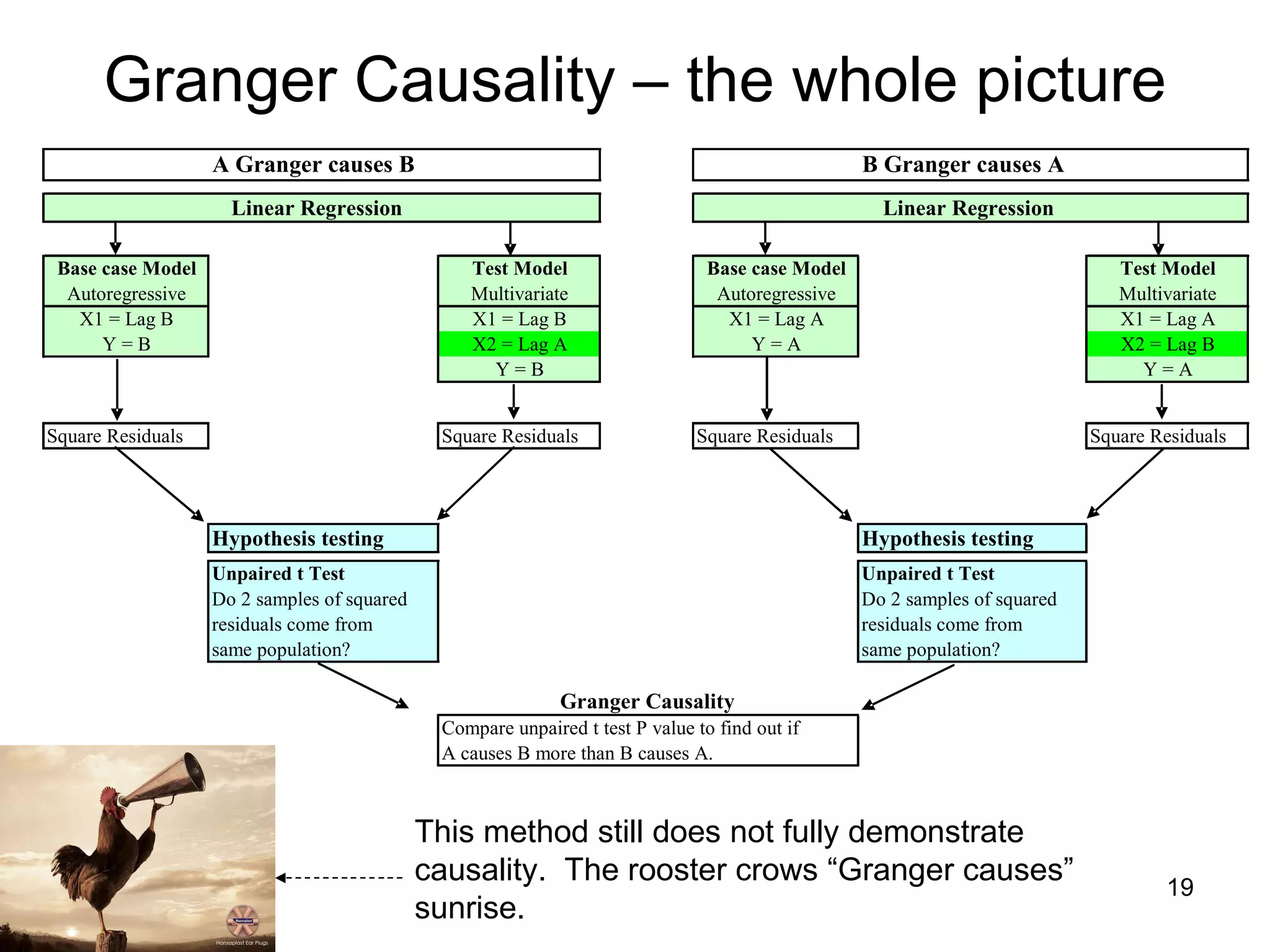

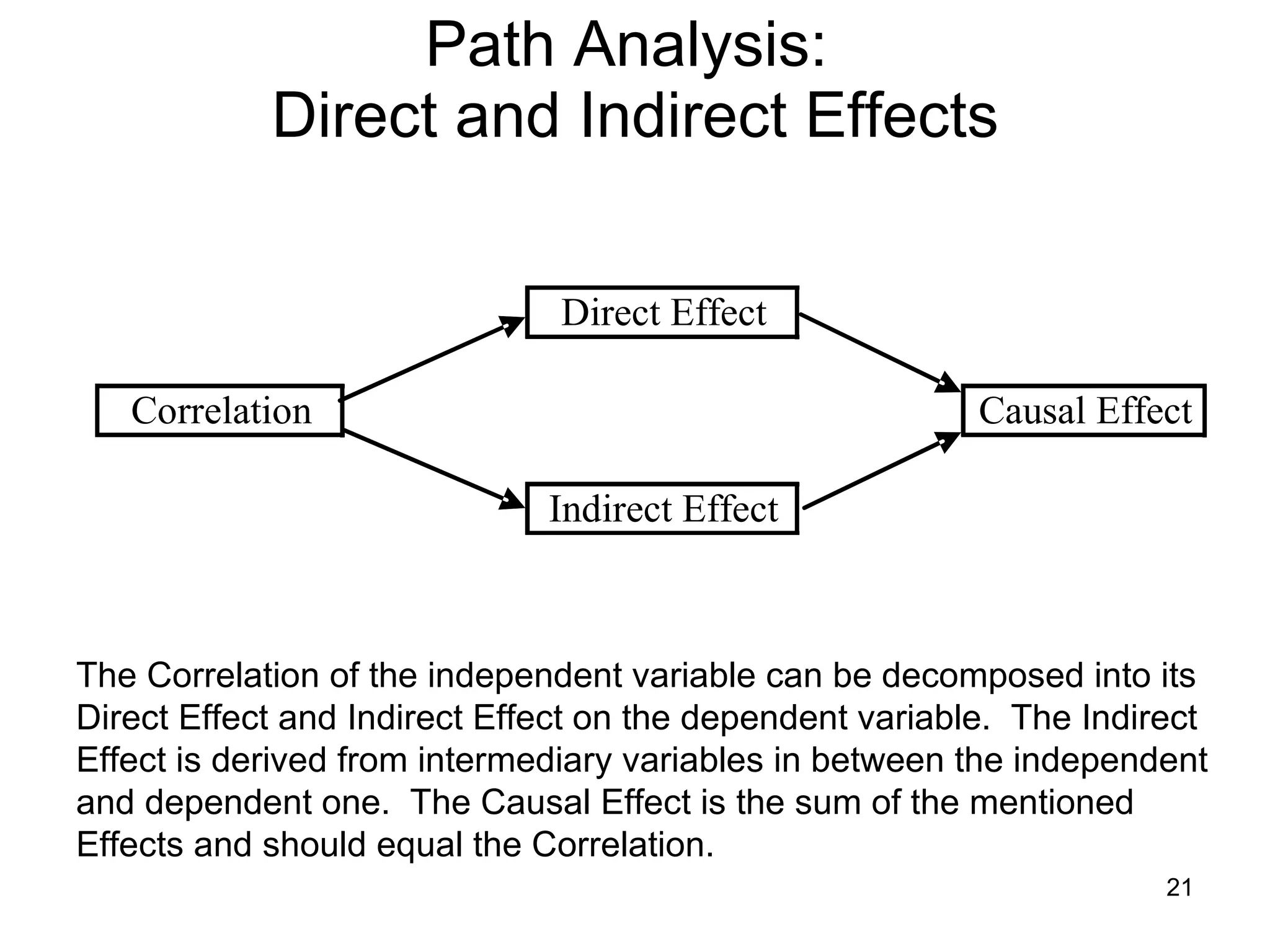
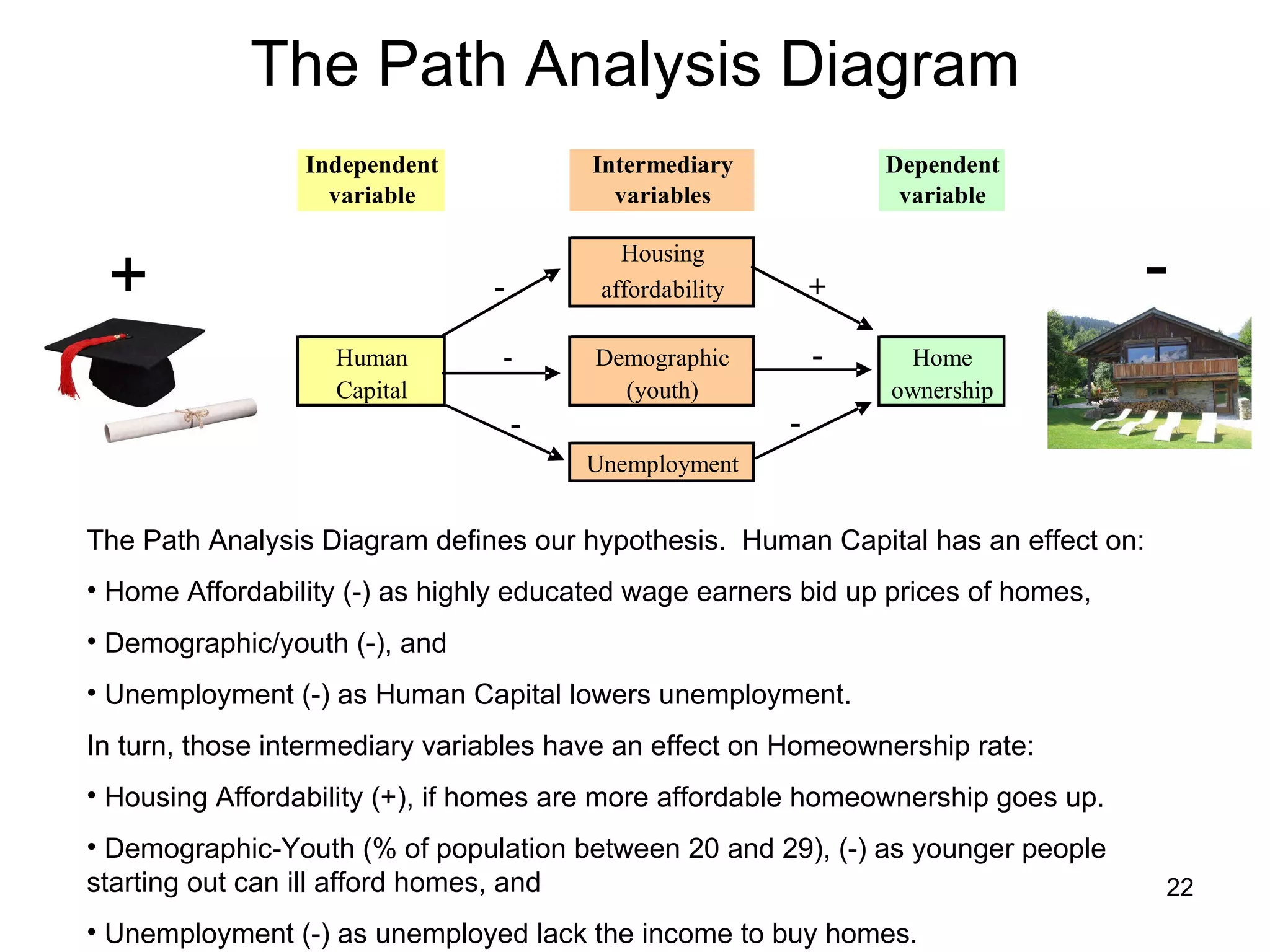
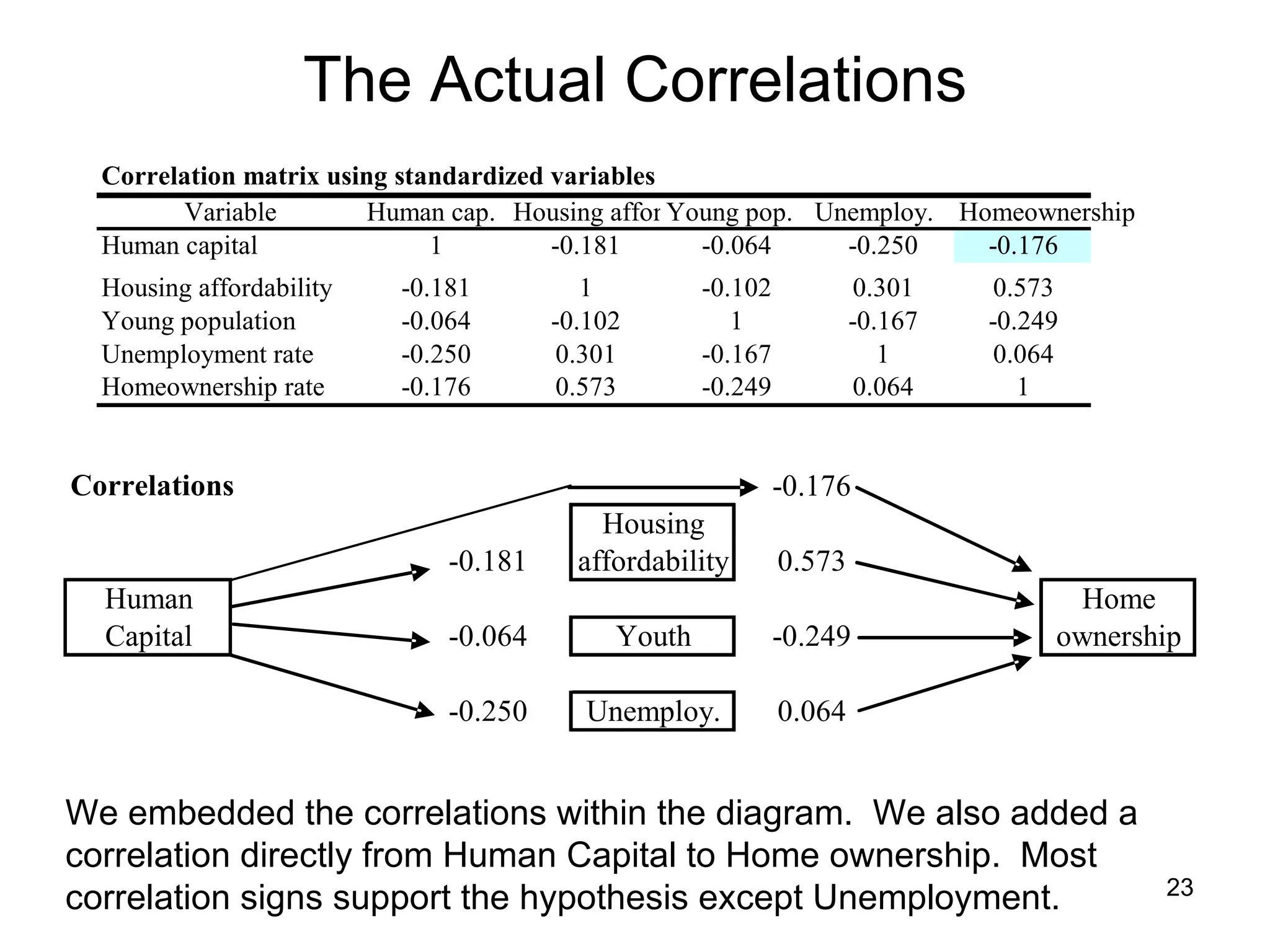


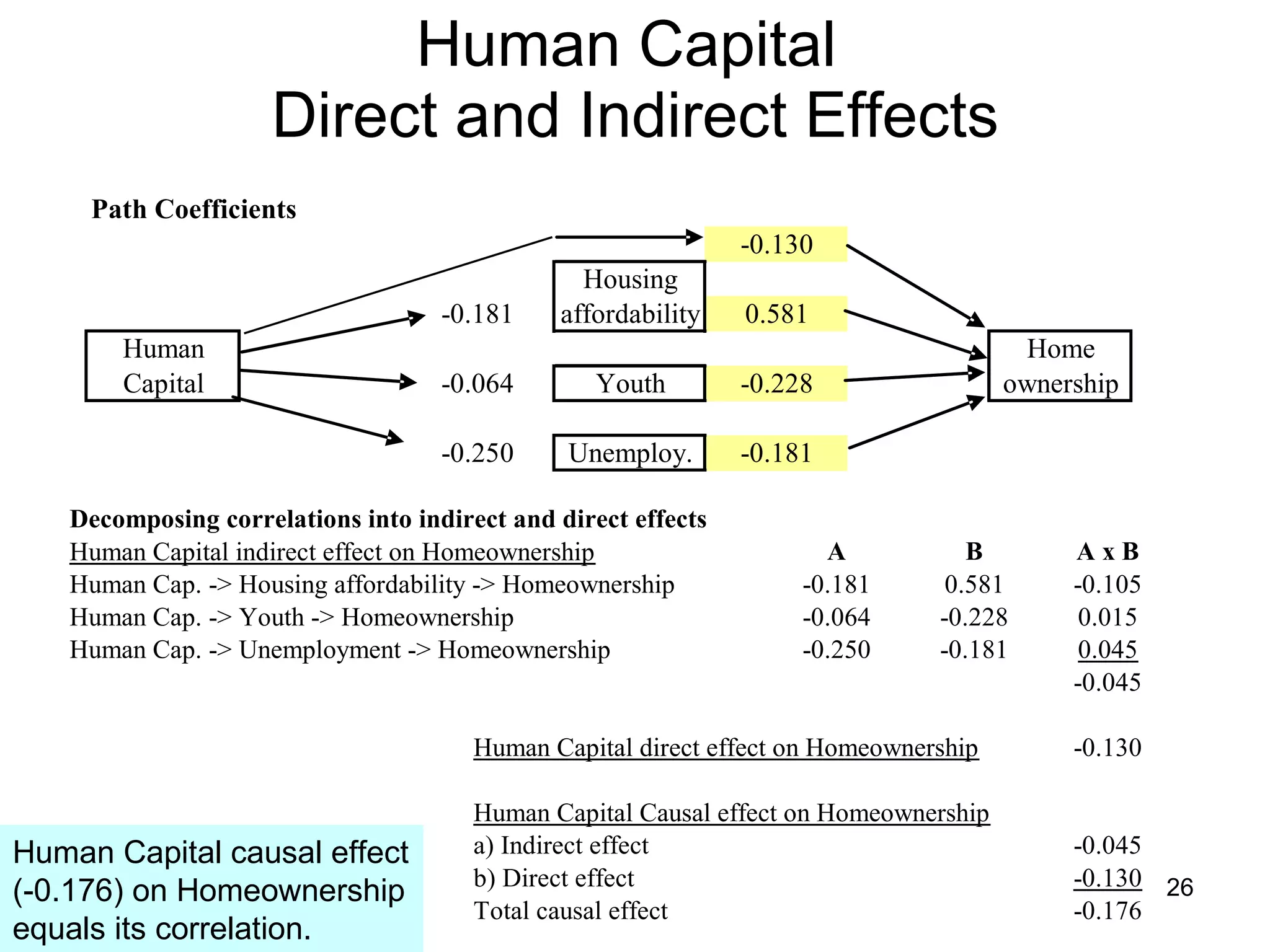
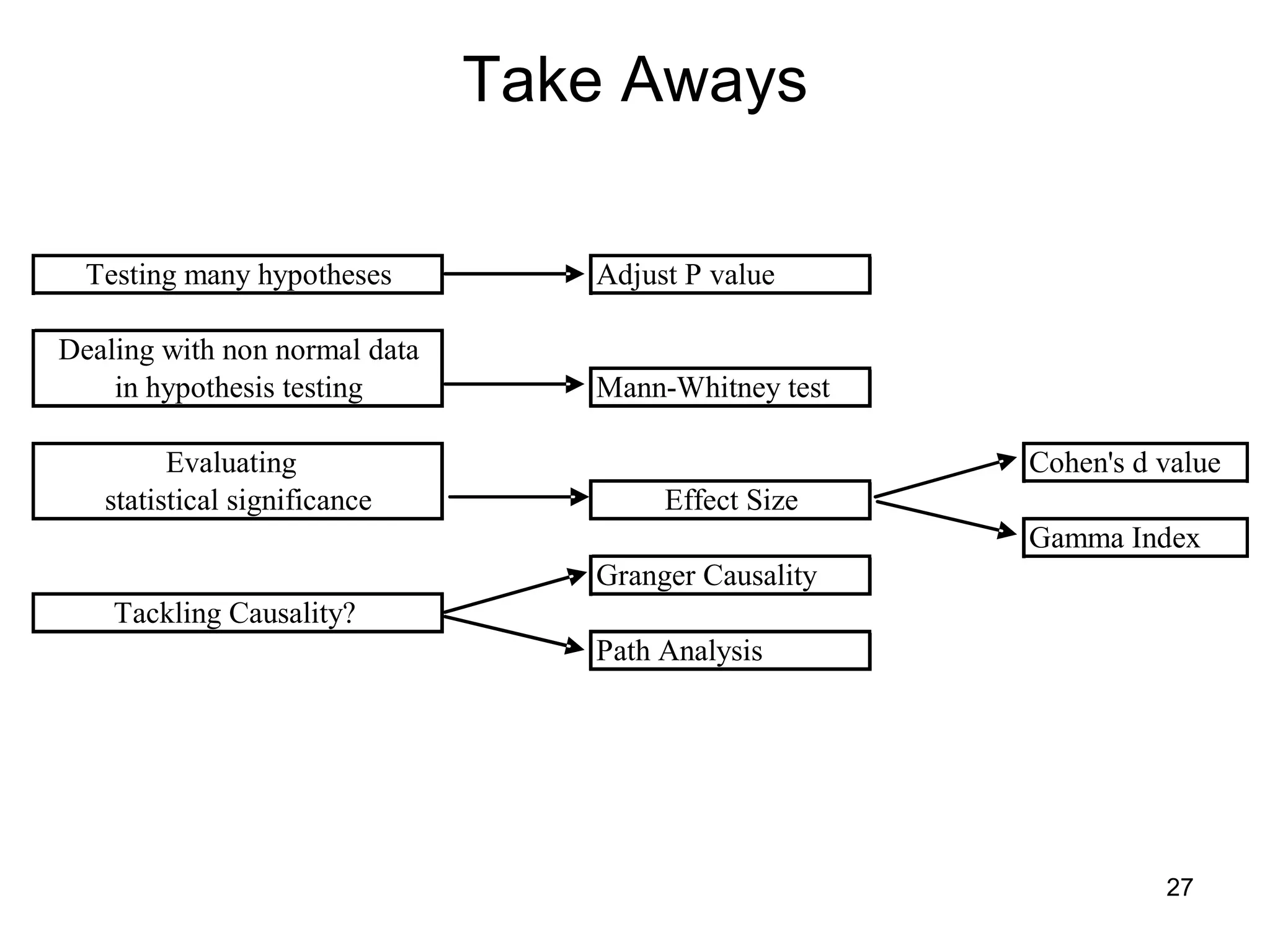

The document discusses correspondence analysis (CA) using XLSTAT, focusing on the method's ability to analyze associations between two categorical variables through PCA and various statistical calculations. It provides an example with moviegoers' opinions based on age groups, detailing steps like testing independence, calculating chi-square distances, and understanding inertia within the data. The findings indicate a dependency between age categories and opinion categories, with the 16-24 age group contributing significantly to inertia and factorization.





















































































