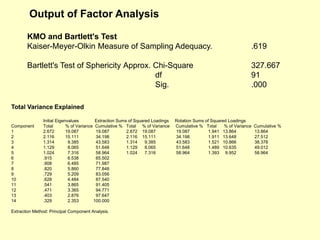
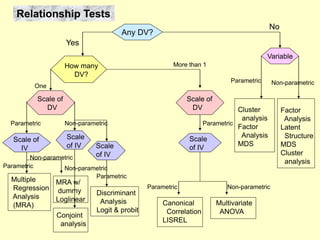
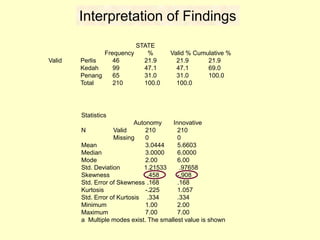
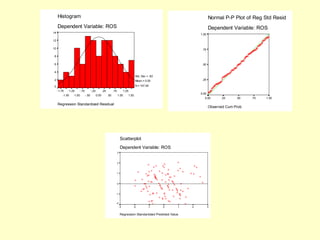
This document provides information on analyzing data using SPSS 13.0. It discusses objectives of data analysis, an overview of SPSS, data management, entry, analysis techniques including descriptive analysis, reliability analysis, factor analysis, tests of differences and relationships. Descriptive analysis is used to describe distributions. Reliability analysis and factor analysis are used to assess validity and reliability. Appropriate techniques for comparing groups and analyzing relationships depend on measurement levels and number of variables. Examples of outputs from SPSS are also included.









































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)









![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)



