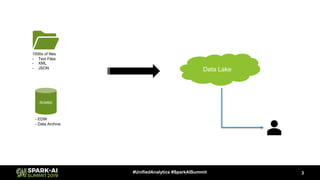
Downloaded 21 times



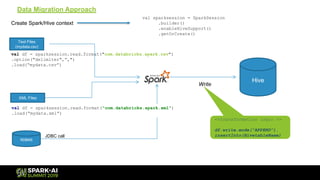

![Text Files – how to get schema?
• File header is not present in file.
• Can Infer schema, but what about column names?
• Data from last couple of years and the file format has been evolved.
scala> df.columns
res01: Array[String] = Array(_c0, _c1, _c2)
XML, JSON or RDBMS sources
• Schema present in the source.
• Spark can automatically infer schema from the source.
scala> df.columns
res02: Array[String] = Array(id, name, address)](https://image.slidesharecdn.com/062009vineetkumar-190510180448/85/Data-Migration-with-Spark-to-Hive-7-320.jpg)



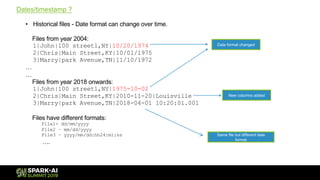
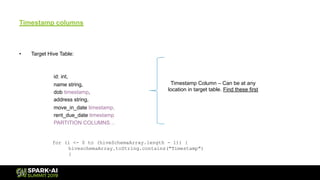









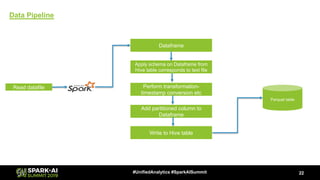


The document outlines the process and challenges of data migration to a data lake, using Spark for transformation and loading. It covers the need for standardization of data formats, handling inconsistent schemas, and the importance of timestamps in historical data. It also discusses strategies for inferring schemas from various data sources and optimizing performance during migration.














































































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)



