Downloaded 21 times















![DYNAMIC DDL – CREATE TABLE
// manually create table due to Spark bug
def createTable(sqlContext: SQLContext, columns: Seq[(String, String)],
destInfo: OutputInfo, partitionColumns: Array[(ColumnDef, Column)]): DataFrame = {
val partitionClause = if (partitionColumns.length == 0) "" else {
s"""PARTITIONED BY (${partitionColumns.map(f => s"${f._1.name} ${f._1.`type`}").mkString(", ")})"""
}
val sqlStmt =
s"""CREATE TABLE IF NOT EXISTS ${destInfo.tableName()} ( columns.map(f => s"${f._1} ${f._2}").mkString(", "))
$partitionClause
STORED AS ${destInfo.destFormat.split('.').last}
""".stripMargin
//spark 2.x doesn't know create if not exists syntax,
// still log AlreadyExistsException message. but no exception
sqlContext.sql(sqlStmt)
}](https://image.slidesharecdn.com/mlinnovationsummit2017v2-170607060841/85/Be-A-Hero-Transforming-GoPro-Analytics-Data-Pipeline-25-320.jpg)
![DYNAMIC DDL – ALTER TABLE ADD COLUMNS
//first find existing fields, then add new fields
val tableDf = sqlContext.table(dbTableName)
val exisingFields : Seq[StructField] = …
val newFields: Seq[StructField] = …
if (newFields.nonEmpty) {
// spark 2.x bug https://issues.apache.org/jira/browse/SPARK-19261
val sqlStmt: String = s"""ALTER TABLE $dbTableName ADD COLUMNS ( ${newFields.map ( f =>
s"${f.name} ${f.dataType.typeName}” ).mkString(", ")}. )"""
}](https://image.slidesharecdn.com/mlinnovationsummit2017v2-170607060841/85/Be-A-Hero-Transforming-GoPro-Analytics-Data-Pipeline-26-320.jpg)
![DYNAMIC DDL – ALTER TABLE ADD COLUMNS (SPARK 2.0)
//Hack for Spark 2.0, Spark 2.1
if (newFields.nonEmpty) {
// spark 2.x bug https://issues.apache.org/jira/browse/SPARK-19261
alterTable(sqlContext, dbTableName, newFields)
}
def alterTable(sqlContext: SQLContext,
tableName: String,
newColumns: Seq[StructField]): Unit = {
alterTable(sqlContext, getTableIdentifier(tableName), newColumns)
}
private[spark] class HiveExternalCatalog(conf: SparkConf, hadoopConf: Configuration)
extends ExternalCatalog with Logging {
….
}](https://image.slidesharecdn.com/mlinnovationsummit2017v2-170607060841/85/Be-A-Hero-Transforming-GoPro-Analytics-Data-Pipeline-27-320.jpg)

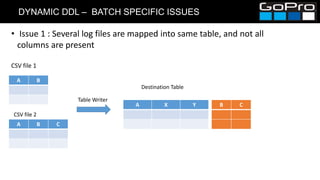
![DYNAMIC DDL – BATCH SPECIFIC ISSUES
• Solution:
• Find DataFrame with max number of columns, use it as base, and reorder
columns against this DataFrame
val newDfs : Option[ParSeq[DataFrame]] = maxLengthDF.map{ baseDf =>
dfs.map { df =>
df.select(baseDf.schema.fieldNames.map(f => if (df.columns.contains(f)) col(f) else
lit(null).as(f)): _*)
}
}](https://image.slidesharecdn.com/mlinnovationsummit2017v2-170607060841/85/Be-A-Hero-Transforming-GoPro-Analytics-Data-Pipeline-30-320.jpg)
![DYNAMIC DDL – BATCH SPECIFIC ISSUES
• Issue2 : Too many log files -- performance
• Solution: We consolidate several data log files Data Frame into chunks, each
chunk with all Data Frames union together.
val ys: Seq[Seq[DataFrame]] = destTableDFs.seq.grouped(mergeChunkSize).toSeq
val dfs: ParSeq[DataFrame] = ys.par.map(p => p.foldLeft(emptyDF) { (z, a) => z.unionAll(a) })
dfs.foreach(saveDataFrame(info, _))](https://image.slidesharecdn.com/mlinnovationsummit2017v2-170607060841/85/Be-A-Hero-Transforming-GoPro-Analytics-Data-Pipeline-31-320.jpg)




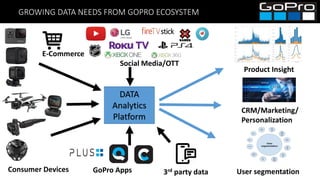
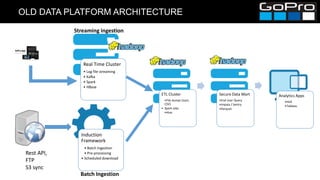
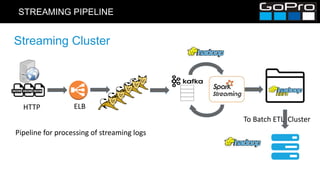
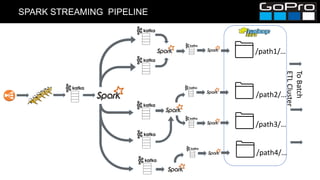
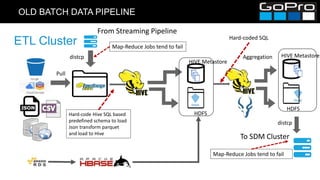
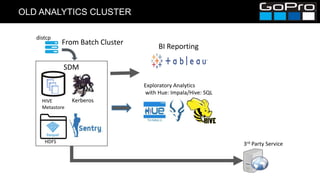
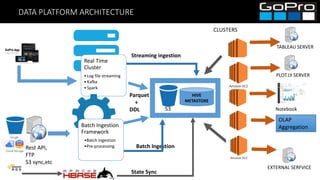
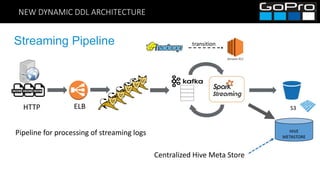
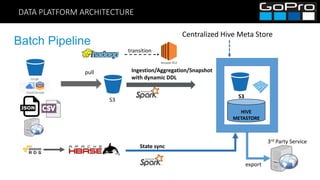
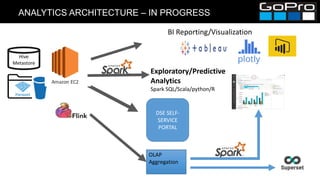
The document discusses GoPro's transition to a new data platform architecture. The old architecture had several clusters for different workloads which caused operational overhead and lack of elasticity. The new architecture separates storage and computing, uses S3 for storage and ephemeral instances as compute clusters. It also introduces a centralized Hive metastore and uses dynamic DDL to flexibly ingest and aggregate both batch and streaming data while allowing the schema to change on the fly. This improves cost, scalability and enables more advanced analytics capabilities.























































































