Downloaded 61 times













![Meta Data Object Model
ADLA Account/Catalog
Database
Schema
[1,n]
[1,n]
[0,n]
tables views TVFs
C# Fns C# UDAgg
Clustered
Index
partitions
C#
Assemblies
C# Extractors
Data
Source
C# Reducers
C# Processors
C# Combiners
C# Outputters
Ext. tables
User
objects
Refers toContains Implemented
and named by
Procedures
Creden-
tials
MD
Name
C# Name
C# Applier
Table Types
Legend
Statistics
C# UDTs
Packages](https://image.slidesharecdn.com/usqlintrosqlsaturday-170901003646/85/Introduction-to-Azure-Data-Lake-and-U-SQL-for-SQL-users-SQL-Saturday-635-20-320.jpg)
![• Naming
• Discovery
• Sharing
• Securing
U-SQL Catalog Naming
• Default Database and Schema context: master.dbo
• Quote identifiers with []: [my table]
• Stores data in ADL Storage /catalog folder
Discovery
• Visual Studio Server Explorer
• Azure Data Lake Analytics Portal
• SDKs and Azure Powershell commands
Sharing
• Within an Azure Data Lake Analytics account
• Across ADLA accounts that share same Azure Active Directory:
• Referencing Assemblies
• Calling TVFs and referencing tables and views
• Inserting into Tables
Securing
• Secured with AAD principals at catalog and Database level](https://image.slidesharecdn.com/usqlintrosqlsaturday-170901003646/85/Introduction-to-Azure-Data-Lake-and-U-SQL-for-SQL-users-SQL-Saturday-635-21-320.jpg)
![• Views for simple cases
• TVFs for parameterization and
most cases
VIEWs and TVFs Views
CREATE VIEW V AS EXTRACT…
CREATE VIEW V AS SELECT …
• Cannot contain user-defined objects (e.g. UDF or UDOs)!
• Will be inlined
Table-Valued Functions (TVFs)
CREATE FUNCTION F (@arg string = "default")
RETURNS @res [TABLE ( … )]
AS BEGIN … @res = … END;
• Provides parameterization
• One or more results
• Can contain multiple statements
• Can contain user-code (needs assembly reference)
• Will always be inlined
• Infers schema or checks against specified return schema](https://image.slidesharecdn.com/usqlintrosqlsaturday-170901003646/85/Introduction-to-Azure-Data-Lake-and-U-SQL-for-SQL-users-SQL-Saturday-635-22-320.jpg)






![U-SQL
Analytics
Windowing Expression
Window_Function_Call 'OVER' '('
[ Over_Partition_By_Clause ]
[ Order_By_Clause ]
[ Row _Clause ]
')'.
Window_Function_Call :=
Aggregate_Function_Call
| Analytic_Function_Call
| Ranking_Function_Call.
Windowing Aggregate Functions
ANY_VALUE, AVG, COUNT, MAX, MIN, SUM, STDEV, STDEVP, VAR, VARP
Analytics Functions
CUME_DIST, FIRST_VALUE, LAST_VALUE, PERCENTILE_CONT,
PERCENTILE_DISC, PERCENT_RANK, LEAD, LAG
Ranking Functions
DENSE_RANK, NTILE, RANK, ROW_NUMBER](https://image.slidesharecdn.com/usqlintrosqlsaturday-170901003646/85/Introduction-to-Azure-Data-Lake-and-U-SQL-for-SQL-users-SQL-Saturday-635-29-320.jpg)






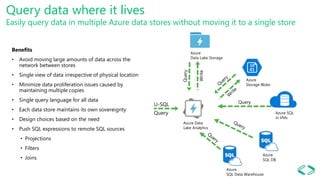
The document introduces Azure Data Lake and U-SQL for SQL users, emphasizing its ability to manage and analyze both structured and unstructured data efficiently via a unified query language. U-SQL combines the declarative nature of SQL with the extensibility of C#, enabling users to run custom code within a scalable framework. It outlines various features, including advanced analytics extensions, data extraction and output operations, and integration with multiple Azure data sources.











































































