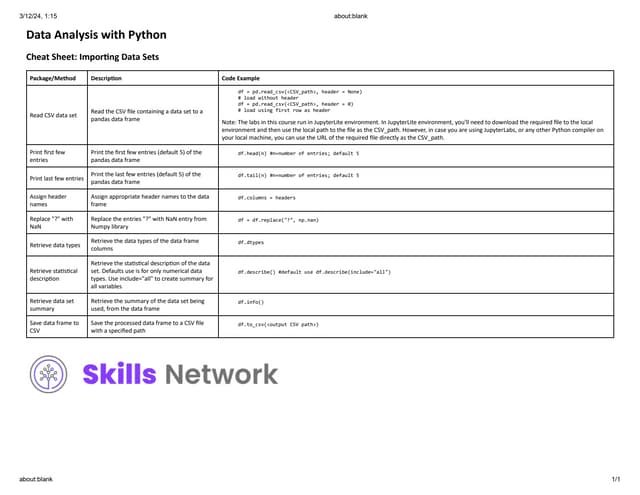
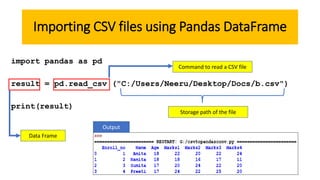
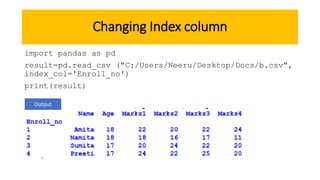
This document discusses importing and interfacing CSV files with Python Pandas DataFrames. It explains that Pandas DataFrames allow for querying and calculations on tabular data, and CSV files are commonly used to store scientific data with columns separated by commas. It then demonstrates how to import CSV files into DataFrames using Pandas read_csv function, specifying options like the file path, column separator, and header row. It also shows how to export DataFrames to CSV files using the to_csv method.







![Using the Name parameter
We can specify our own column names using the parameter names while creating
the DataFrame using the read_csv() function.
import pandas as pd
result=pd.read_csv ("C:/Users/Neeru/Desktop/Docs/b.csv", header=0,
names=["Roll_no","Studname", "Math","English","Science", "Arts"])
print(result)
Note: We need to specify the
Header=0 parameter here otherwise,
there will be a double heading.
Output](https://image.slidesharecdn.com/cbsepythoncsvconnectivity-200521154010/85/Python-and-CSV-Connectivity-9-320.jpg)

![Applying Pandas Aggregate Functions
import pandas as pd
result=pd.read_csv ("C:/Users/Neeru/Desktop/Docs/b.csv")
print(result.sum())
print(result.sum(axis=1))
print(result['Marks1'].sum())
print(result[‘Marks1’])](https://image.slidesharecdn.com/cbsepythoncsvconnectivity-200521154010/85/Python-and-CSV-Connectivity-12-320.jpg)
![print(result.mean())
print(result.loc[2])
print(result.loc[1:4])
Applying Pandas Aggregate Functions](https://image.slidesharecdn.com/cbsepythoncsvconnectivity-200521154010/85/Python-and-CSV-Connectivity-13-320.jpg)
![Adding a new column
import pandas as pd
result=pd.read_csv ("C:/Users/Neeru/Desktop/Docs/b.csv")
result["Marks6"]=[22,11,13,15]
print(result)
Output](https://image.slidesharecdn.com/cbsepythoncsvconnectivity-200521154010/85/Python-and-CSV-Connectivity-14-320.jpg)
![Adding a new row
import pandas as pd
result=pd.read_csv ("C:/Users/Neeru/Desktop/Docs/b.csv")
result.loc[4]=[22,24,25,20.20]
print(result)
Output](https://image.slidesharecdn.com/cbsepythoncsvconnectivity-200521154010/85/Python-and-CSV-Connectivity-15-320.jpg)
![Exporting DataFrames to CSV
import pandas as pd
marksUT= {'Name':['Raman','Zuhaire','Mishti','Drovya'],
'UT':[1,2,3,4],
'Maths':[22,21,14,20],
'Science':[25,22,21,18],
'S.St':[18,17,15,22],
'Hindi':[20,22,15,17],
'Eng':[24,23,13,20]
}
pd1=pd.DataFrame(marksUT)
pd1.to_csv(path_or_buf='C:/Users/Neeru/Desktop/Docs/dd.csv’,
sep=',')
DataFrame
Creation
File PathCommand to write to a CSV file](https://image.slidesharecdn.com/cbsepythoncsvconnectivity-200521154010/85/Python-and-CSV-Connectivity-16-320.jpg)