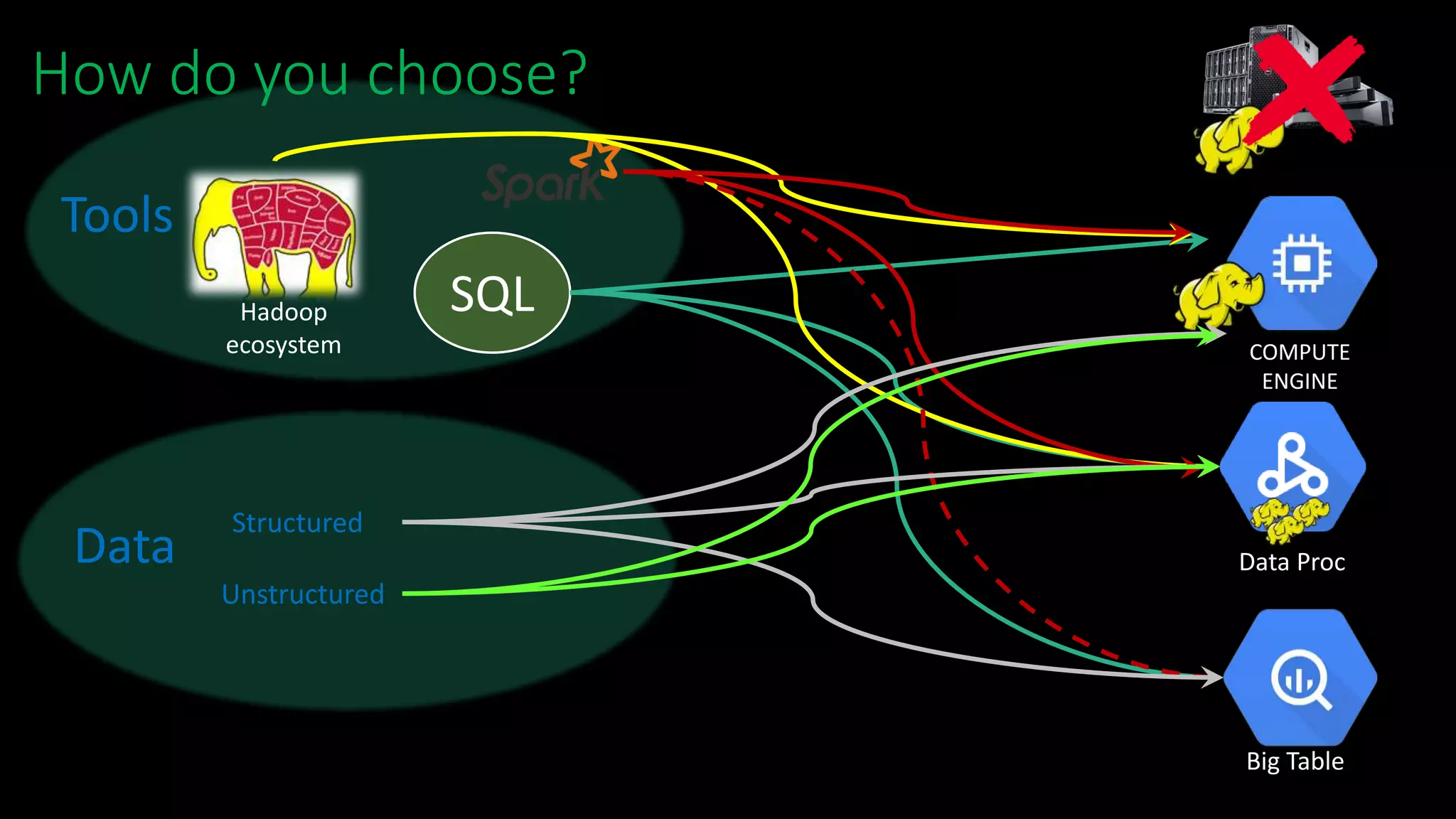
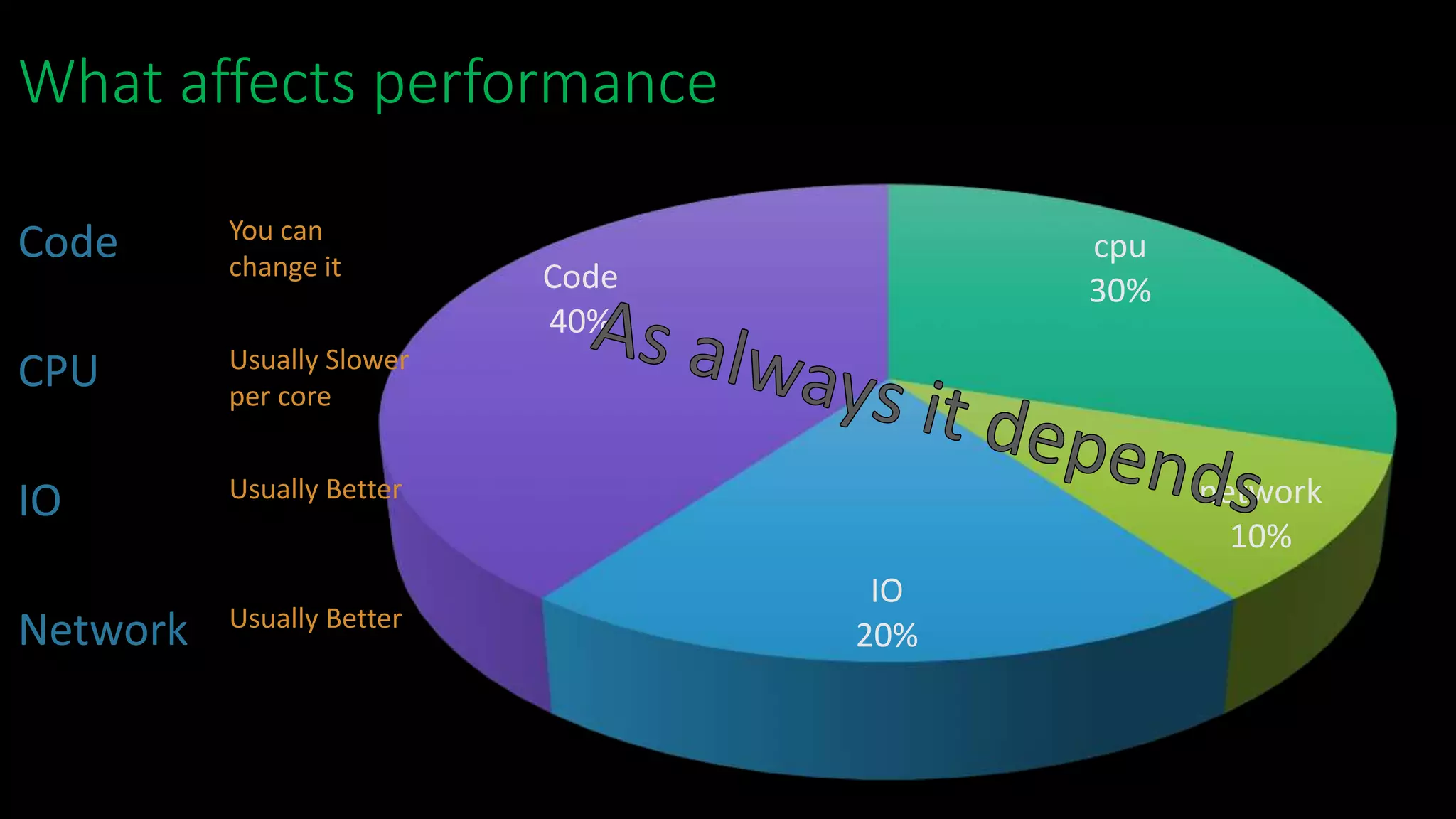
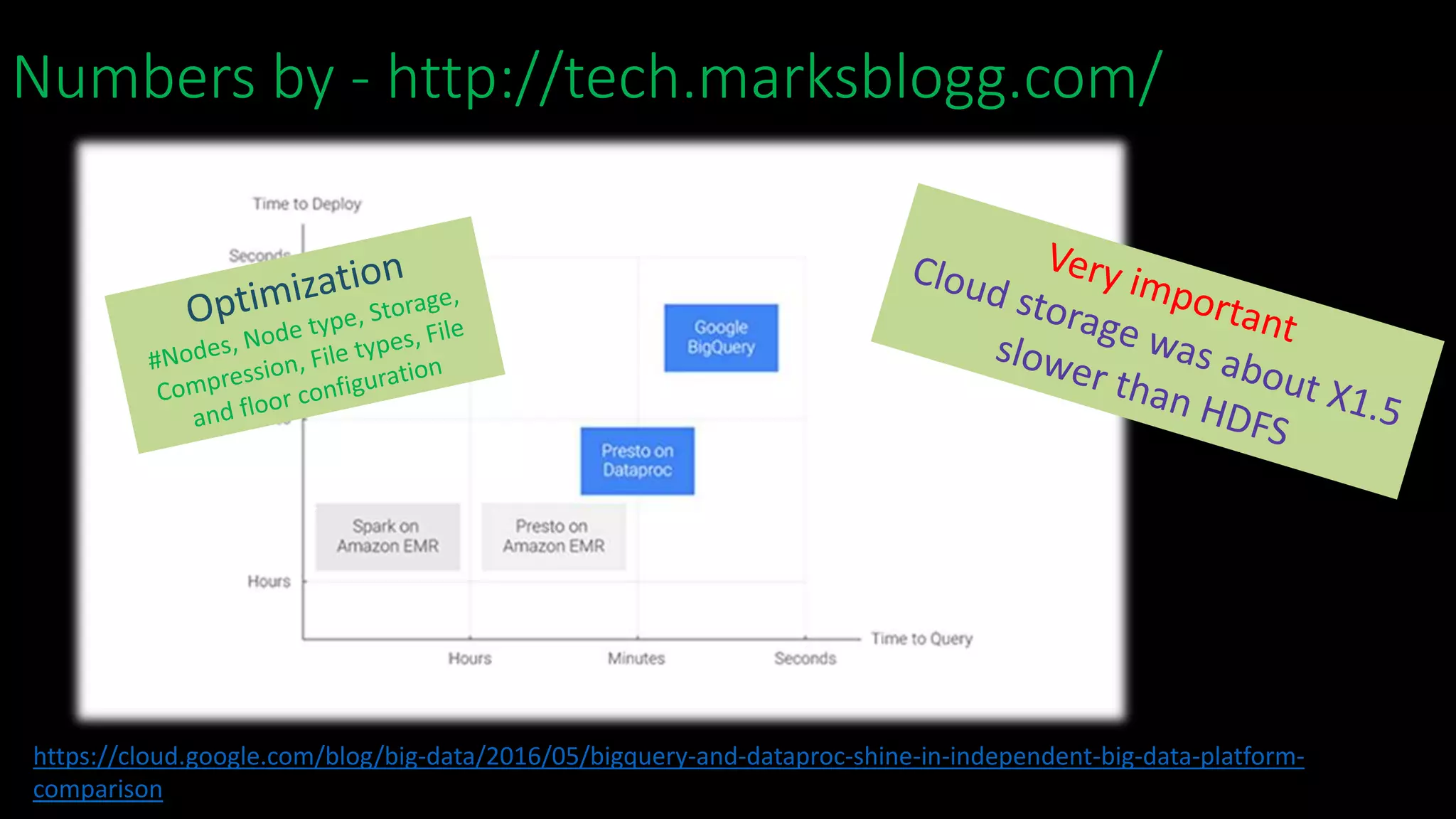
The document discusses Ido Friedman and his background working with various data technologies. It then discusses the concept of a data lake and how it serves as a single store for raw and transformed data used for reporting, analytics, and machine learning. The rest of the document discusses how traditional tools like SQL have changed with the rise of Hadoop and cloud storage. It provides examples of performance and cost differences between running data workloads on Hadoop clusters versus cloud-based data processing services like BigQuery and Dataproc. The document concludes that a large data lake is now possible in the cloud and discusses various deployment options to consider.

![IdoFriedman.yml
Name: Ido Friedman,
Past:[Data platform consultant, Instructor, Team Leader]
Present: [Data engineer, Architect]
Technologies:
[Elasticsearch,CouchBase,MongoDB,Python,Hadoop,SQL
and more …]
WorkPlace: Perion
WhenNotWorking: @Sea](https://image.slidesharecdn.com/datalake-161108084109/75/Data-lake-On-Premise-VS-Cloud-2-2048.jpg)