

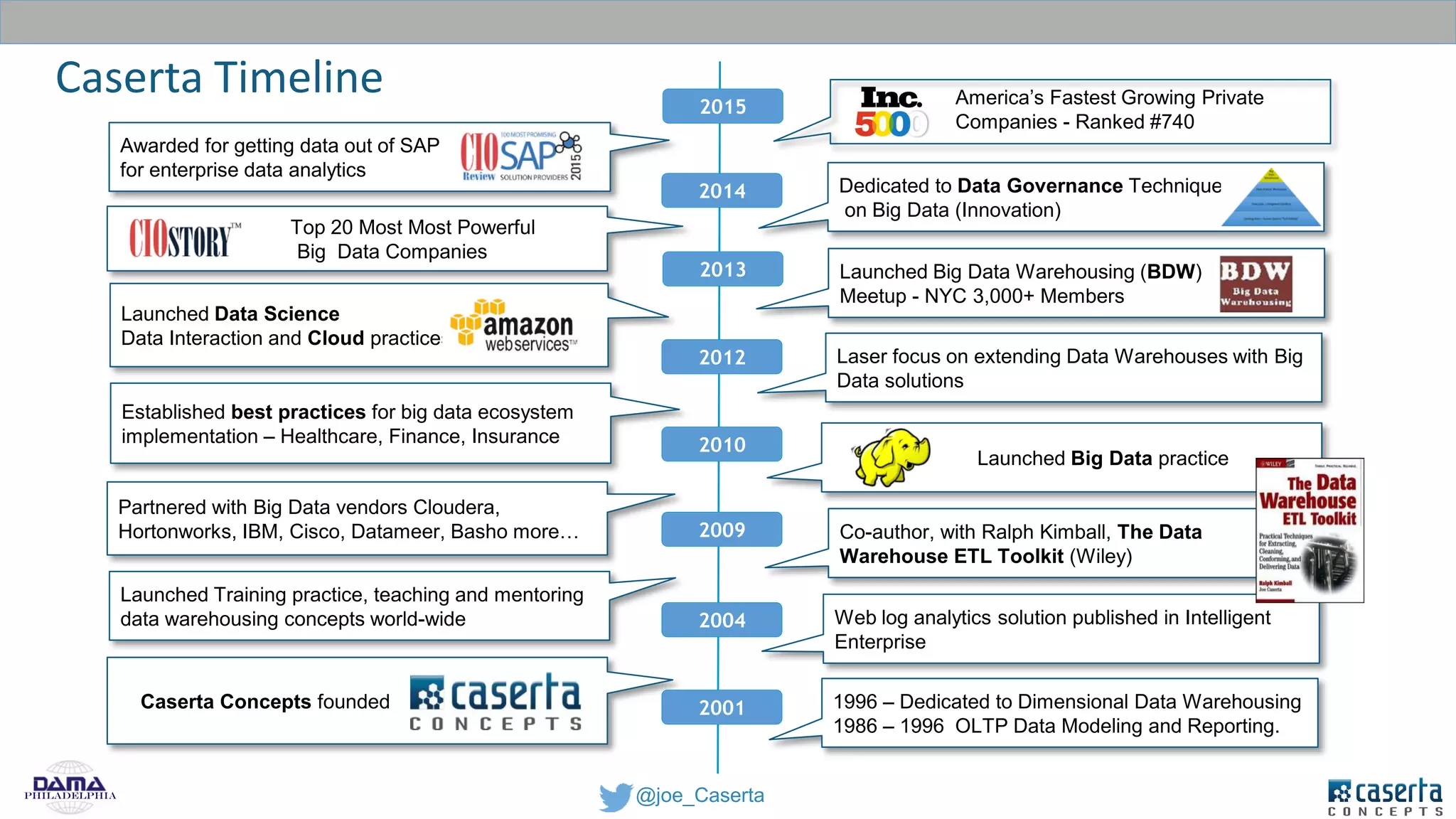





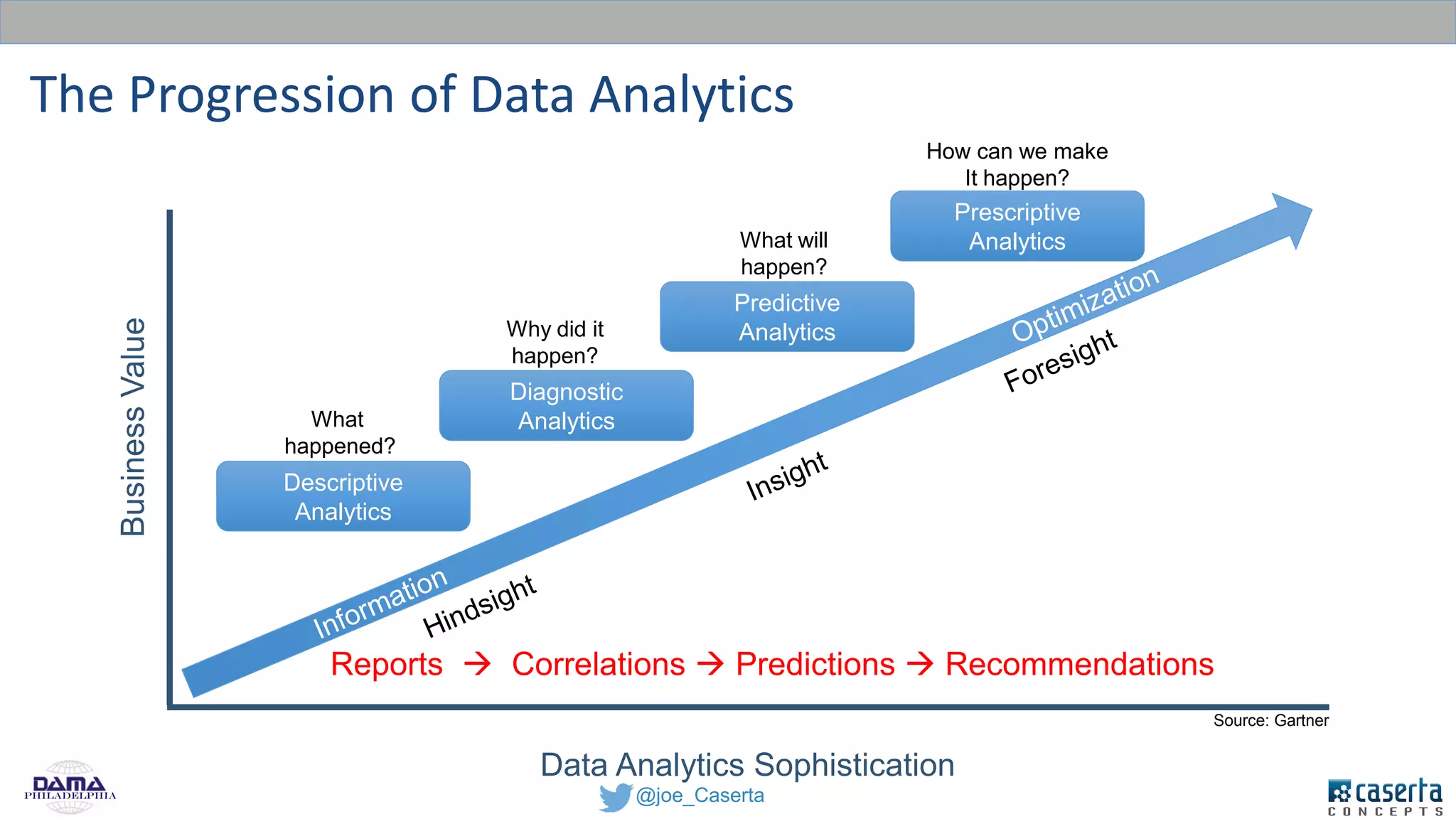
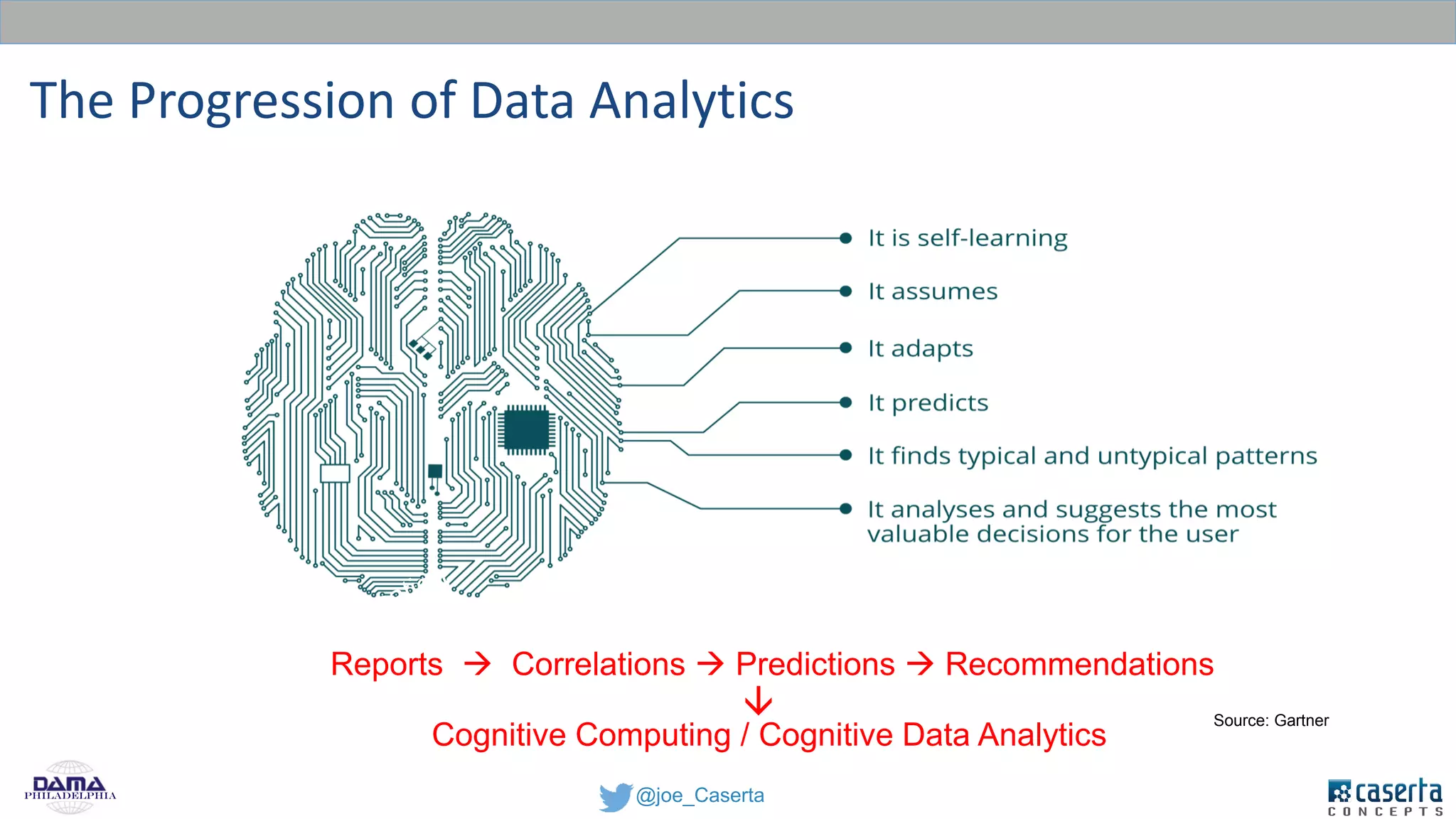



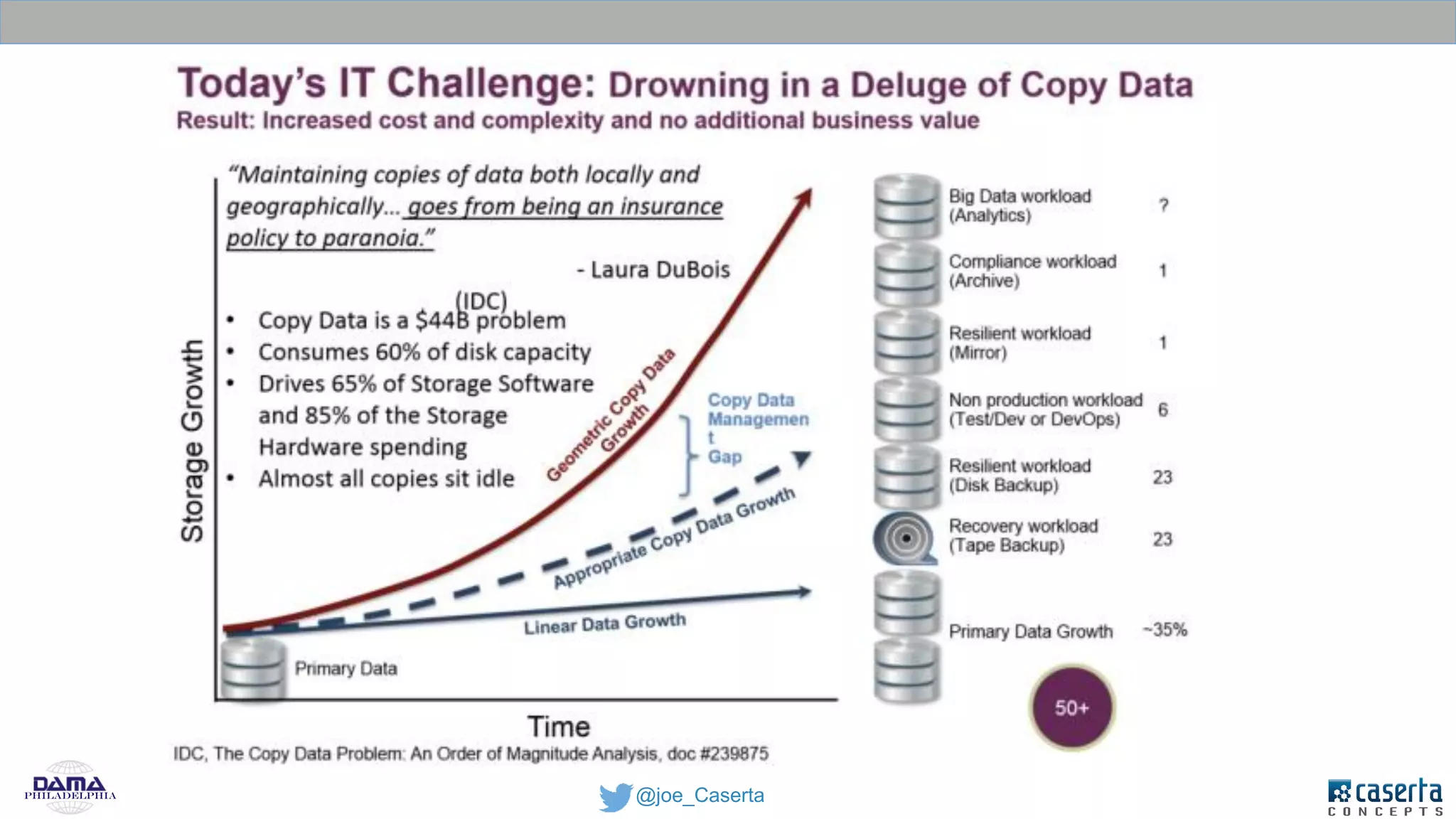














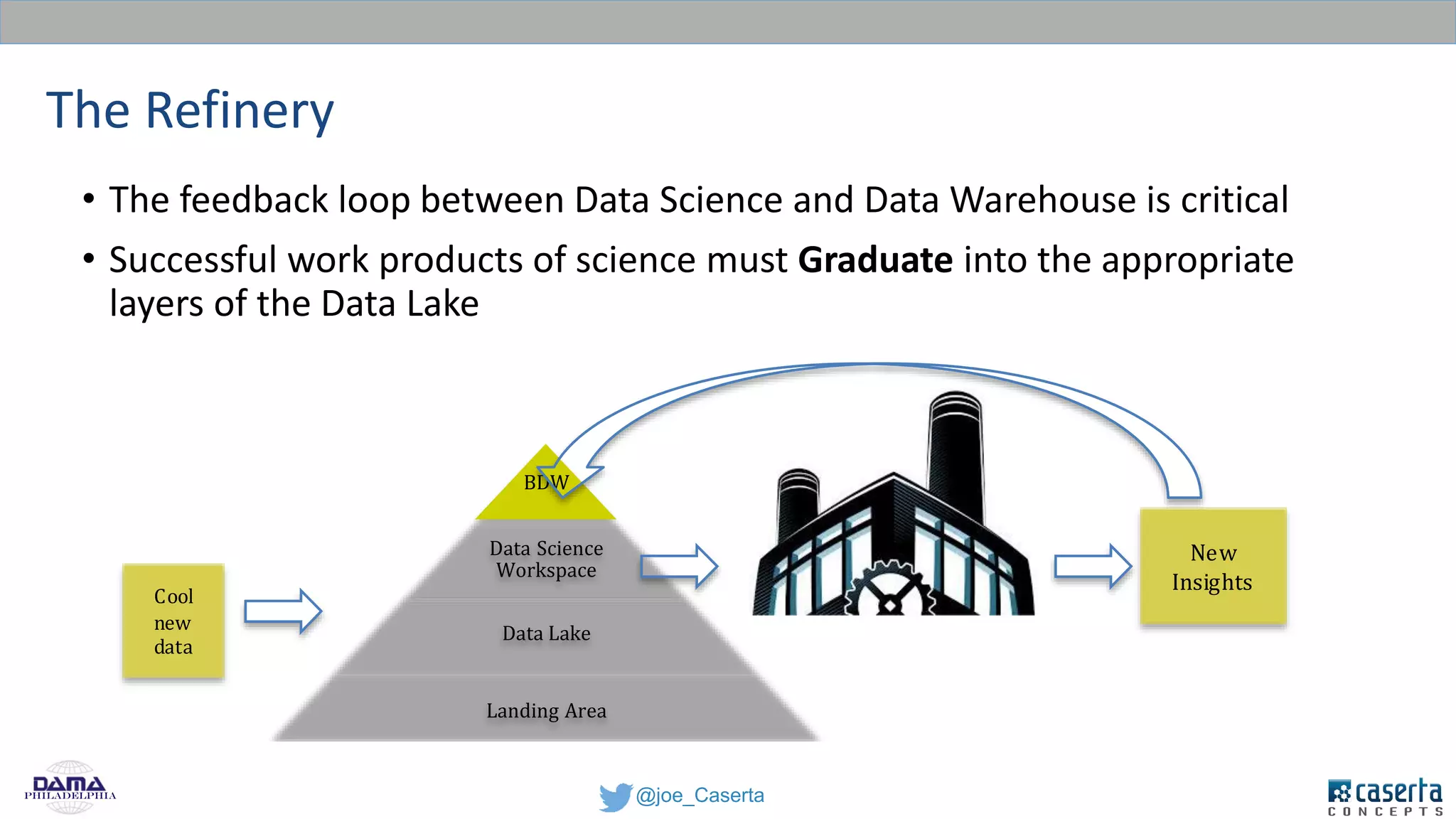




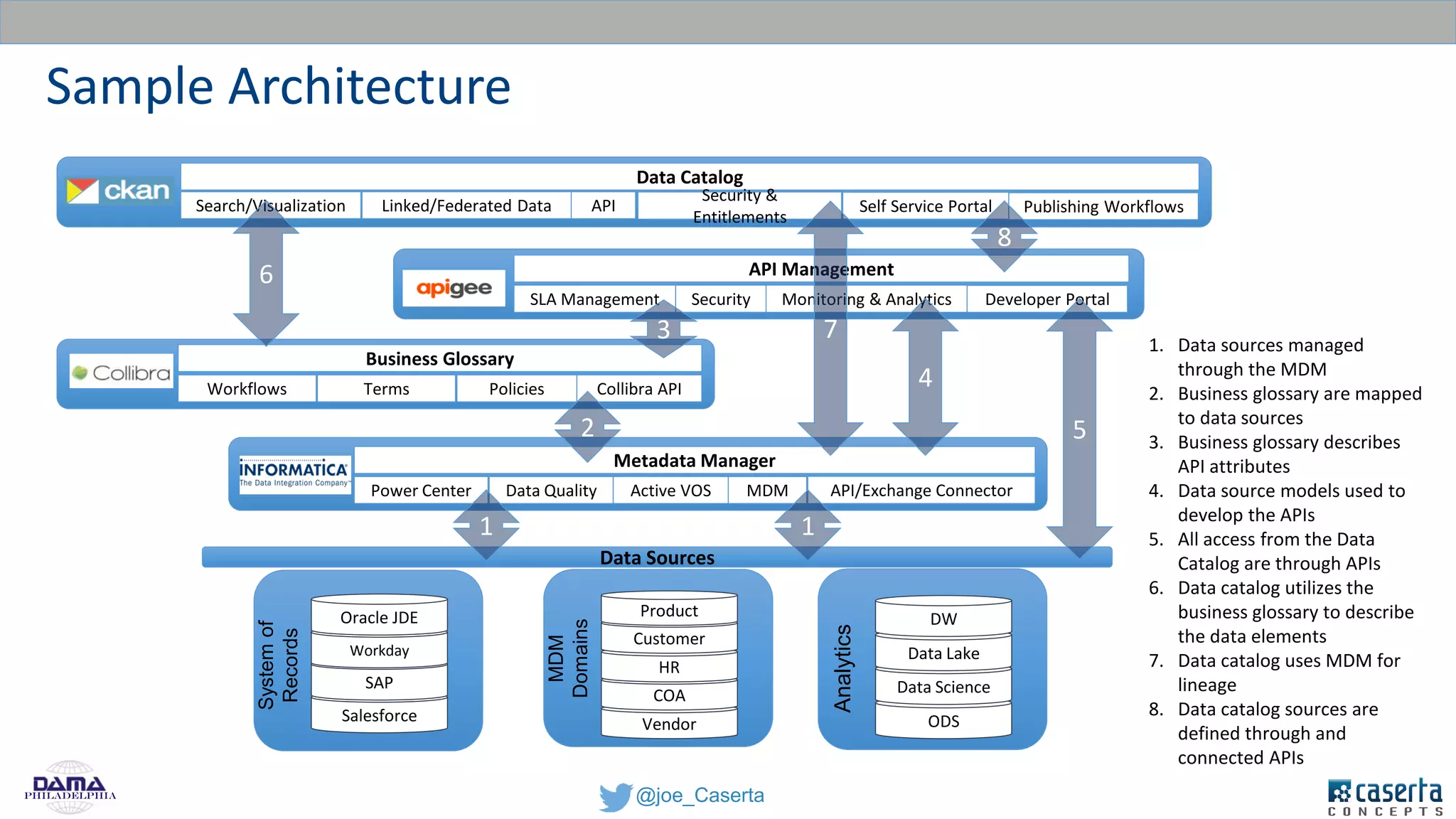



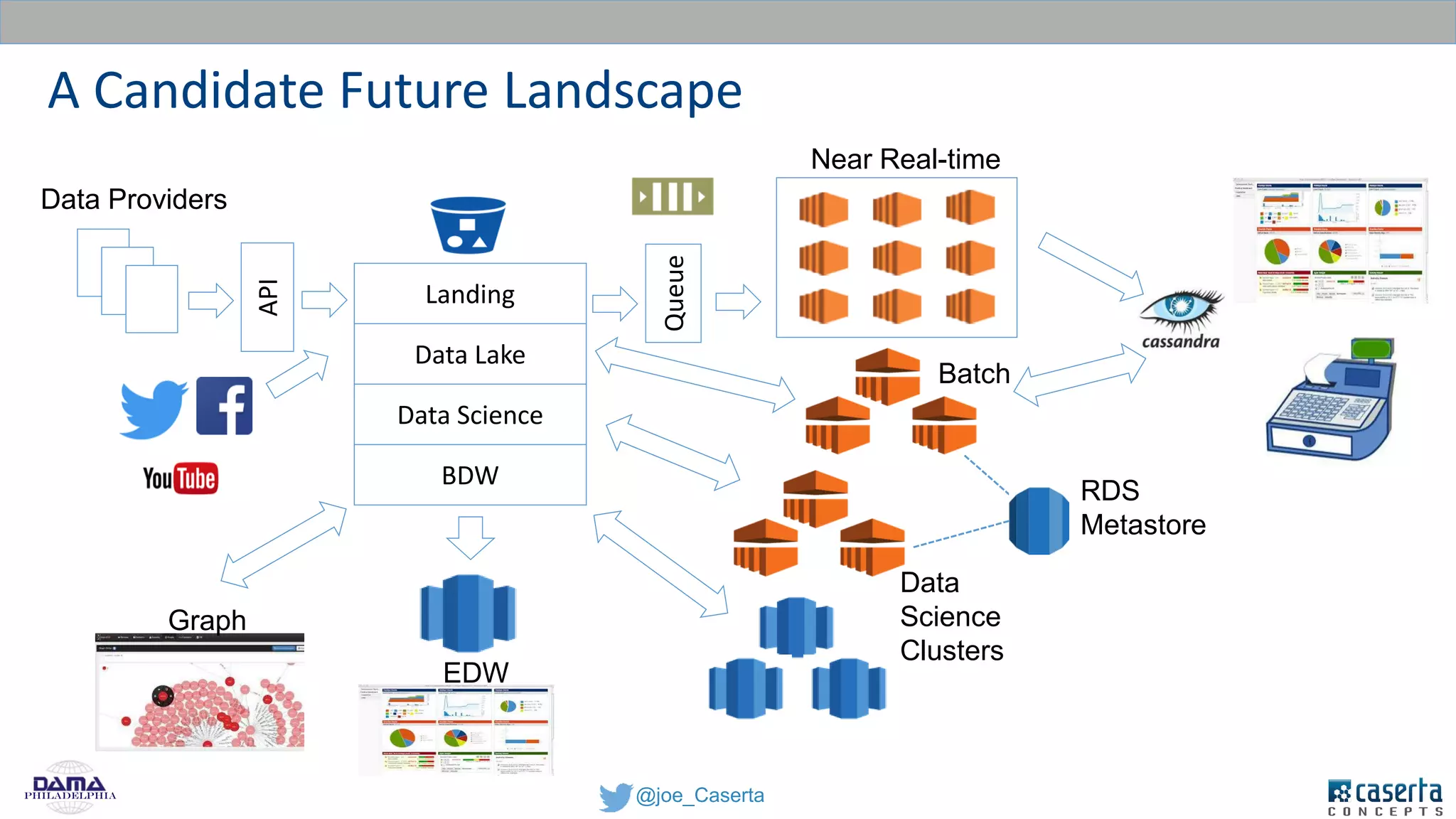


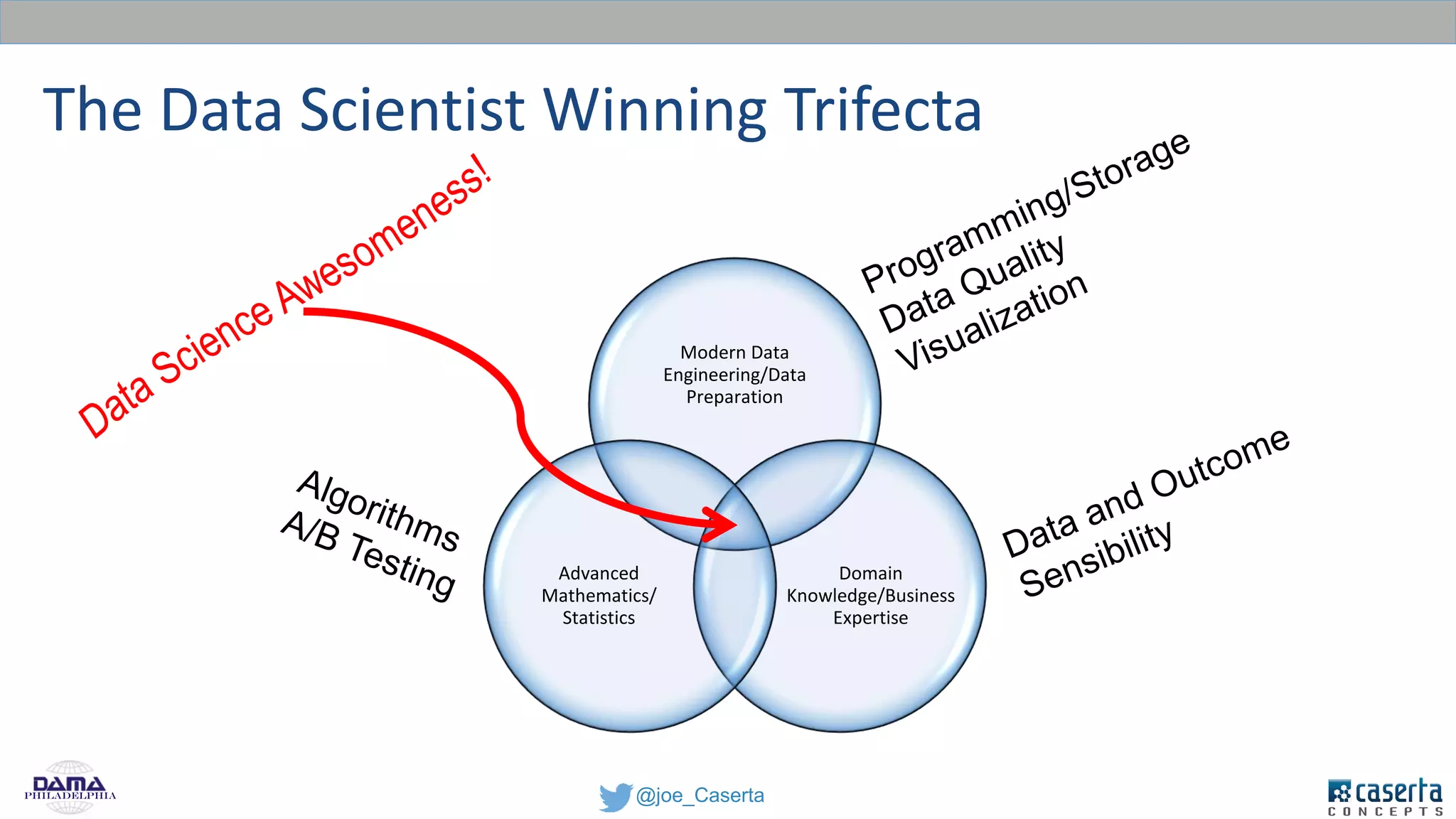

Caserta Concepts, founded by Joe Caserta, is a consulting firm specializing in data innovation and modern data engineering, providing solutions for complex business data challenges. The company has launched several initiatives, including a big data practice and training programs, and is recognized for its work in data governance, analytics, and cloud solutions. With a focus on evolving data analytics and governance techniques, Caserta Concepts aims to address issues such as data sprawl and improve data integration across various sectors.
















































































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)


