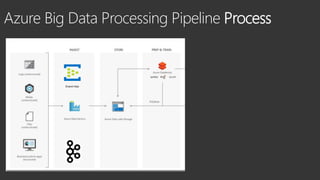
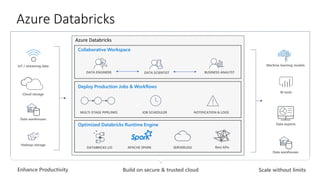
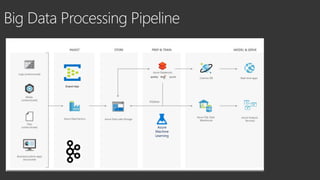
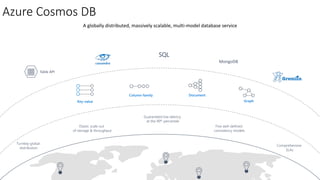
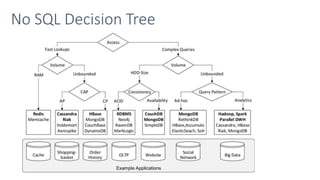
The document discusses different types of big data including unstructured, semi-structured, and structured data. It provides examples of each type such as audio, video, and images for unstructured data. JSON, XML, and sensor data are given as examples for semi-structured data. The document also discusses the challenges of processing big data due to its variety, velocity, and volume.


















































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

