Downloaded 474 times



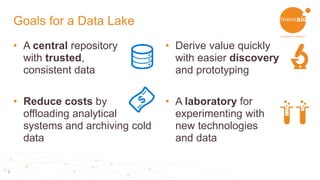
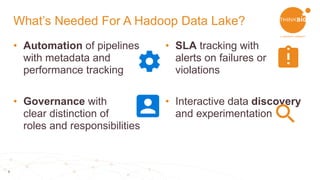



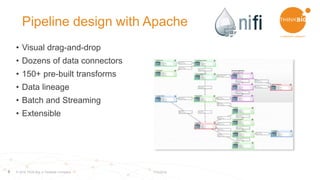
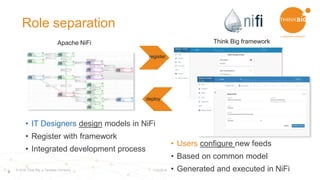
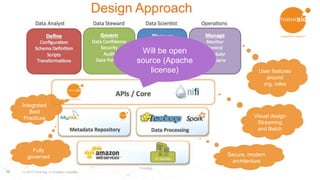




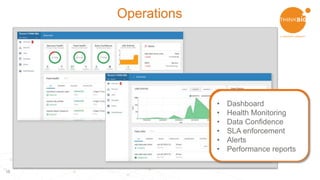




This document discusses using Apache Spark and Apache NiFi together for data lakes. It outlines the goals of a data lake including having a central data repository, reducing costs, enabling easier discovery and prototyping. It also discusses what is needed for a Hadoop data lake, including automation of pipelines, governance, and interactive data discovery. The document then provides an example ingestion project and describes using Apache Spark for functions like cleansing, validating, and profiling data. It outlines using Apache NiFi for the pipeline design with drag and drop functionality. Finally, it demonstrates ingesting and preparing data, data self-service and transformation, data discovery, and operational monitoring capabilities.

















![[오픈소스컨설팅] 쿠버네티스와 쿠버네티스 on 오픈스택 비교 및 구축 방법](https://cdn.slidesharecdn.com/ss_thumbnails/osck8svsk8sonopenstackkhoj-210310051504-thumbnail.jpg?width=640&height=640&fit=bounds)

























































































