







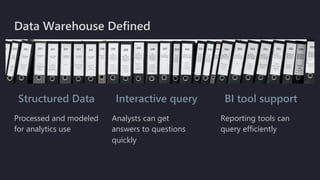





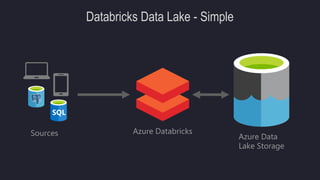
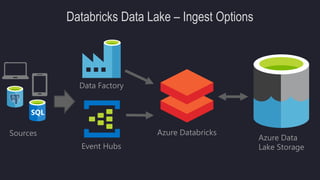


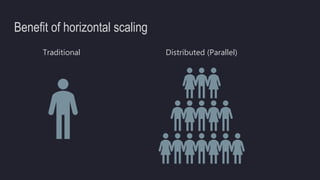

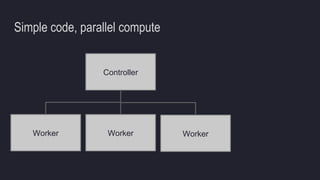





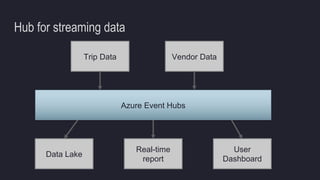

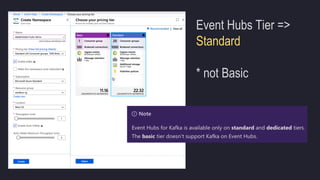



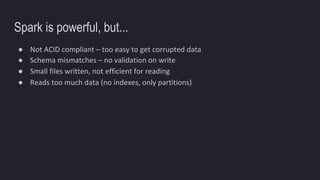




The document outlines the essentials of building data lakes using Azure Databricks, emphasizing the importance of big data storage and analytics. It discusses data lake structures, querying capabilities, and the benefits of using Apache Spark for scalable data processing. Additionally, it highlights best practices for data storage and management, including the use of Delta Lake for improved performance and compliance.













![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)









































































