Download as PDF, PPTX



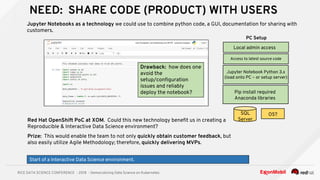

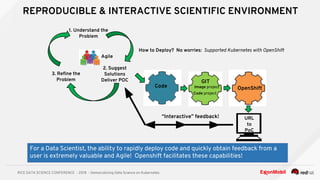



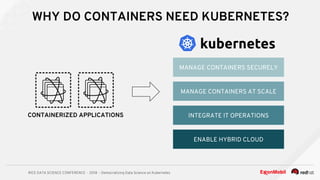
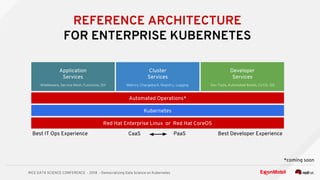



The document discusses the democratization of data science through the use of Kubernetes and OpenShift, highlighting the challenges faced by data analytics teams such as resource congestion. It introduces the use of Jupyter notebooks as a tool for creating reproducible and interactive data science environments, facilitating rapid code deployment and user feedback. It emphasizes the importance of modern containerized applications and the role of Kubernetes in managing these applications efficiently across various cloud environments.






















![[Webinar] Getting to Insights Faster: A Framework for Agile Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/agile-big-datav2-131122164332-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


















































