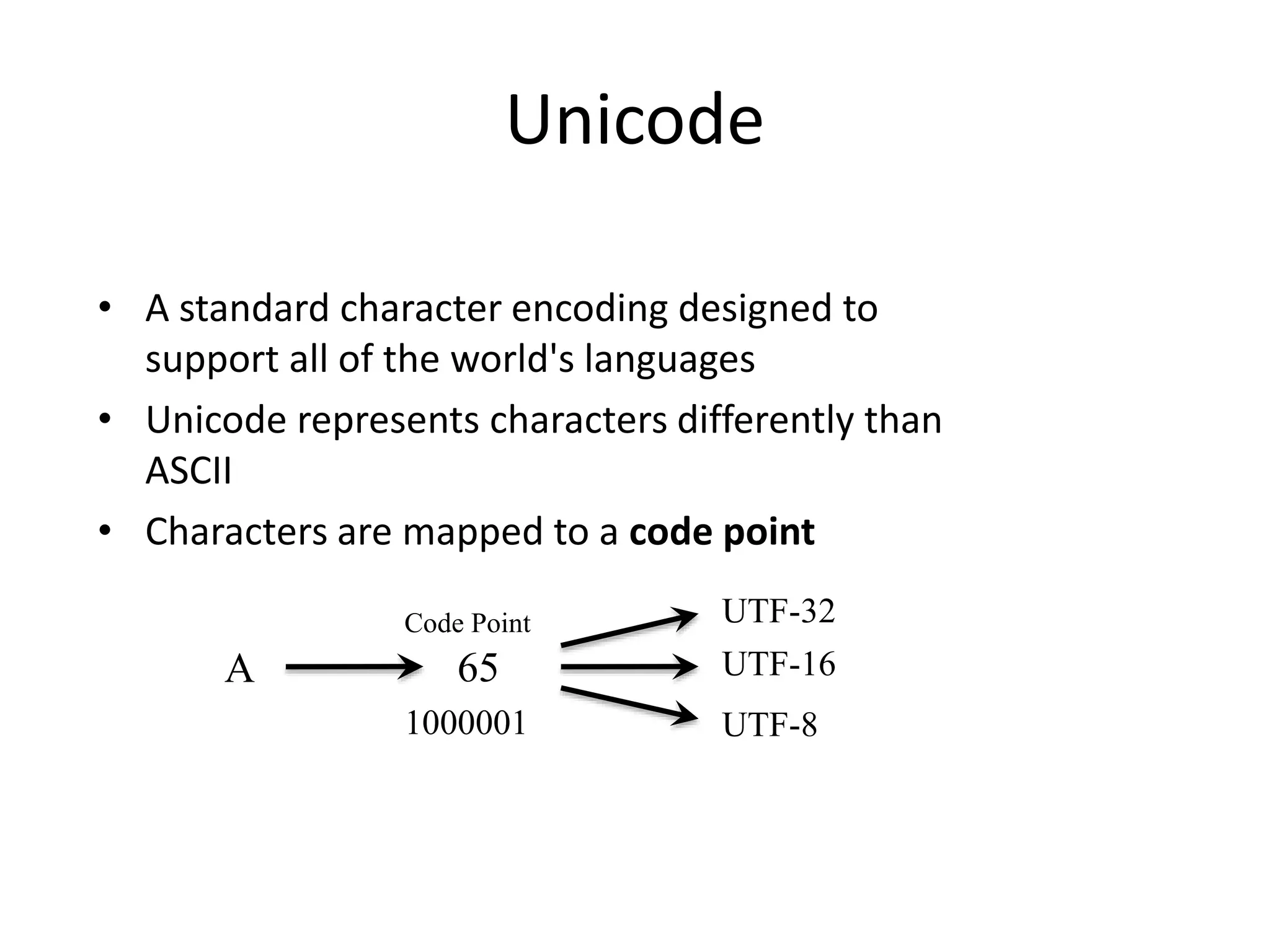
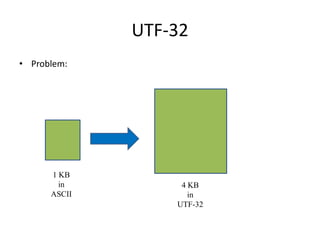
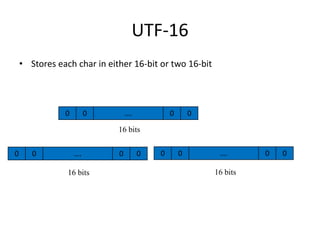
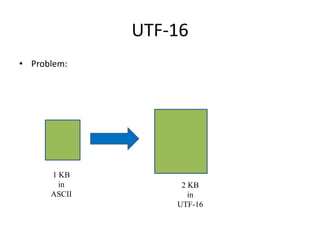
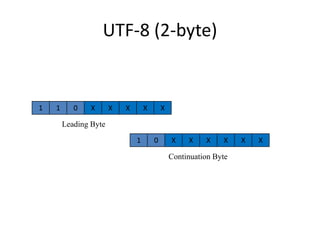
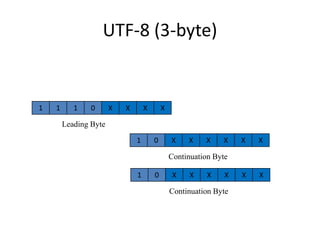
Unicode is a standard for representing characters that supports all languages. It maps each character to a unique code point and can represent characters using UTF-8, UTF-16, or UTF-32 encodings. UTF-8 uses a variable number of bytes (1-4) to encode each code point, allowing for compact representation and support of a wide range of languages.
























![C08 wireless atm[1]](https://cdn.slidesharecdn.com/ss_thumbnails/c08-wirelessatm1-130417050629-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)













































































