


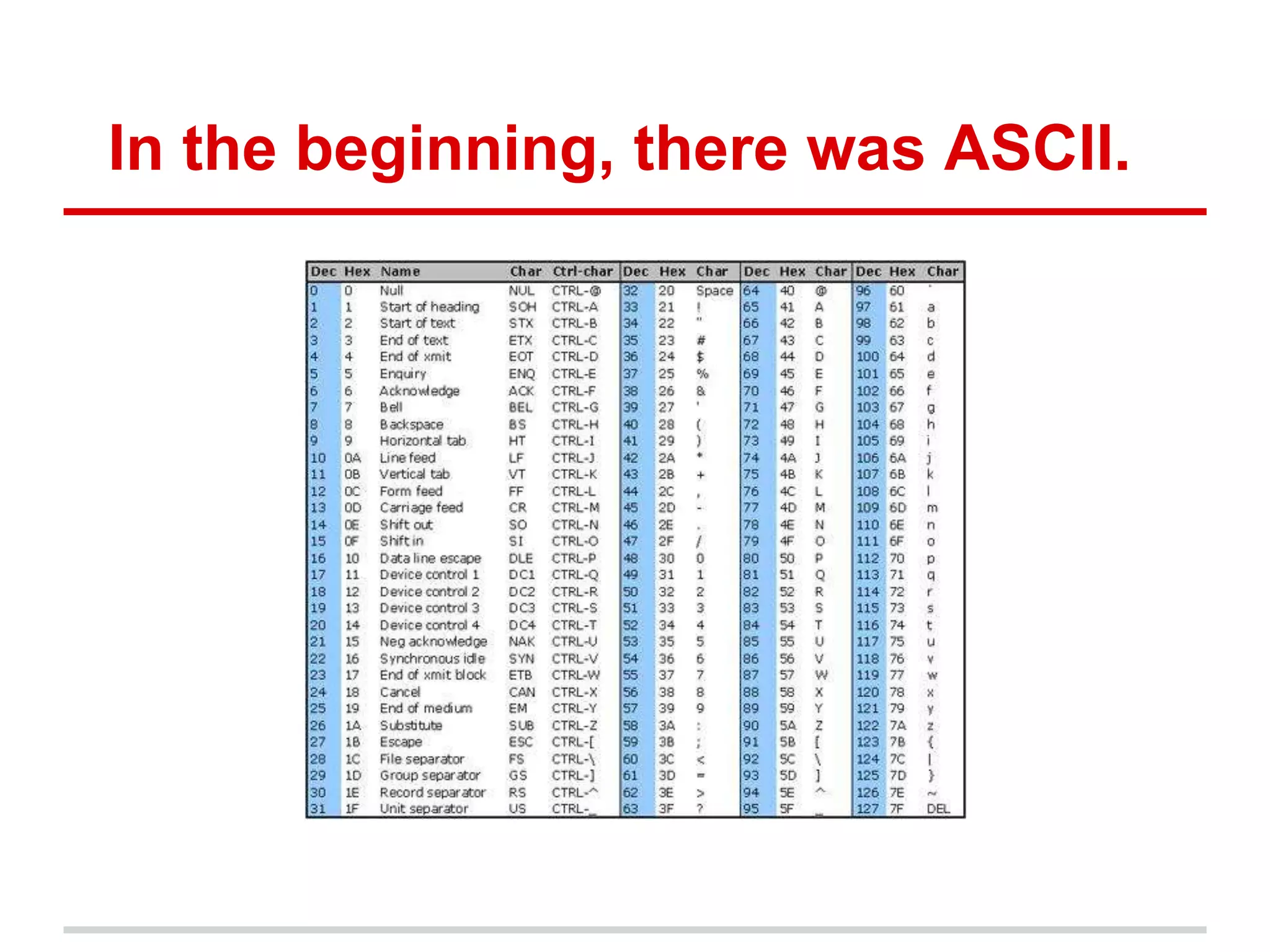
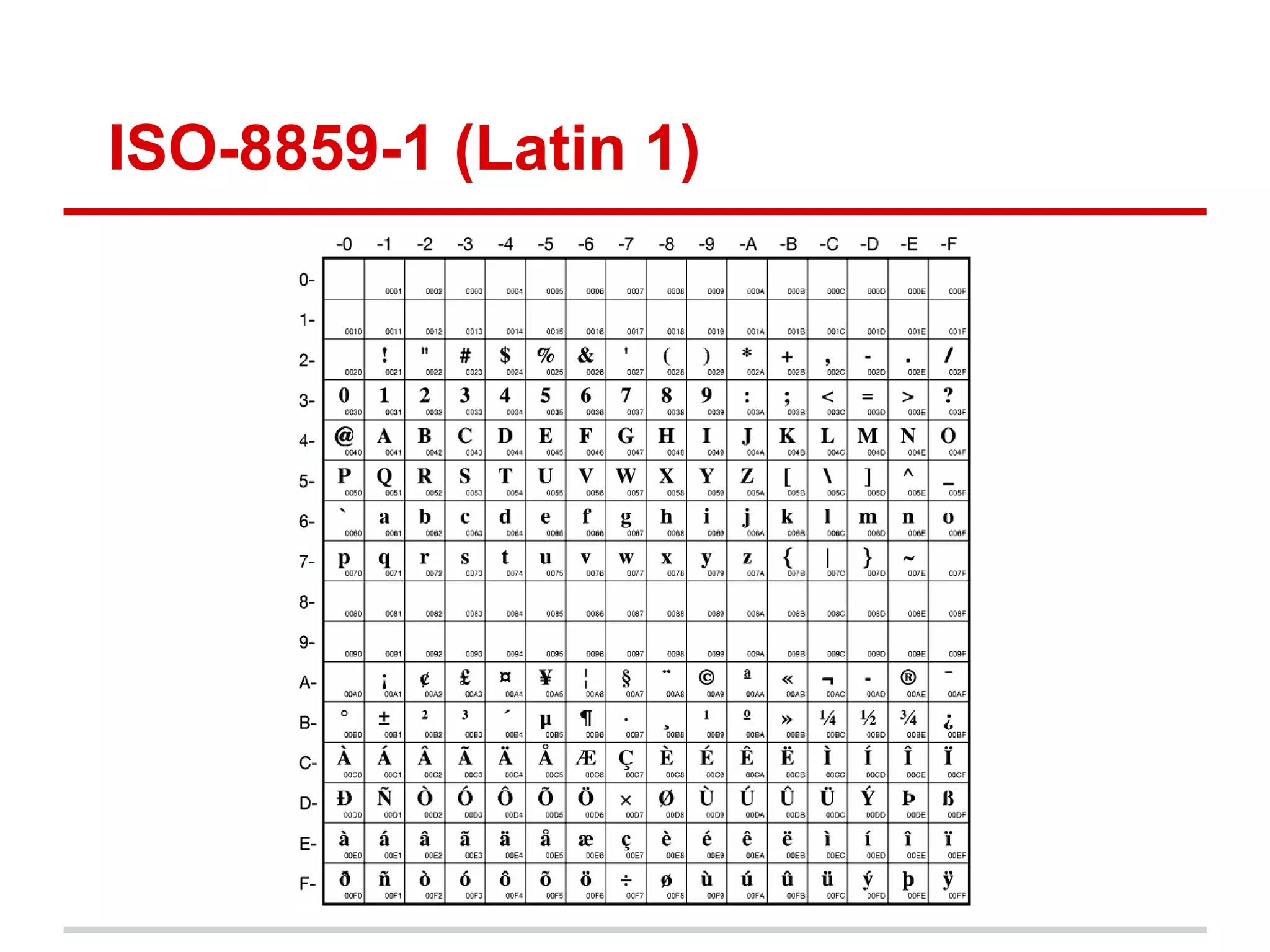




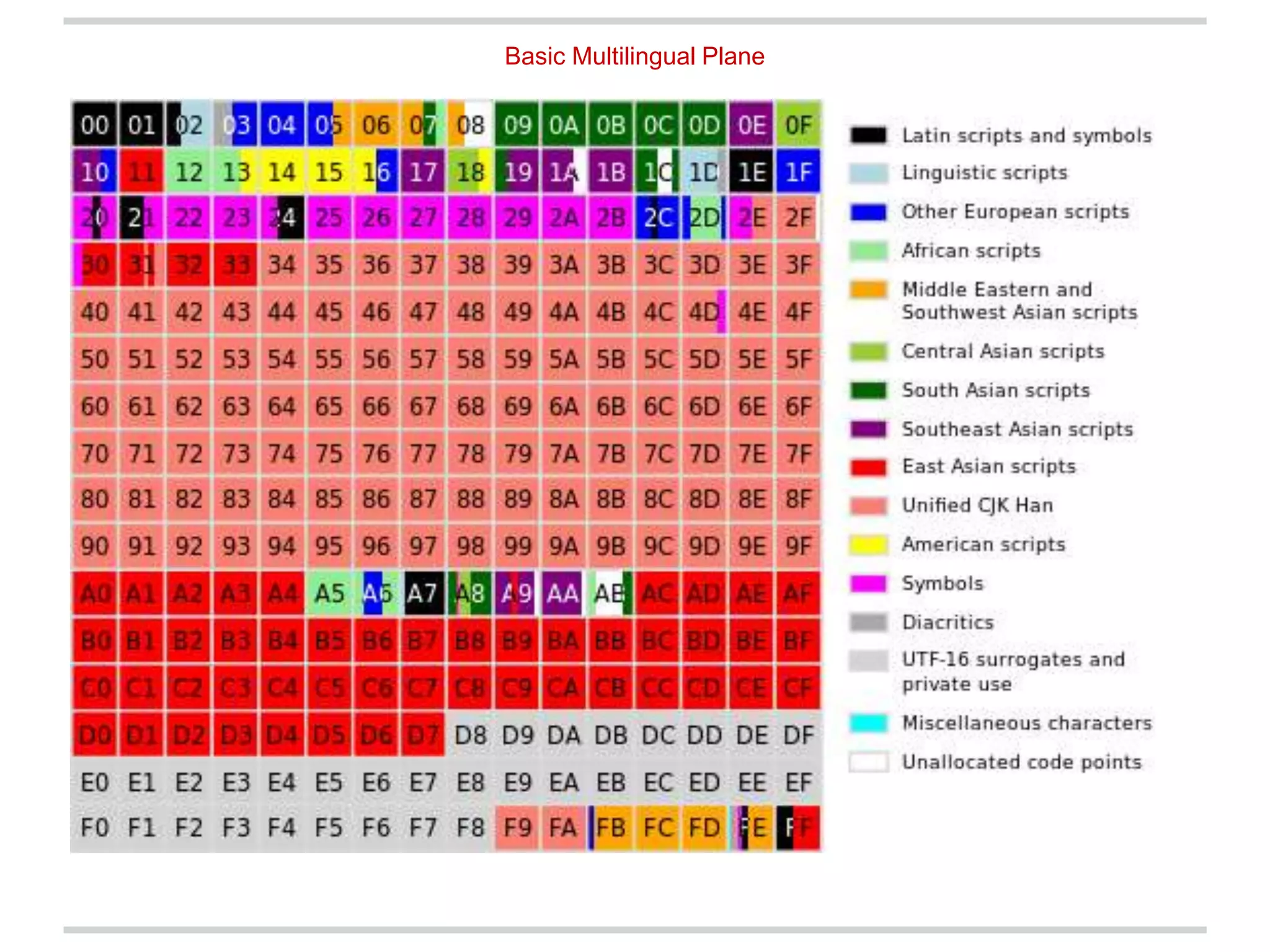
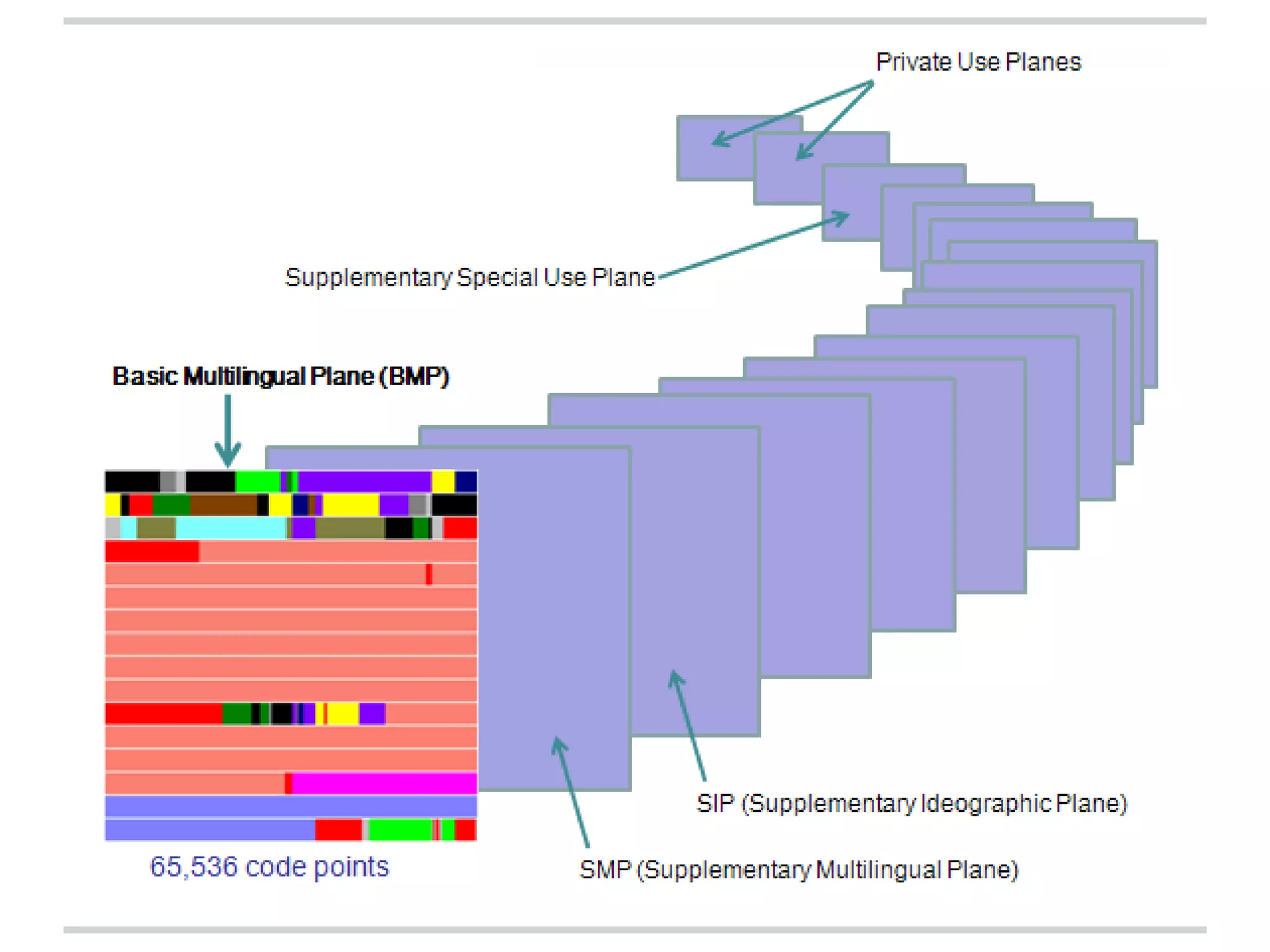

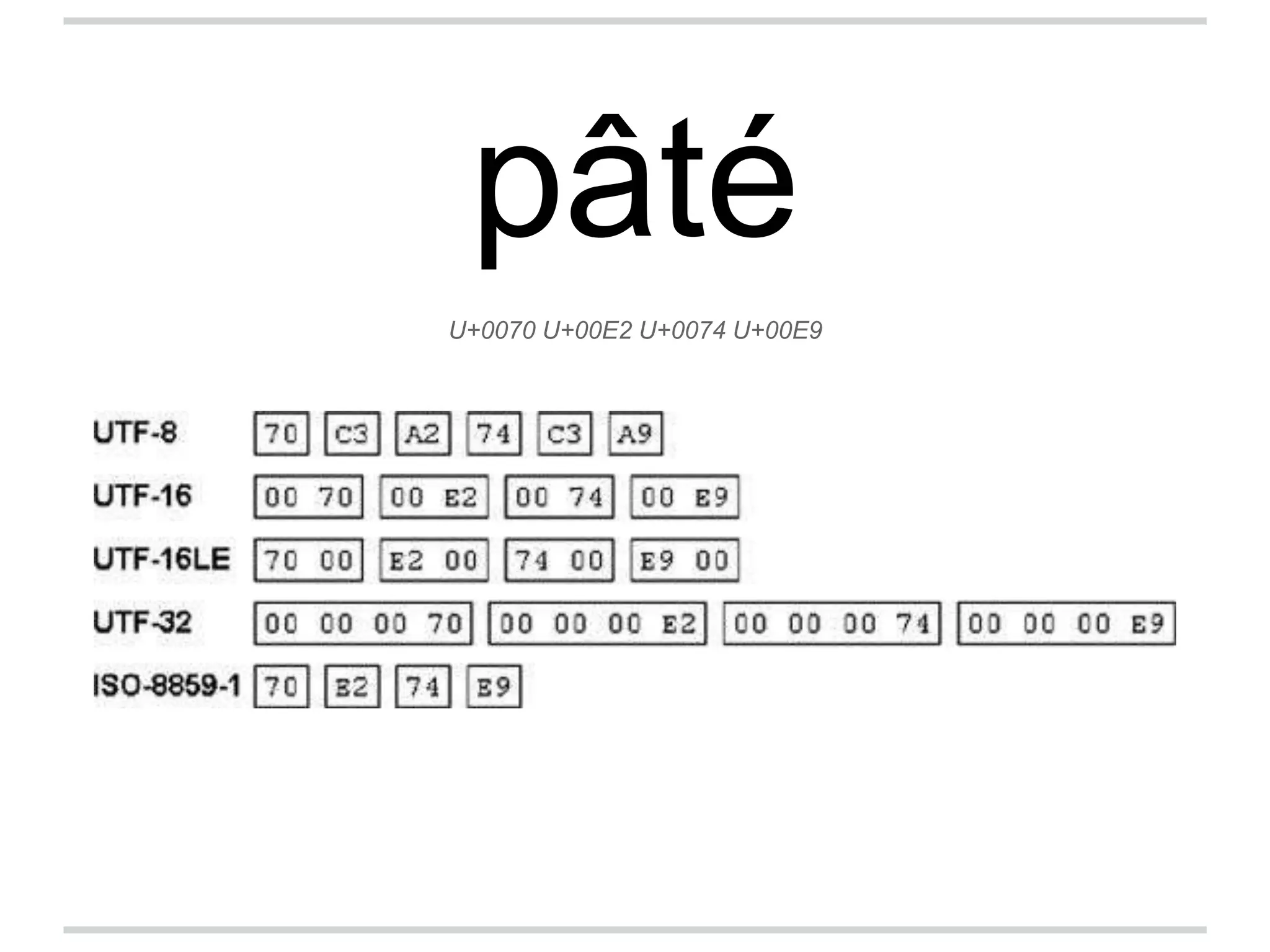





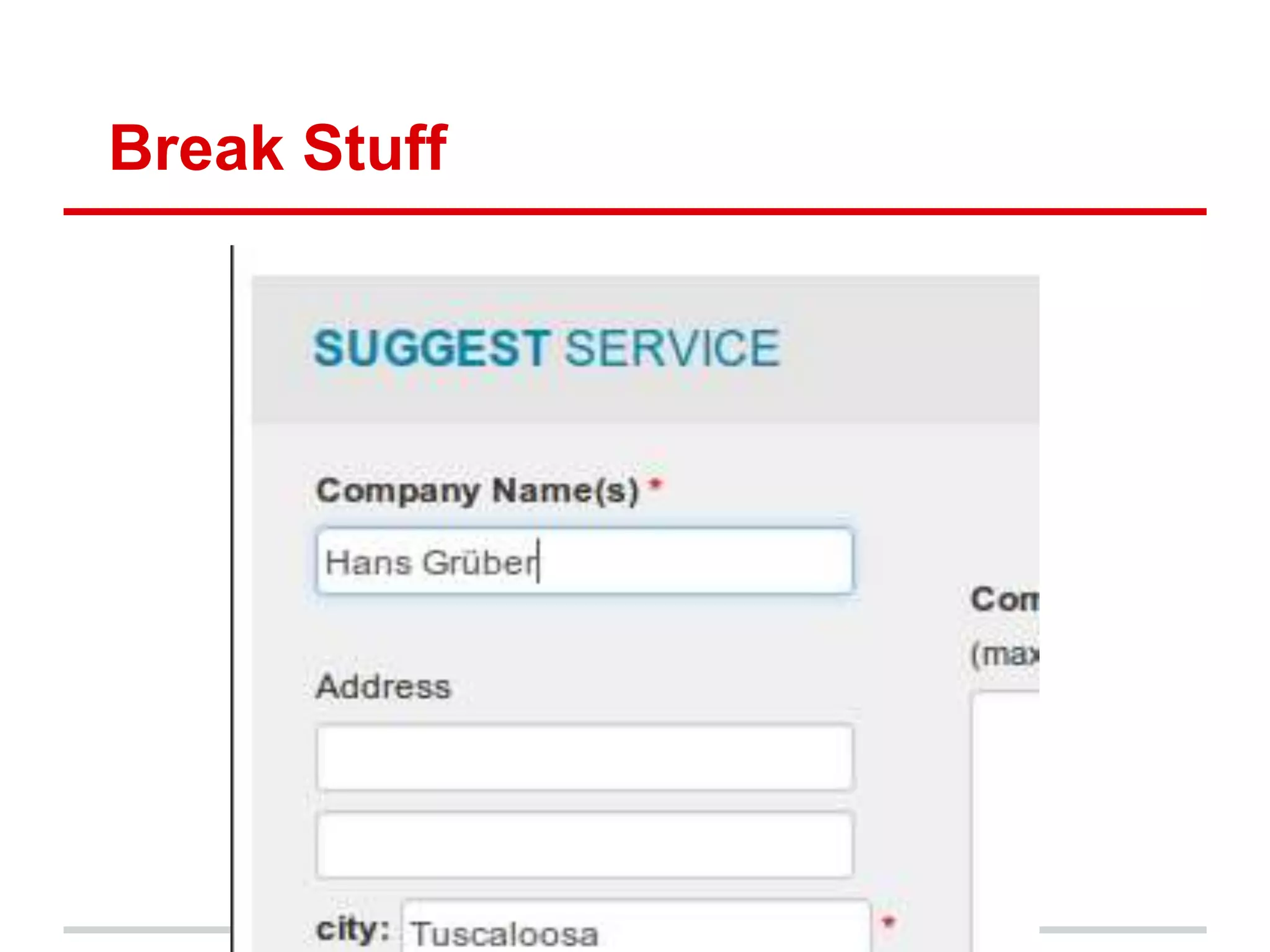
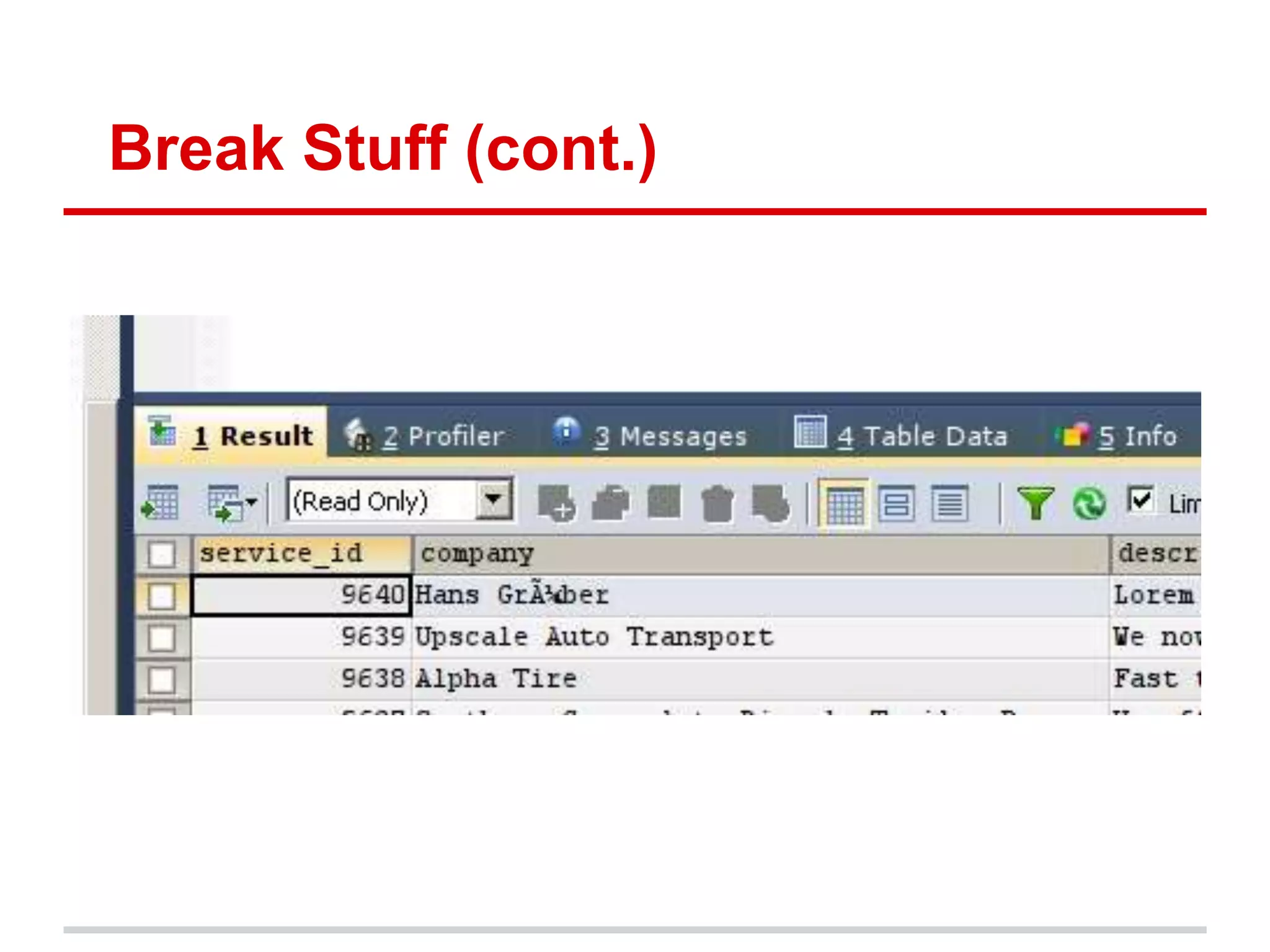


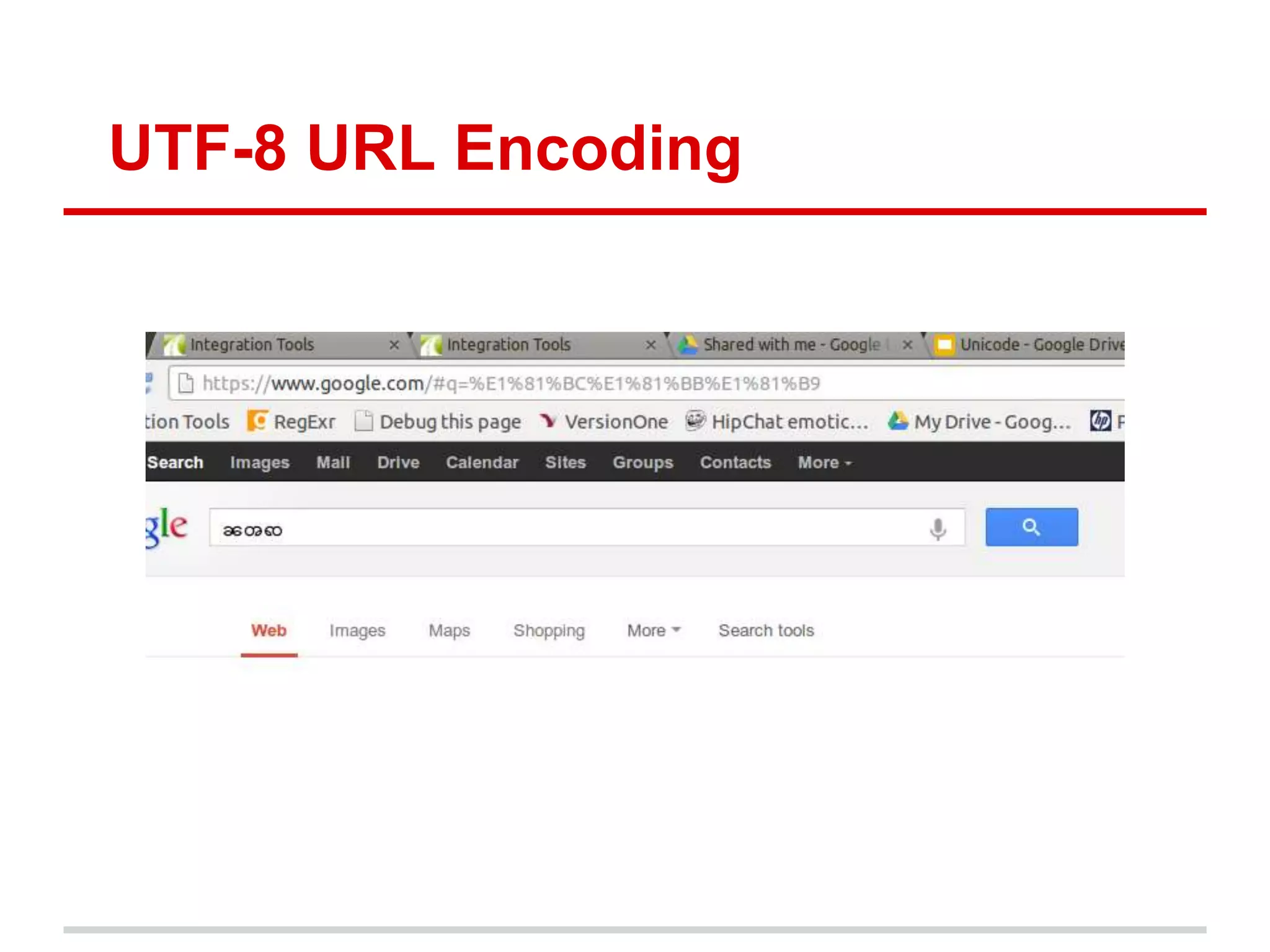





Character encodings map characters to binary representations using code points. Unicode is a widely adopted standard that assigns unique code points to characters. It is divided into planes with 65,536 code points each. UTF-8 is a common encoding format that uses variable-length octets to represent code points efficiently. While Unicode supports many languages, some criticize its complexity and that it does not include all possible scripts.

































![Introduction to Unicode (that you never got) [PyLadies Dublin, August 2023]](https://cdn.slidesharecdn.com/ss_thumbnails/pyladiesintrotounicode-230816084847-1a5f20a1-thumbnail.jpg?width=640&height=640&fit=bounds)

































