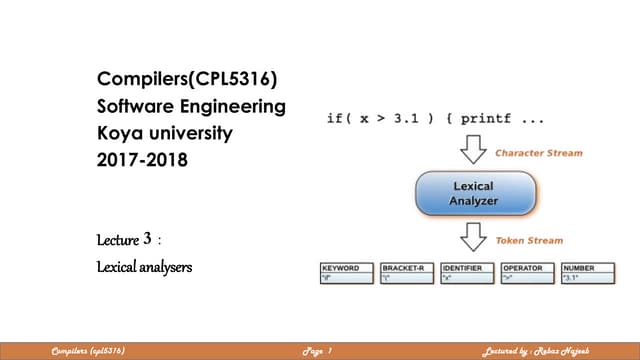
Sudeepta Mishra gave a technical seminar presentation on data compression techniques. They discussed lossless compression techniques like dictionary coders, entropy encoding, and run-length encoding. They focused on the LZW compression algorithm, providing examples of how it works for both compression and decompression. LZW is an adaptive dictionary coding technique that builds the dictionary dynamically and does not require transmitting the dictionary.
![NationalInstituteofScienceandTechnology
[1]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
A Review of Data Compression Techniques
Presented
by
Sudeepta Mishra
Roll# CS200117052
At
NIST,Berhampur
Under the guidance of
Mr. Rowdra Ghatak](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-1-2048.jpg)
![NationalInstituteofScienceandTechnology
[2]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
Introduction
• Data compression is the process of encoding data so
that it takes less storage space or less transmission time
than it would if it were not compressed.
• Compression is possible because most real-world data
is very redundant](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-2-2048.jpg)
![NationalInstituteofScienceandTechnology
[3]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
Different Compression Techniques
• Mainly two types of data Compression techniques are
there.
– Loss less Compression.
Useful in spreadsheets, text, executable program
Compression.
– Lossy less Compression.
Compression of images, movies and sounds.](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-3-2048.jpg)
![NationalInstituteofScienceandTechnology
[4]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
Types of Loss less data Compression
• Dictionary coders.
– Zip (file format).
– Lempel Ziv.
• Entropy encoding.
– Huffman coding (simple entropy coding).
• Run-length encoding.](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-4-2048.jpg)
![NationalInstituteofScienceandTechnology
[5]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
Dictionary-Based Compression
• Dictionary-based algorithms do not encode
single symbols as variable-length bit strings;
they encode variable-length strings of symbols
as single tokens.
• The tokens form an index into a phrase
dictionary.
• If the tokens are smaller than the phrases
they replace, compression occurs.](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-5-2048.jpg)
![NationalInstituteofScienceandTechnology
[6]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
Types of Dictionary
• Static Dictionary.
• Semi-Adaptive Dictionary.
• Adaptive Dictionary.
– Lempel Ziv algorithms belong to this category of
dictionary coders. The dictionary is being built in a
single pass, while at the same time encoding the data.
– The decoder can build up the dictionary in the same
way as the encoder while decompressing the data.](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-6-2048.jpg)
![NationalInstituteofScienceandTechnology
[7]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
• Using a English Dictionary the string:
“A good example of how dictionary based compression works”
• Gives : 1/1 822/3 674/4 1343/60 928/75 550/32 173/46 421/2
• Using the dictionary as lookup table, each word is coded as
x/y, where, x gives the page no. and y gives the number of
the word on that page. If the dictionary has 2,200 pages
with less than 256 entries per page: Therefore x requires 12
bits and y requires 8 bits, i.e., 20 bits per word (2.5 bytes per
word). Using ASCII coding the above string requires 48
bytes, whereas our encoding requires only 20 (<-2.5 * 8)
bytes: 50% compression.
Dictionary-Based Compression: Example](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-7-2048.jpg)
![NationalInstituteofScienceandTechnology
[8]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
Lempel Ziv
• It is a family of algorithms, stemming from the two
algorithms proposed by Jacob Ziv and Abraham Lempel in
their landmark papers in 1977 and 1978.
LZ77 LZ78
LZR
LZHLZSS LZB
LZFG
LZC LZT LZMW
LZW
LZJ](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-8-2048.jpg)
![NationalInstituteofScienceandTechnology
[9]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
LZW Algorithm
• It is An improved version of LZ78 algorithm.
• Published by Terry Welch in 1984.
• A dictionary that is indexed by “codes” is used.
The dictionary is assumed to be initialized with
256 entries (indexed with ASCII codes 0 through
255) representing the ASCII table.](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-9-2048.jpg)
![NationalInstituteofScienceandTechnology
[10]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Compression)
W = NIL;
while (there is input){
K = next symbol from input;
if (WK exists in the dictionary) {
W = WK;
} else {
output (index(W));
add WK to the dictionary;
W = K;
}
}](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-10-2048.jpg)
![NationalInstituteofScienceandTechnology
[11]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Compression) Flow Chart
START
W= NULL
IS EOF
?
K=NEXT INPUT
IS WK
FOUND?
W=WK
OUTPUT INDEX OF W
ADD WK TO DICTIONARY
STOP
W=K
YES
NO
YES
NO](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-11-2048.jpg)
![NationalInstituteofScienceandTechnology
[12]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Compression) Example
• Input string is
• The Initial
Dictionary
contains symbols
like
a, b, c, d with their
index values as 1, 2,
3, 4 respectively.
• Now the input string
is read from left to
right. Starting from
a.
a b d c a d a c
a 1
b 2
c 3
d 4](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-12-2048.jpg)
![NationalInstituteofScienceandTechnology
[13]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Compression) Example
• W = Null
• K = a
• WK = a
In the dictionary.
a b d c a d a c
a 1
b 2
c 3
d 4
K](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-13-2048.jpg)
![NationalInstituteofScienceandTechnology
[14]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Compression) Example
• K = b.
• WK = ab
is not in the dictionary.
• Add WK to
dictionary
• Output code for a.
• Set W = b
a b d c a d a c
K
1
ab 5a 1
b 2
c 3
d 4](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-14-2048.jpg)
![NationalInstituteofScienceandTechnology
[15]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Compression) Example
• K = d
• WK = bd
Not in the dictionary.
Add bd to dictionary.
• Output code b
• Set W = d
a b d c a d a c
1
K
2
ab 5a 1
b 2
c 3
d 4
bd 6](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-15-2048.jpg)
![NationalInstituteofScienceandTechnology
[16]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Compression) Example
• K = a
• WK = da
not in the dictionary.
• Add it to dictionary.
• Output code d
• Set W = a
a b d a b d a c
1
K
2 4
ab 5a 1
b 2
c 3
d 4
bd 6
da 7](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-16-2048.jpg)
![NationalInstituteofScienceandTechnology
[17]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Compression) Example
• K = b
• WK = ab
It is in the dictionary.
a b d a b d a c
1
K
2 4
ab 5a 1
b 2
c 3
d 4
bd 6
da 7](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-17-2048.jpg)
![NationalInstituteofScienceandTechnology
[18]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Compression) Example
• K = d
• WK = abd
Not in the dictionary.
• Add W to the
dictionary.
• Output code for W.
• Set W = d
a b d a b d a c
1
K
2 4 5
ab 5a 1
b 2
c 3
d 4
bd 6
da 7
abd 8](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-18-2048.jpg)
![NationalInstituteofScienceandTechnology
[19]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Compression) Example
• K = a
• WK = da
In the dictionary.
a b d a b d a c
1
K
2 4 5
ab 5a 1
b 2
c 3
d 4
bd 6
da 7
abd 8](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-19-2048.jpg)
![NationalInstituteofScienceandTechnology
[20]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Compression) Example
• K = c
• WK = dac
Not in the dictionary.
• Add WK to the
dictionary.
• Output code for W.
• Set W = c
• No input left so
output code for W.
a b d a b d a c
1
K
2 4 5
ab 5a 1
b 2
c 3
d 4
bd 6
da 7
abd 8
7
dac 9](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-20-2048.jpg)
![NationalInstituteofScienceandTechnology
[21]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Compression) Example
• The final output
string is
1 2 4 5 7 3
• Stop.
cadbadba
1
K
2 4 5
5ab
4d
3c
2b
1a
6bd
7da
8abd
7
9dac
3](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-21-2048.jpg)
![NationalInstituteofScienceandTechnology
[22]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
LZW Decompression Algorithm
read a character k;
output k;
w = k;
while ( read a character k )
/* k could be a character or a code. */
{ entry = dictionary entry for k;
output entry;
add w + entry[0] to dictionary;
w = entry; }](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-22-2048.jpg)
![NationalInstituteofScienceandTechnology
[23]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
LZW Decompression Algorithm Flow Chart
START
Output K
IS EOF
?
K=NEXT INPUT
ENTRY=DICTIONARY INDEX (K)
ADD W+ENTRY[0] TO DICTIONARY
STOP
W=ENTRY
K=INPUT
W=K
YES
NO
Output ENTRY](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-23-2048.jpg)
![NationalInstituteofScienceandTechnology
[24]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Decompression) Example
• K = 1
• Out put K (i.e. a)
• W = K
1
K
2 4 5
4d
3c
2b
1a
7 3
a](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-24-2048.jpg)
![NationalInstituteofScienceandTechnology
[25]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Decompression) Example
• K = 2
• entry = b
• Output entry
• Add W + entry[0] to
dictionary
• W = entry[0] (i.e. b)
1
K
2 4 5
4d
3c
2b
1a
7 3
a b
5ab](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-25-2048.jpg)
![NationalInstituteofScienceandTechnology
[26]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Decompression) Example
• K = 4
• entry = d
• Output entry
• Add W + entry[0] to
dictionary
• W = entry[0] (i.e. d)
1
K
2 4 5
4d
3c
2b
1a
7 3
a b
5ab
6bd
d](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-26-2048.jpg)
![NationalInstituteofScienceandTechnology
[27]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Decompression) Example
• K = 5
• entry = ab
• Output entry
• Add W + entry[0] to
dictionary
• W = entry[0] (i.e. a)
1
K
2 4 5
4d
3c
2b
1a
7 3
a b
5ab
6bd
d a b
7da](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-27-2048.jpg)
![NationalInstituteofScienceandTechnology
[28]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Decompression) Example
• K = 7
• entry = da
• Output entry
• Add W + entry[0] to
dictionary
• W = entry[0] (i.e. d)
1
K
2 4 5
4d
3c
2b
1a
7 3
a b
5ab
6bd
d a b
7da
d a
8abd](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-28-2048.jpg)
![NationalInstituteofScienceandTechnology
[29]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
The LZW Algorithm (Decompression) Example
• K = 3
• entry = c
• Output entry
• Add W + entry[0] to
dictionary
• W = entry[0] (i.e. c)
1
K
2 4 5
4d
3c
2b
1a
7 3
a b
5ab
6bd
d a b
7da
d a
8abd
c
9dac](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-29-2048.jpg)
![NationalInstituteofScienceandTechnology
[30]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
Advantages
• As LZW is adaptive dictionary coding no need to
transfer the dictionary explicitly.
• It will be created at the decoder side.
• LZW can be made really fast, it grabs a fixed number
of bits from input, so bit parsing is very easy, and table
look up is automatic.](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-30-2048.jpg)
![NationalInstituteofScienceandTechnology
[31]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
Problems with the encoder
• What if we run out of space?
– Keep track of unused entries and use LRU (Last
Recently Used).
– Monitor compression performance and flush
dictionary when performance is poor.](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-31-2048.jpg)
![NationalInstituteofScienceandTechnology
[32]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
Conclusion
• LZW has given new dimensions for the development of
new compression techniques.
• It has been implemented in well known compression
format like Acrobat PDF and many other types of
compression packages.
• In combination with other compression techniques
many other different compression techniques are
developed like LZMS.](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-32-2048.jpg)
![NationalInstituteofScienceandTechnology
[33]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
REFERENCES
[1] http://www.bambooweb.com/articles/d/a/Data_Compression.html
[2] http://tuxtina.de/files/seminar/LempelZivReport.pdf
[3] BELL, T. C., CLEARY, J. G., AND WITTEN, I. H. Text
Compression. Prentice Hall, Upper Sadle River, NJ, 1990.
[4] http://www.cs.cf.ac.uk/Dave/Multimedia/node214.html
[5] http://download.cdsoft.co.uk/tutorials/rlecompression/Run-
Length Encoding (RLE) Tutorial.htm
[6] David Salomon, Data Compression The Complete Reference,
Second Edition. Springer-Verlac, New York, Inc, 2001 reprint.
[7] http://www.programmersheaven.com/2/Art_Huffman_p1.htm
[8] http://www.programmersheaven.com/2/Art_Huffman_p2.htm
[9] Khalid Sayood, Introduction to Data Compression Second
Edition, Chapter 5, pp. 137-157, Harcourt India Private Limited.](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-33-2048.jpg)
![NationalInstituteofScienceandTechnology
[34]
Technical Seminar Presentation 2005
Sudeepta Mishra
NationalInstituteofScienceandTechnology
Sudeepta Mishra CS200117052
Thank You](https://image.slidesharecdn.com/datacompressiontech-cs-130829105325-phpapp01/75/Data-compression-tech-cs-34-2048.jpg)