




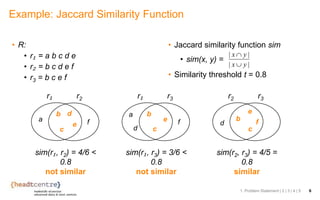





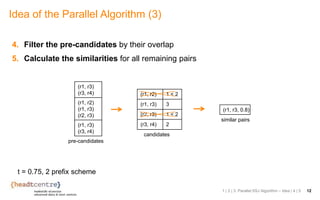
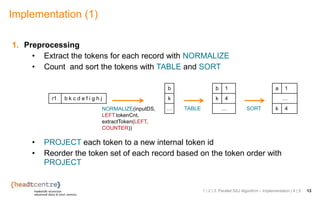



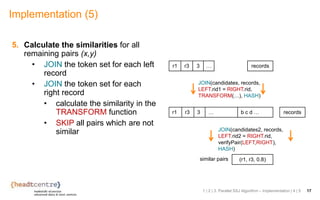


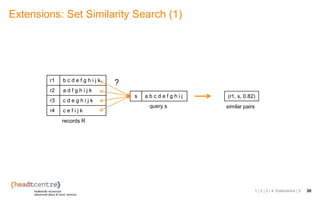


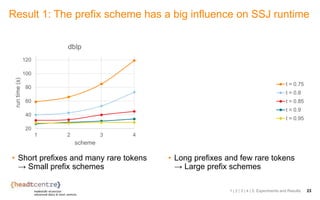

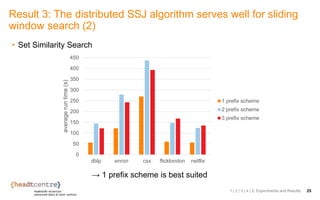



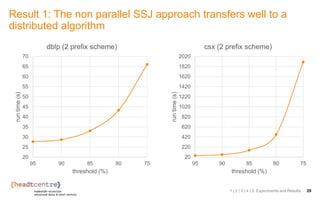

The document discusses the challenges and solutions related to identifying similar pairs of documents in large datasets, particularly through parallel set similarity join (SSJ) algorithms. It presents a filter-verification framework to efficiently compute similarities by reducing the number of pairs to evaluate using techniques like prefix and length filtering. The document also showcases various experiments demonstrating the performance of different algorithms and datasets, highlighting the effectiveness of the proposed methods.










































































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)
