Regression
In the simplelinear regression model:
y = b0 + b1x + u
• we typically refer to y as the
• Dependent Variable, or
• Left-Hand Side Variable, or
• Explained Variable, or
• Regressand
• we typically refer to x as the
• Independent Variable, or
• Right-Hand Side Variable, or
• Explanatory Variable, or
• Regressor, or
• Covariate, or
• Control Variables
x
y
x
y
1
0
1
0
ˆ
ˆ
or
,
ˆ
ˆ
4.
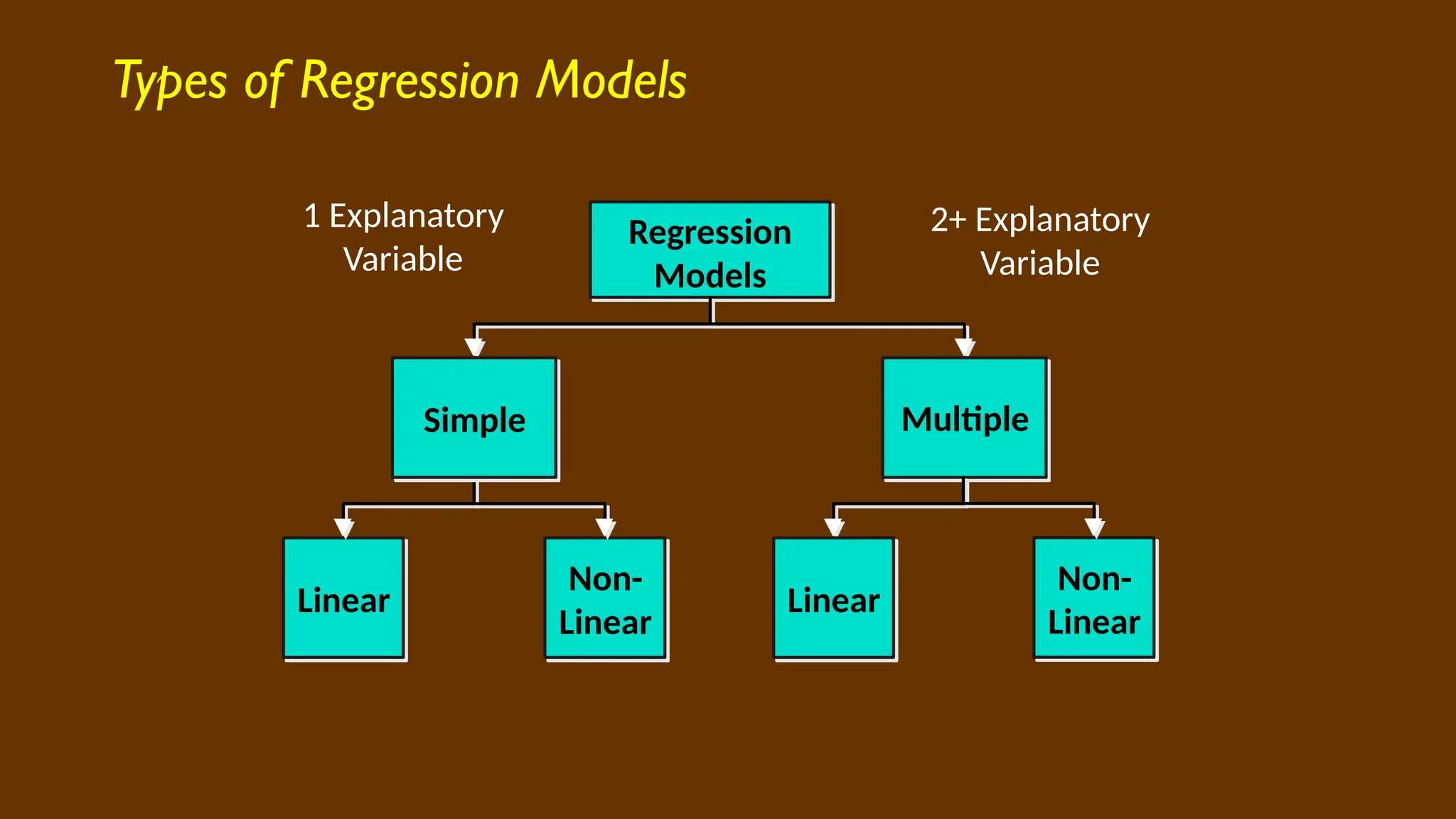
Types of RegressionModels
Regression
Models
Linear
Non-
Linear
Simple Multiple
Linear
Non-
Linear
1 Explanatory
Variable
2+ Explanatory
Variable
5.
Asumsi
• Regresi OLSdiharapkan dapat menghasilkan koefisien yang “BLUE” (Best Linear
Unbiased Estimate).
• Best berarti memiliki varians error terkecil. Linear artinya variabel independen merupakan
fungsi linear dari variabel independen.
• Unbiased berarti estimasi koefisien tidak lebih besar atau lebih kecil secara sistematis dari
nilai yang sebenarnya.
• Syarat untuk mendapatkan estimasi yang BLUE adalah:
1. Tidak ada kesalahan dalam pengukuran variabel independen (measurement error)
2. Spesifikasi regresi tepat, dalam arti bentuk fungsionalnya (linear/kuadratik/logaritmik) dan
tidak ada omitted variable (specification error)
3. Tidak ada variabel independen yang memiliki korelasi sempurna dengan variabel independen
yang lain (multicollinearity)
4. Varians dari error tetap dan tidak berkorelasi dengan error yang lain (heteroscedasticity)
5. Variabel independen adalah exogenous (endogeneity)
6.
Diagnostics
1. Measurement error
2.Specification error
3. Multicollinearity
4. Heteroscedasticity
5. Endogeneity
6. Nonnormality
Residual yang berdistribusi normal cukup penting
OLS, tetapi bukan merupakan syarat mutlak.
Standar error tergantung dari normalitas residual.
Dengan jumlah observasi yang cukup, koefisien
masih dapat terdistribusi normal, meskipun error
tidak terdistribusi normal.
For Time-Series:
• Measurement error
• Stationarity of variables
• Specification error
• Multicollinearity
• Heteroscedasticity
• Endogeneity
• Nonnormality
• Stationarity of residual
• Residual autocorrelation
7.
Regression Diagnostics withStata
Background
Linear regression analysis generates the best equation to describe the relationship between
one dependent variable and one or more independent variables, but it depends on several
assumptions about the data. This chapter discusses ways to test these assumptions and
remedy the problem if it is found.
Measurement
error
Assumption: Regression analysis assumes the independent variables are measured without
error.
Diagnosis: sum…detail, predict…resid, predict…cooksd
Remedies: Minimize errors in data collection. Try alternative indicators. Take into account in
interpretation.
Specification
error
Assumption: Functional form is correct and all relevant independent variables are included.
Diagnosis: rvpplot, rvfplot, ovtest, test significance of new variables, quadratic terms, and
interaction terms
Remedy: Include new variables, quadratic terms, or interaction terms if statistically
significant.
Multicollinearity
Assumption: Independent variables are not highly correlated with one another.
Diagnosis: correl, vif test
Remedy: Test joint significance of correlated variables and explain in text.
8.
Heteroscedasticity
Assumption: Variance ofresiduals is constant.
Diagnosis: rvpplot, rvfplot, hettest
Remedy: vce(robust) option, generalized least squares
Nonnormality
Assumption: Residuals are normally distributed.
Diagnosis: sktest
Remedy: Transform variables, take into account in interpretation.
Endogeneity
Assumption: Independent variables are exogenous.
Diagnosis: Largely based on theory and experience rather than statistical tests
Remedy: Instrumental variables regression, panel data regression, and experimental
methods
9.
9
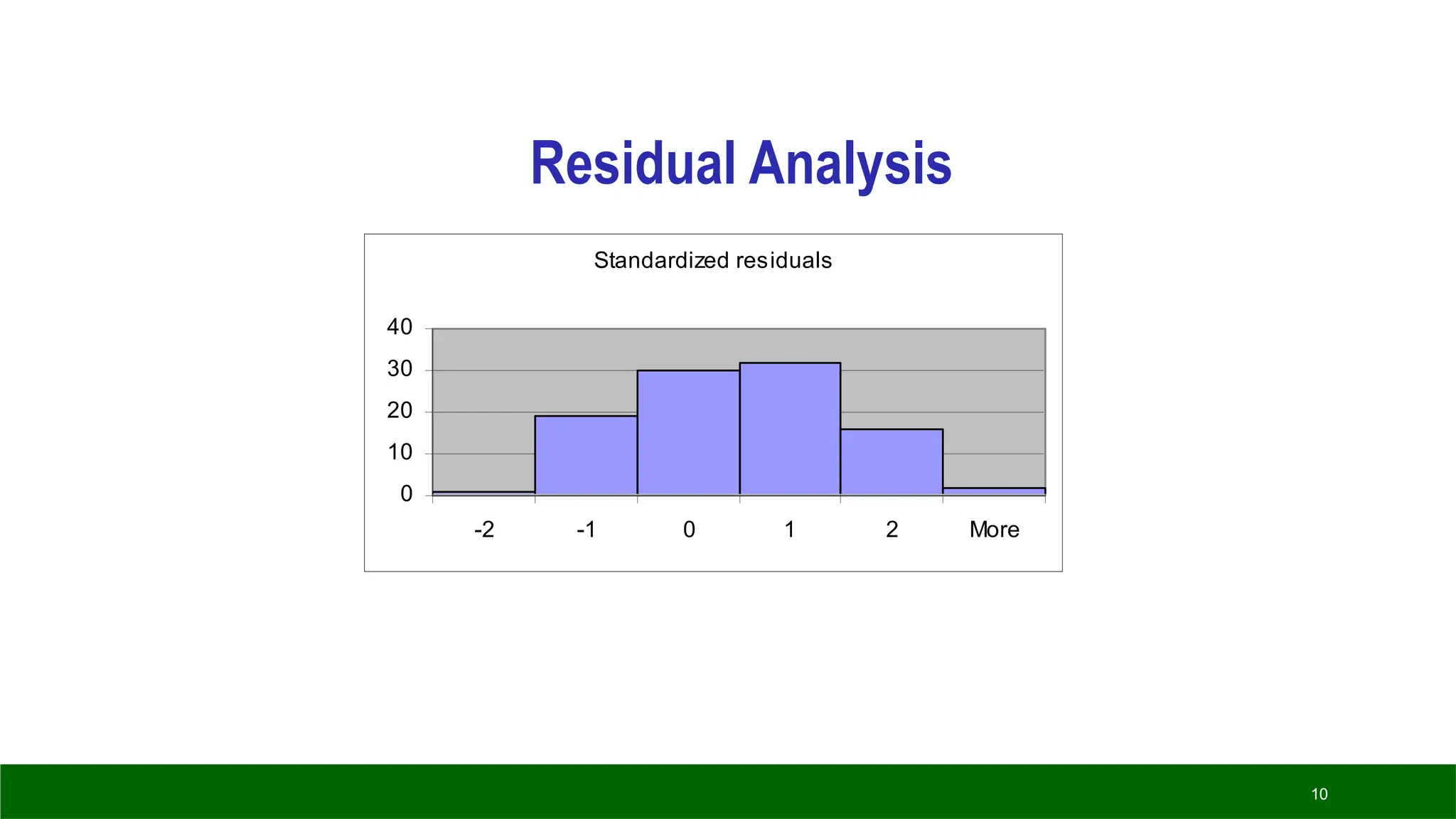
Residual Analysis
Examining theresiduals (or standardized
residuals), help detect violations of the
required conditions.
Example – continued:
◦ Nonnormality.
◦ Use Excel to obtain the standardized residual histogram.
◦ Examine the histogram and look for a bell shaped. diagram with a
mean close to zero.
11
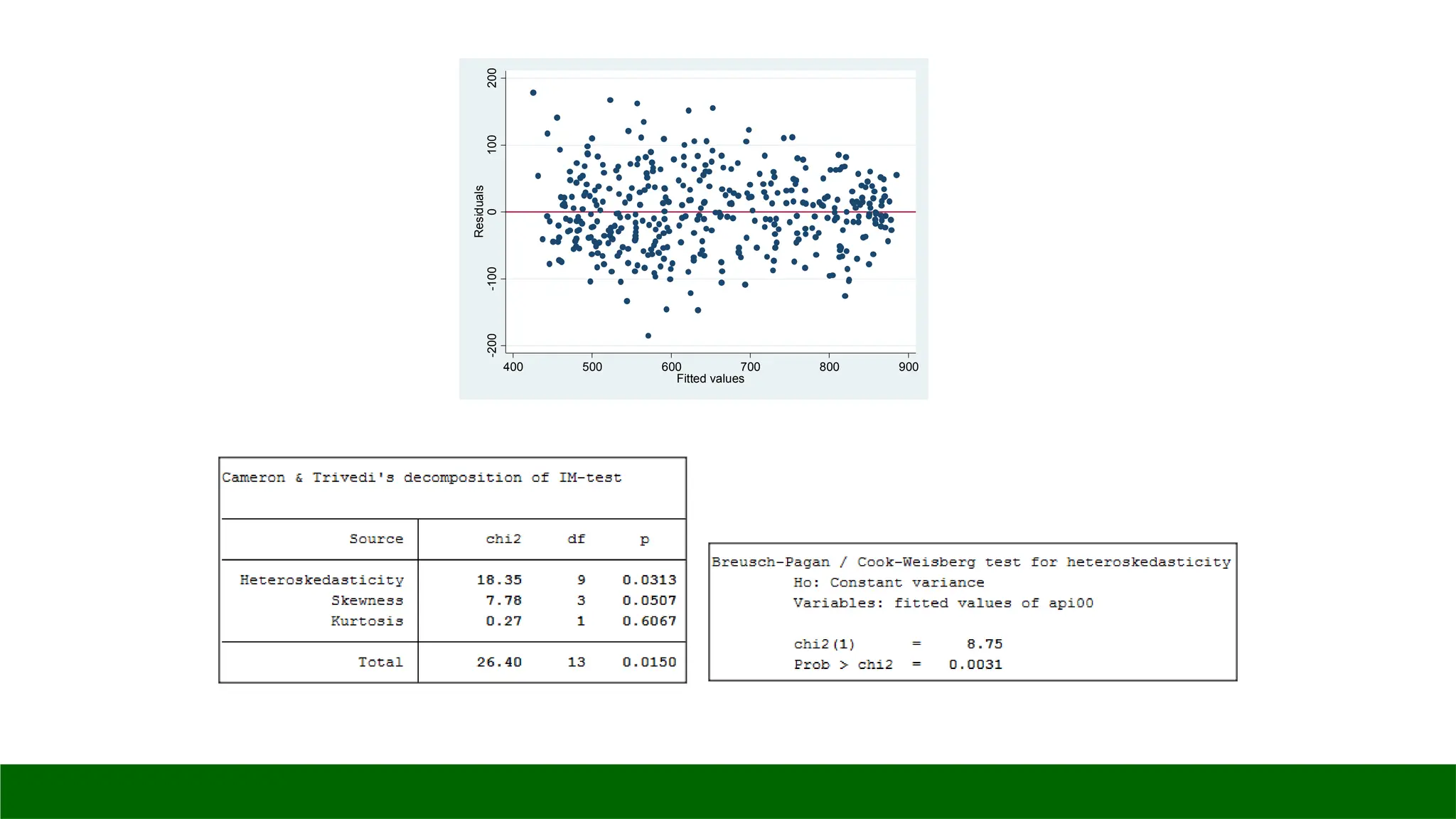
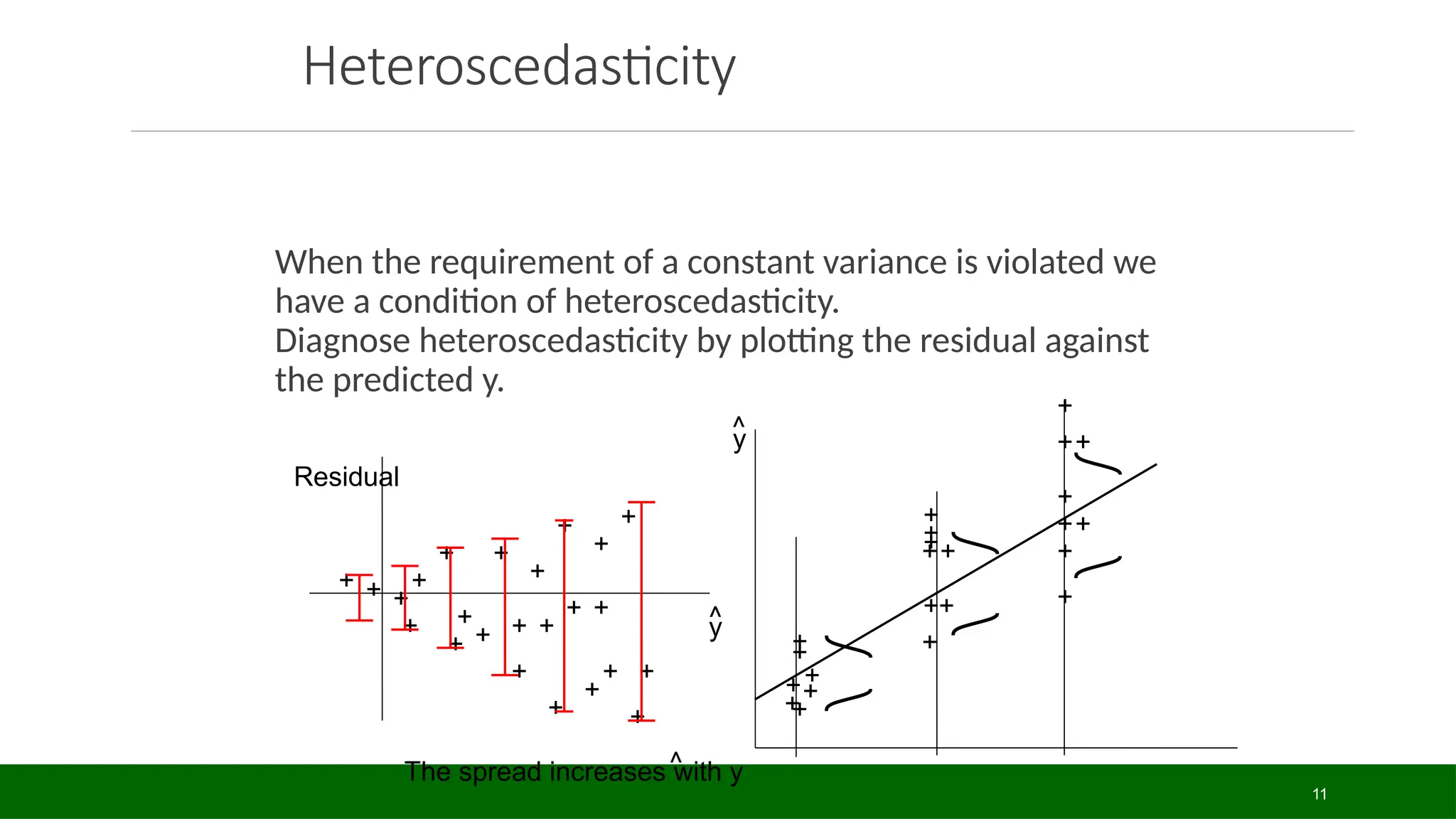
Heteroscedasticity
When the requirementof a constant variance is violated we
have a condition of heteroscedasticity.
Diagnose heteroscedasticity by plotting the residual against
the predicted y.
+ + +
+
+ +
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
The spread increases with y
^
y
^
Residual
^
y
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
12.
12
Homoscedasticity
When the requirementof a constant variance is not
violated we have a condition of homoscedasticity.
-1000
-500
0
500
1000
13500 14000 14500 15000 15500 16000
Predicted Price
Residuals
13.
13
Non Independence ofError Variables
◦ A time series is constituted if data were collected over
time.
◦ Examining the residuals over time, no pattern should
be observed if the errors are independent.
◦ When a pattern is detected, the errors are said to be
autocorrelated.
◦ Autocorrelation can be detected by graphing the
residuals against time.
14.
Detecting Unusual andInfluential Data
◦ predict: used to create predicted values, residuals, and measures of influence
◦ rvpplot: graphs a residual-versus-predictor plot
◦ rvfplot: graphs residual-versus-fitted plot
◦ lvr2plot: graphs a leverage-versus-squared-residual plot
◦ avplot: graphs an added-variable plot, a.k.a. partial regression plot
Tests for Normality of Residuals
◦ kdensity: produces kernel density plot with normal distribution overlayed
◦ pnorm: graphs a standardized normal probability (P-P) plot
◦ qnorm: plots the quantiles of varname against the quantiles of a normal distribution
◦ swilk: performs the Shapiro-Wilk W test for normality
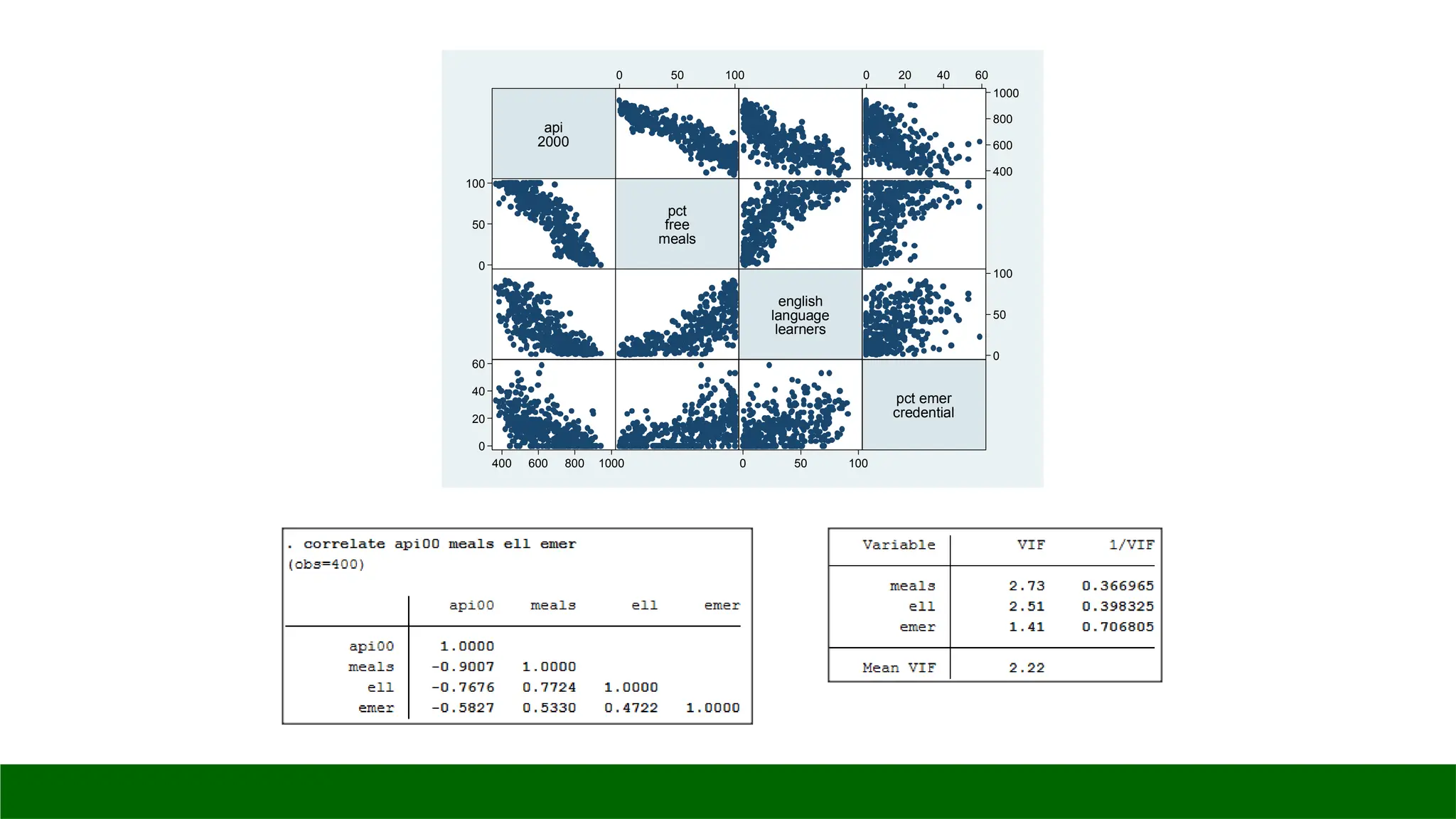
Tests for Multicollinearity
◦ correlate: displays the correlation matrix or covariance matrix for a group of variables
◦ vif: calculates the variance inflation factor for the independent variables in the linear model
Diagnostics 1
14
15.
Tests for Heteroscedasticity
◦rvfplot: graphs residual-versus-fitted plot
◦ estat imtest: Cameron & Trivedi's decomposition of IM-test
◦ estat hettest — performs Cook and Weisberg test for heteroscedasticity
Tests for Non-Linearity
◦ graph matrix: draws scatterplot matrices to examine the relationships among variables
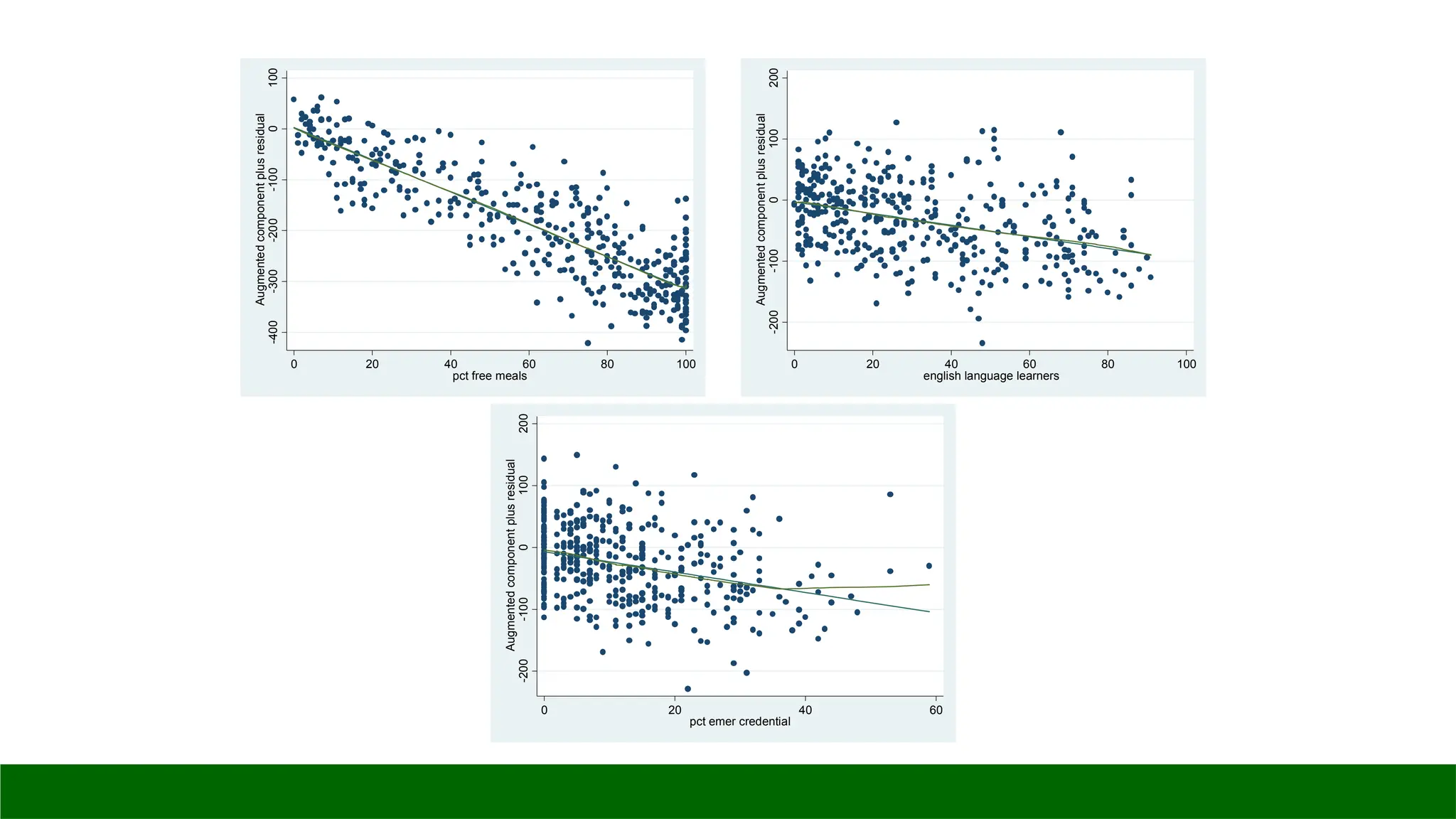
◦ acprplot: graphs an augmented component-plus-residual plot
◦ cprplot: graphs component-plus-residual plot, a.k.a. residual plot
Tests for Model Specification
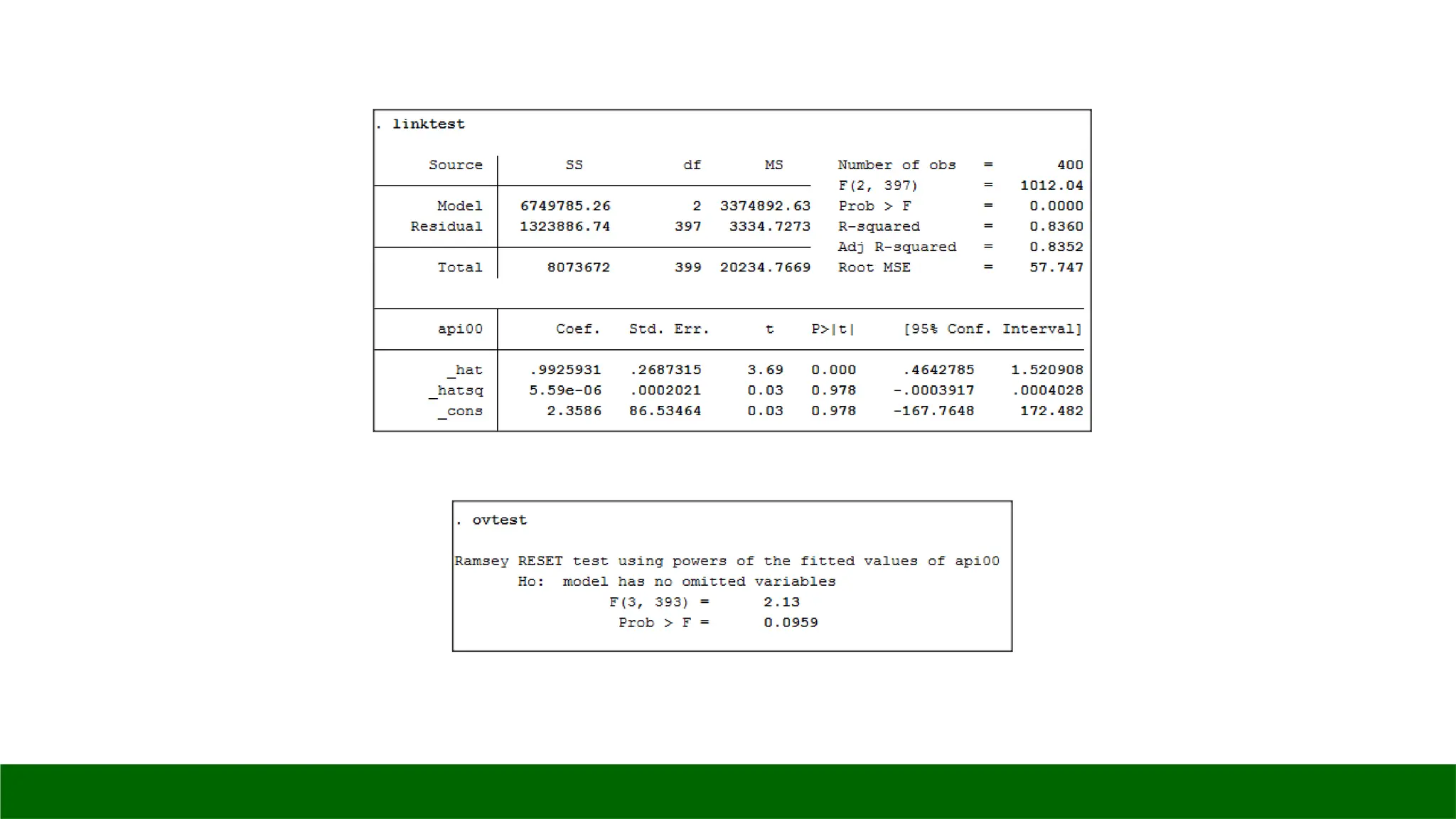
◦ linktest: performs a link test for model specification.
◦ ovtest: performs regression specification error test (RESET) for omitted variables
Issues of Independence of Residuals
◦ dwstat
Diagnostics 2
15
16.
Praktik
cd "C:BahanAjarMetode
PenelitianMetode Penelitian
2022-2023 GanjilPertemuan
10-11Data"
use elemapi2
*Uji Measurement
sum api00 meals ell emer
sum api00 meals ell emer,
detail
histogram api00
hitogram meals
histogram ell
histogram emer
*Regresi
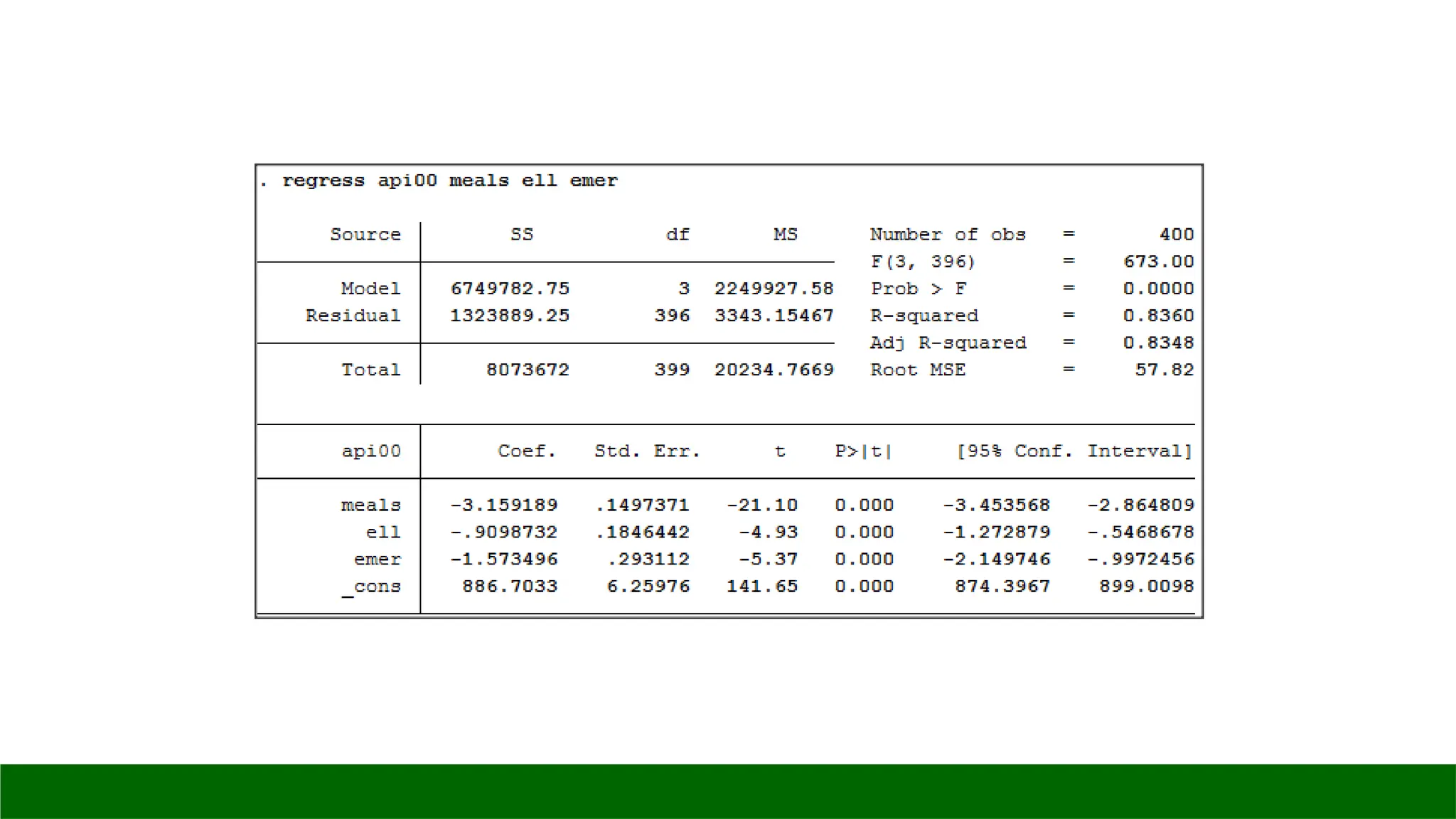
regress api00 meals ell emer
*1. Uji Measurement
predict cook, cooksd
browse if cook>1
predict r, resid
sum r, detail
*2. Uji Spesifikasi
graph matrix api00 meals ell
emer
rvfplot, yline(0)
rvpplot meals
rvpplot ell
acprplot meals, lowess
lsopts(bwidth(1))
acprplot ell, lowess
lsopts(bwidth(1))
acprplot emer, lowess
lsopts(bwidth(1))
linktest
estat ovtest
*3. Uji Multicollinearity
correlate api00 meals ell emer
estat vif
*4. Uji Heteroscedasticity
rvfplot, yline(0)
estat imtest
estat hettest
*5. Uji Endogeneity melalui
teori
*6. Uji Normalitas
kdensity r, normal
pnorm r
qnorm r
swilk r
sktest r
18.
0
.002
.004
.006
.008
Density
-200 -100 0100 200
Residuals
Kernel density estimate
Normal density
kernel = epanechnikov, bandwidth = 15.3934
Kernel density estimate
0.00
0.25
0.50
0.75
1.00
Normal
F[(r-m)/s]
0.00 0.25 0.50 0.75 1.00
Empirical P[i] = i/(N+1)
-200
-100
0
100
200
Residuals
-200 -100 0 100 200
Inverse Normal
Linear
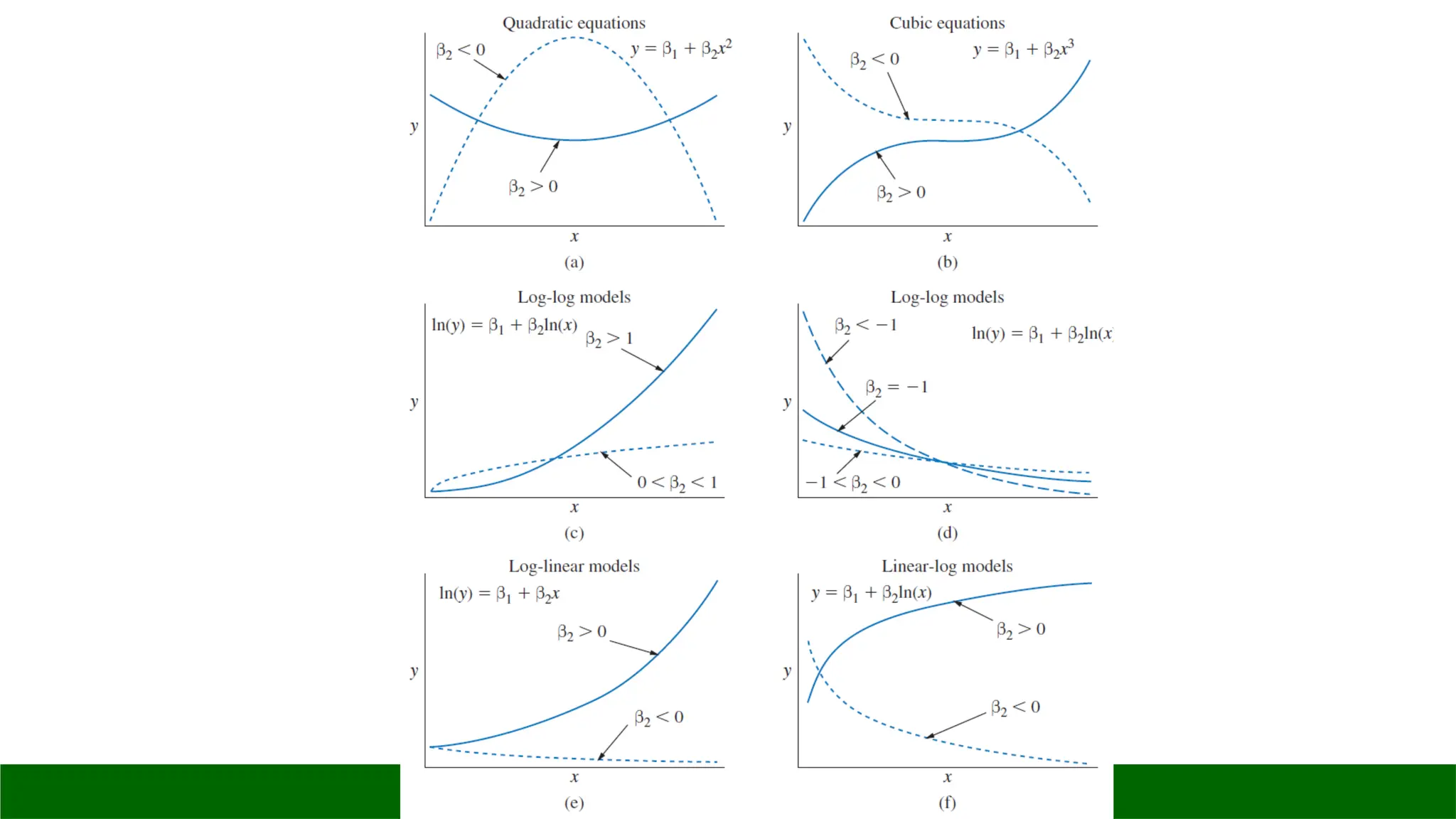
1 unit changein X leads to a β1 unit change in Y
linear-log
1% change in X leads to an (approximately) β1/100 unit change in Y
log-linear
1 unit change in X leads to an (approximately) 100β1% change in Y
log-log
1% change in X leads to an (approximately) β1% change in Y
Functional Form
23
26.
t-test and z-test
Thet-test can be understood as a statistical test which is used to compare and analyse whether the means of
the two population is different from one another or not when the standard deviation is not known. As
against, Z-test is a parametric test, which is applied when the standard deviation is known, to determine, if
the means of the two datasets differ from each other.
The t-test is based on Student’s t-distribution. On the contrary, z-test relies on the assumption that the
distribution of sample means is normal. Both student’s t-distribution and normal distribution appear alike, as
both are symmetrical and bell-shaped. However, they differ in the sense that in a t-distribution, there is less
space in the centre and more in the tails.
One of the important conditions for adopting t-test is that population variance is unknown. Conversely,
population variance should be known or assumed to be known in case of a z-test.
Z-test is used to when the sample size is large, i.e. n > 30, and t-test is appropriate when the size of the
sample is small, in the sense that n < 30.
Reference
• Sekaran, Bougie,2016, Research Methods for Business, 7E.
• Cooper, Schindler, 2014, Business Research Methods, 12E.
• Saunders, Lewis,Thornhill, 2016, Research Methods for Business Students, 7E
• Hamilton, 2013, Statistics with STATA ver 12
• Hill, Griffiths, Lim, 2011, Principles of Econometrics, 4E
• Huber, 2016, Introduction to Stata (ppt)
• Daniels, Minot, 2020, Intro to Statistics and Data Analysis using STATA
• https://www3.nd.edu/~rwilliam/stats/StataHighlights.html
• https://stats.idre.ucla.edu/stata/webbooks/reg/
• https://stats.oarc.ucla.edu/stata/webbooks/reg/chapter1/regressionwith-statachapter-
1-simple-and-multiple-regression/
29.
Latihan
Anda diminta memberikanrekomendasi pada toko Andy untuk meningkatkan
penjualannya.Variabel yang berhubungan dengan penjualan (sales) adalah harga
(price) dan promosi (advert). Gunakan file andy.dta.
1. Bagaimana hubungan antara penjualan dengan harga dan promosi?
2. Apakah promosi akan meningkatkan penjualan?
3. Apakah promosi akan menguntungkan perusahaan? (Apakah kenaikan belanja
iklan akan membawa kenaikan pendapatan penjualan yang cukup untuk menutup
kenaikan biaya iklan)
4. Penasihat pemasaran mengklaim bahwa menurunkan harga sebesar 20 sen akan
lebih efektif untuk meningkatkan pendapatan penjualan daripada meningkatkan
pengeluaran iklan sebesar $500.













![0
.002
.004
.006
.008
Density
-200 -100 0 100 200
Residuals
Kernel density estimate
Normal density
kernel = epanechnikov, bandwidth = 15.3934
Kernel density estimate
0.00
0.25
0.50
0.75
1.00
Normal
F[(r-m)/s]
0.00 0.25 0.50 0.75 1.00
Empirical P[i] = i/(N+1)
-200
-100
0
100
200
Residuals
-200 -100 0 100 200
Inverse Normal](https://image.slidesharecdn.com/11-250601064130-18583fad/75/11-2-Quantitative-Data-Analysis-Regression-pptx-18-2048.jpg)